You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
146 lines
7.1 KiB
146 lines
7.1 KiB
📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
|
|
UPDATED 25 September 2022.
|
|
|
|
|
|
## Before You Start
|
|
|
|
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
|
|
|
```bash
|
|
git clone https://github.com/ultralytics/yolov5 # clone
|
|
cd yolov5
|
|
pip install -r requirements.txt # install
|
|
```
|
|
|
|
## Freeze Backbone
|
|
|
|
All layers that match the train.py `freeze` list in train.py will be frozen by setting their gradients to zero before training starts.
|
|
```python
|
|
# Freeze
|
|
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
|
|
for k, v in model.named_parameters():
|
|
v.requires_grad = True # train all layers
|
|
if any(x in k for x in freeze):
|
|
print(f'freezing {k}')
|
|
v.requires_grad = False
|
|
```
|
|
|
|
To see a list of module names:
|
|
```python
|
|
for k, v in model.named_parameters():
|
|
print(k)
|
|
|
|
# Output
|
|
model.0.conv.conv.weight
|
|
model.0.conv.bn.weight
|
|
model.0.conv.bn.bias
|
|
model.1.conv.weight
|
|
model.1.bn.weight
|
|
model.1.bn.bias
|
|
model.2.cv1.conv.weight
|
|
model.2.cv1.bn.weight
|
|
...
|
|
model.23.m.0.cv2.bn.weight
|
|
model.23.m.0.cv2.bn.bias
|
|
model.24.m.0.weight
|
|
model.24.m.0.bias
|
|
model.24.m.1.weight
|
|
model.24.m.1.bias
|
|
model.24.m.2.weight
|
|
model.24.m.2.bias
|
|
```
|
|
|
|
Looking at the model architecture we can see that the model backbone is layers 0-9:
|
|
```yaml
|
|
# YOLOv5 backbone
|
|
backbone:
|
|
# [from, number, module, args]
|
|
[[-1, 1, Focus, [64, 3]], # 0-P1/2
|
|
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
|
|
[-1, 3, BottleneckCSP, [128]],
|
|
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
|
|
[-1, 9, BottleneckCSP, [256]],
|
|
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
|
|
[-1, 9, BottleneckCSP, [512]],
|
|
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
|
|
[-1, 1, SPP, [1024, [5, 9, 13]]],
|
|
[-1, 3, BottleneckCSP, [1024, False]], # 9
|
|
]
|
|
|
|
# YOLOv5 head
|
|
head:
|
|
[[-1, 1, Conv, [512, 1, 1]],
|
|
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
|
[[-1, 6], 1, Concat, [1]], # cat backbone P4
|
|
[-1, 3, BottleneckCSP, [512, False]], # 13
|
|
|
|
[-1, 1, Conv, [256, 1, 1]],
|
|
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
|
|
[[-1, 4], 1, Concat, [1]], # cat backbone P3
|
|
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
|
|
|
|
[-1, 1, Conv, [256, 3, 2]],
|
|
[[-1, 14], 1, Concat, [1]], # cat head P4
|
|
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
|
|
|
|
[-1, 1, Conv, [512, 3, 2]],
|
|
[[-1, 10], 1, Concat, [1]], # cat head P5
|
|
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
|
|
|
|
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
|
|
]
|
|
```
|
|
|
|
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
|
|
```bash
|
|
python train.py --freeze 10
|
|
```
|
|
|
|
## Freeze All Layers
|
|
|
|
To freeze the full model except for the final output convolution layers in Detect(), we set freeze list to contain all modules with 'model.0.' - 'model.23.' in their names:
|
|
```bash
|
|
python train.py --freeze 24
|
|
```
|
|
|
|
## Results
|
|
|
|
We train YOLOv5m on VOC on both of the above scenarios, along with a default model (no freezing), starting from the official COCO pretrained `--weights yolov5m.pt`:
|
|
```python
|
|
train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
|
|
```
|
|
|
|
### Accuracy Comparison
|
|
|
|
The results show that freezing speeds up training, but reduces final accuracy slightly.
