ultralytics 8.0.141 create new SettingsManager (#3790)
This commit is contained in:
@ -60,7 +60,7 @@ repos:
|
|||||||
hooks:
|
hooks:
|
||||||
- id: codespell
|
- id: codespell
|
||||||
args:
|
args:
|
||||||
- --ignore-words-list=crate,nd,strack,dota
|
- --ignore-words-list=crate,nd,strack,dota,ane
|
||||||
|
|
||||||
# - repo: https://github.com/asottile/yesqa
|
# - repo: https://github.com/asottile/yesqa
|
||||||
# rev: v1.4.0
|
# rev: v1.4.0
|
||||||
|
|||||||
@ -234,14 +234,14 @@ We love your input! YOLOv5 and YOLOv8 would not be possible without help from ou
|
|||||||
|
|
||||||
## <div align="center">License</div>
|
## <div align="center">License</div>
|
||||||
|
|
||||||
YOLOv8 is available under two different licenses:
|
Ultralytics offers two licensing options to accommodate diverse use cases:
|
||||||
|
|
||||||
- **AGPL-3.0 License**: See [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file for details.
|
- **AGPL-3.0 License**: This [OSI-approved](https://opensource.org/licenses/) open-source license is ideal for students and enthusiasts, promoting open collaboration and knowledge sharing. See the [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file for more details.
|
||||||
- **Enterprise License**: Provides greater flexibility for commercial product development without the open-source requirements of AGPL-3.0. Typical use cases are embedding Ultralytics software and AI models in commercial products and applications. Request an Enterprise License at [Ultralytics Licensing](https://ultralytics.com/license).
|
- **Enterprise License**: Designed for commercial use, this license permits seamless integration of Ultralytics software and AI models into commercial goods and services, bypassing the open-source requirements of AGPL-3.0. If your scenario involves embedding our solutions into a commercial offering, reach out through [Ultralytics Licensing](https://ultralytics.com/license).
|
||||||
|
|
||||||
## <div align="center">Contact</div>
|
## <div align="center">Contact</div>
|
||||||
|
|
||||||
For YOLOv8 bug reports and feature requests please visit [GitHub Issues](https://github.com/ultralytics/ultralytics/issues), and join our [Discord](https://discord.gg/2wNGbc6g9X) community for questions and discussions!
|
For Ultralytics bug reports and feature requests please visit [GitHub Issues](https://github.com/ultralytics/ultralytics/issues), and join our [Discord](https://discord.gg/2wNGbc6g9X) community for questions and discussions!
|
||||||
|
|
||||||
<br>
|
<br>
|
||||||
<div align="center">
|
<div align="center">
|
||||||
|
|||||||
@ -233,14 +233,14 @@ success = model.export(format="onnx") # 将模型导出为 ONNX 格式
|
|||||||
|
|
||||||
## <div align="center">许可证</div>
|
## <div align="center">许可证</div>
|
||||||
|
|
||||||
YOLOv8 提供两种不同的许可证:
|
Ultralytics 提供两种许可证选项以适应各种使用场景:
|
||||||
|
|
||||||
- **AGPL-3.0 许可证**:详细信息请参阅 [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) 文件。
|
- **AGPL-3.0 许可证**:这个[OSI 批准](https://opensource.org/licenses/)的开源许可证非常适合学生和爱好者,可以推动开放的协作和知识分享。请查看[LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) 文件以了解更多细节。
|
||||||
- **企业许可证**:为商业产品开发提供更大的灵活性,无需遵循 AGPL-3.0 的开源要求。典型的用例是将 Ultralytics 软件和 AI 模型嵌入商业产品和应用中。在 [Ultralytics 授权](https://ultralytics.com/license) 处申请企业许可证。
|
- **企业许可证**:专为商业用途设计,该许可证允许将 Ultralytics 的软件和 AI 模型无缝集成到商业产品和服务中,从而绕过 AGPL-3.0 的开源要求。如果您的场景涉及将我们的解决方案嵌入到商业产品中,请通过 [Ultralytics Licensing](https://ultralytics.com/license)与我们联系。
|
||||||
|
|
||||||
## <div align="center">联系方式</div>
|
## <div align="center">联系方式</div>
|
||||||
|
|
||||||
对于 YOLOv8 的错误报告和功能请求,请访问 [GitHub Issues](https://github.com/ultralytics/ultralytics/issues),并加入我们的 [Discord](https://discord.gg/2wNGbc6g9X) 社区进行问题和讨论!
|
对于 Ultralytics 的错误报告和功能请求,请访问 [GitHub Issues](https://github.com/ultralytics/ultralytics/issues),并加入我们的 [Discord](https://discord.gg/2wNGbc6g9X) 社区进行问题和讨论!
|
||||||
|
|
||||||
<br>
|
<br>
|
||||||
<div align="center">
|
<div align="center">
|
||||||
|
|||||||
@ -1 +1 @@
|
|||||||
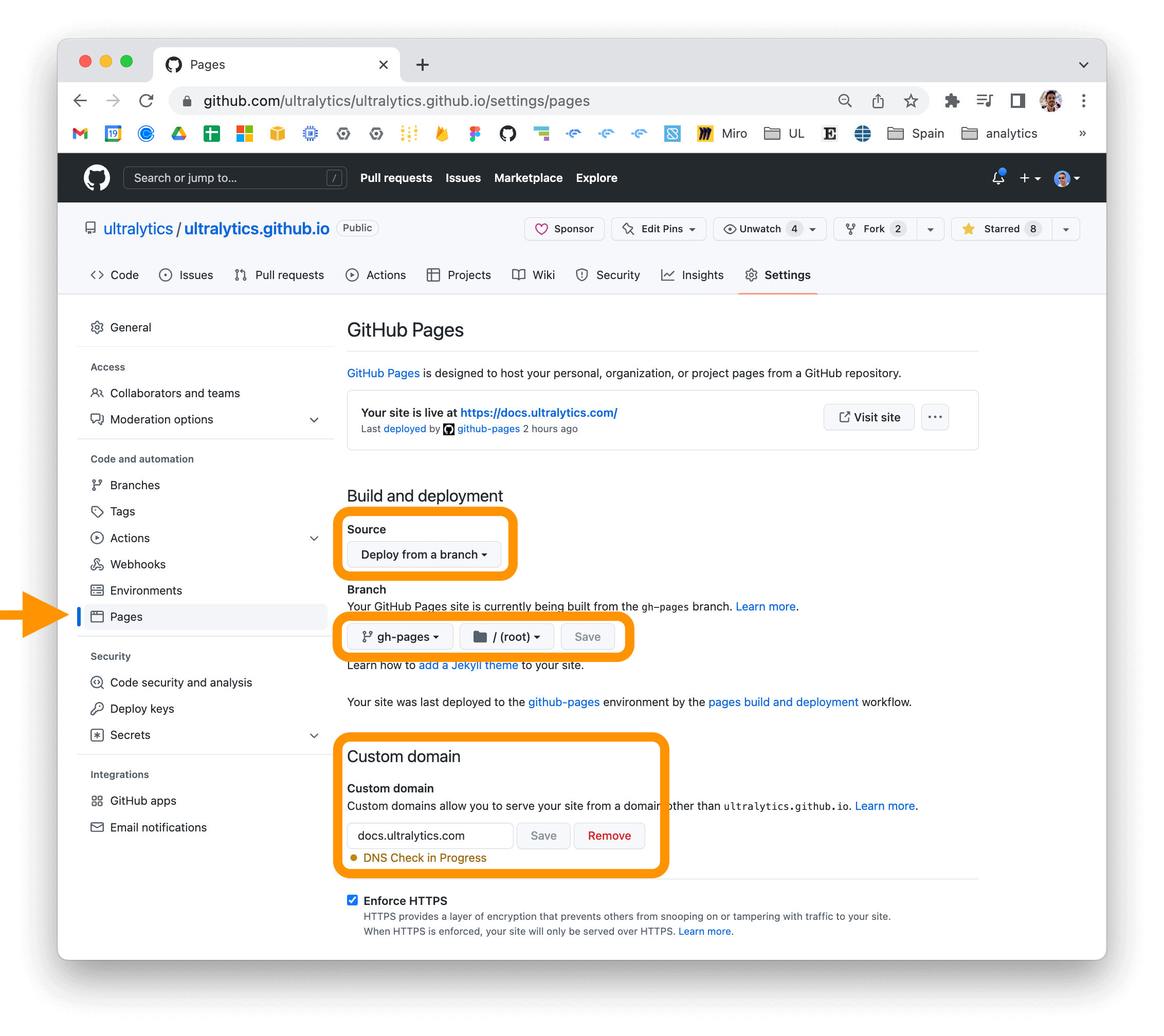
docs.ultralytics.com
|
docs.ultralytics.com
|
||||||
|
|||||||
@ -87,4 +87,4 @@ for your repository and updating the "Custom domain" field in the "GitHub Pages"
|
|||||||
|

|
||||||
|
|
||||||
For more information on deploying your MkDocs documentation site, see
|
For more information on deploying your MkDocs documentation site, see
|
||||||
the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
||||||
|
|||||||
@ -23,4 +23,4 @@ In addition to our Snyk scans, we also use GitHub's [CodeQL](https://docs.github
|
|||||||
|
|
||||||
If you suspect or discover a security vulnerability in any of our repositories, please let us know immediately. You can reach out to us directly via our [contact form](https://ultralytics.com/contact) or via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon as possible.