|
|
|
|
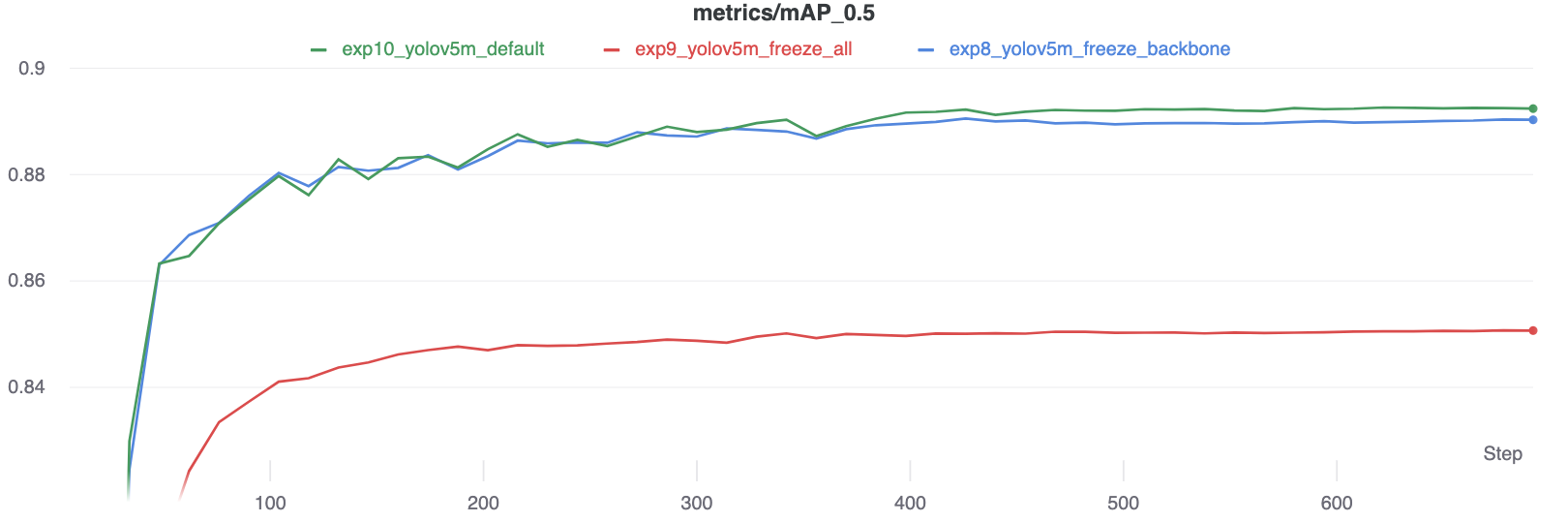
|
|
|
|
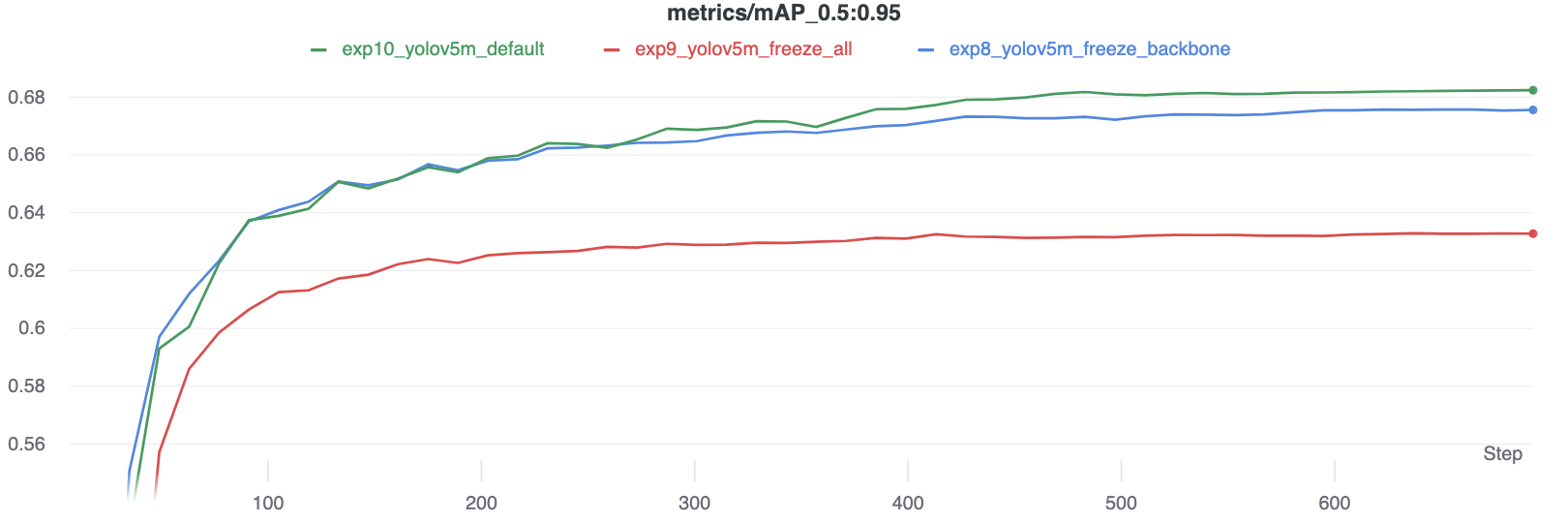
|
|
|
|
<img width="922" alt="Screenshot 2020-11-06 at 18 08 13" src="https://user-images.githubusercontent.com/26833433/98394485-22081580-205b-11eb-9e37-1f9869fe91d8.png">
|
|
|
|
### GPU Utilization Comparison
|
|
|
|
Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
|
|
|
|
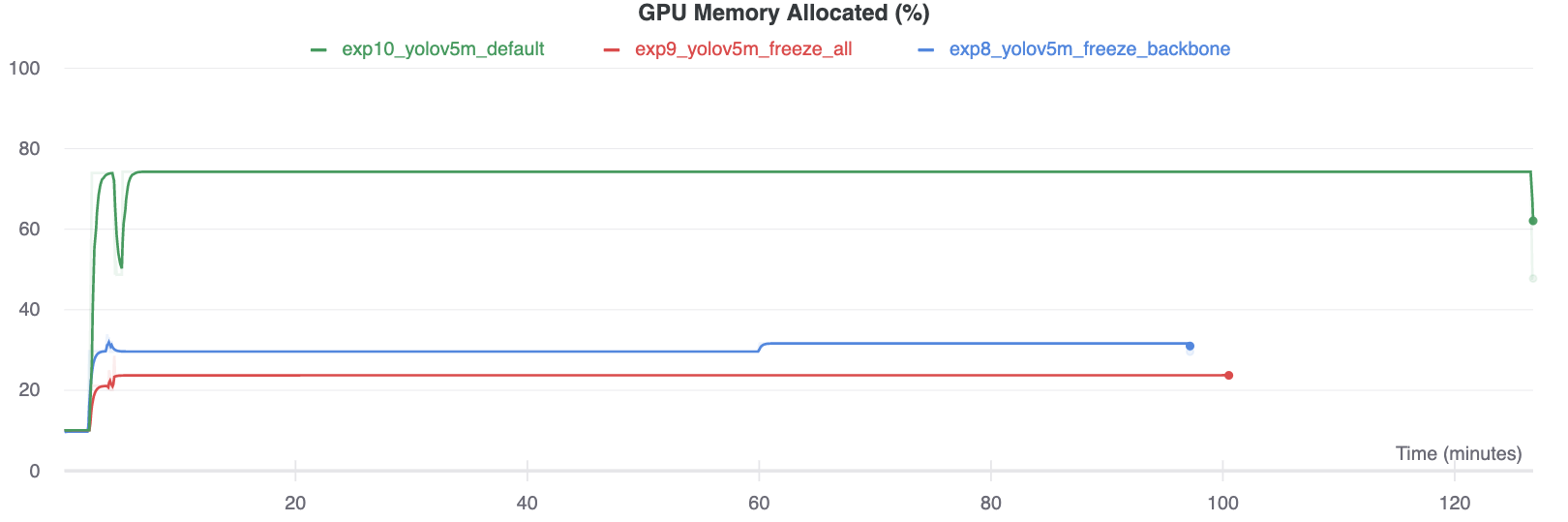
|
|
|
|
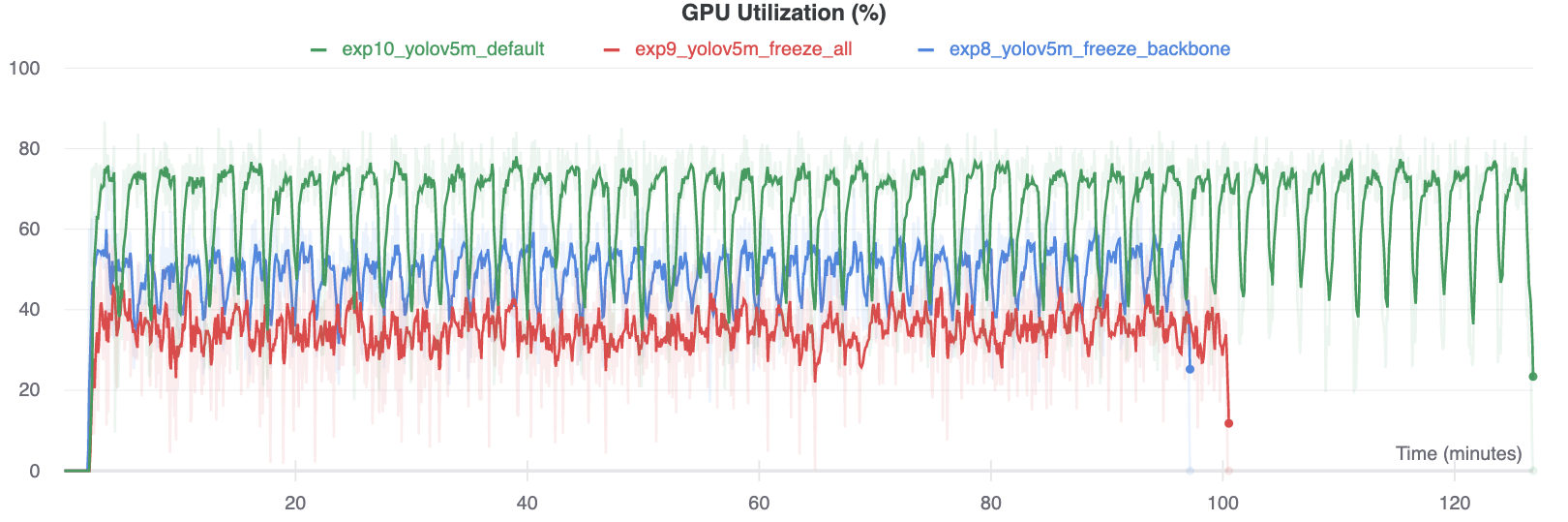
|
|
|
|
|
|
## Environments
|
|
|
|
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
|
|
|
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
|
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
|
|
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
|
|
- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
|
|
|
|
|
## Status
|
|
|
|
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
|
|
|
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit. |