|
If you suspect or discover a security vulnerability in any of our repositories, please let us know immediately. You can reach out to us directly via our [contact form](https://ultralytics.com/contact) or via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon as possible.
|
||||||
|
|
||||||
We appreciate your help in keeping all Ultralytics open-source projects secure and safe for everyone.
|
We appreciate your help in keeping all Ultralytics open-source projects secure and safe for everyone.
|
||||||
|
|||||||
@ -21,8 +21,8 @@ def extract_classes_and_functions(filepath):
|
|||||||
with open(filepath, 'r') as file:
|
with open(filepath, 'r') as file:
|
||||||
content = file.read()
|
content = file.read()
|
||||||
|
|
||||||
class_pattern = r"(?:^|\n)class\s(\w+)(?:\(|:)"
|
class_pattern = r'(?:^|\n)class\s(\w+)(?:\(|:)'
|
||||||
func_pattern = r"(?:^|\n)def\s(\w+)\("
|
func_pattern = r'(?:^|\n)def\s(\w+)\('
|
||||||
|
|
||||||
classes = re.findall(class_pattern, content)
|
classes = re.findall(class_pattern, content)
|
||||||
functions = re.findall(func_pattern, content)
|
functions = re.findall(func_pattern, content)
|
||||||
@ -34,18 +34,21 @@ def create_markdown(py_filepath, module_path, classes, functions):
|
|||||||
md_filepath = py_filepath.with_suffix('.md')
|
md_filepath = py_filepath.with_suffix('.md')
|
||||||
|
|
||||||
# Read existing content and keep header content between first two ---
|
# Read existing content and keep header content between first two ---
|
||||||
header_content = ""
|
header_content = ''
|
||||||
if md_filepath.exists():
|
if md_filepath.exists():
|
||||||
with open(md_filepath, 'r') as file:
|
with open(md_filepath, 'r') as file:
|
||||||
existing_content = file.read()
|
existing_content = file.read()
|
||||||
header_parts = existing_content.split('---', 2)
|
header_parts = existing_content.split('---')
|
||||||
if 'description:' in header_parts or 'comments:' in header_parts and len(header_parts) >= 3:
|
for part in header_parts:
|
||||||
header_content = f"{header_parts[0]}---{header_parts[1]}---\n\n"
|
if 'description:' in part or 'comments:' in part:
|
||||||
|
header_content += f'---{part}---\n\n'
|
||||||
|
|
||||||
module_path = module_path.replace('.__init__', '')
|
module_path = module_path.replace('.__init__', '')
|
||||||
md_content = [f"## {class_name}\n---\n### ::: {module_path}.{class_name}\n<br><br>\n" for class_name in classes]
|
md_content = [f'## {class_name}\n---\n### ::: {module_path}.{class_name}\n<br><br>\n' for class_name in classes]
|
||||||
md_content.extend(f"## {func_name}\n---\n### ::: {module_path}.{func_name}\n<br><br>\n" for func_name in functions)
|
md_content.extend(f'## {func_name}\n---\n### ::: {module_path}.{func_name}\n<br><br>\n' for func_name in functions)
|
||||||
md_content = header_content + "\n".join(md_content)
|
md_content = header_content + '\n'.join(md_content)
|
||||||
|
if not md_content.endswith('\n'):
|
||||||
|
md_content += '\n'
|
||||||
|
|
||||||
os.makedirs(os.path.dirname(md_filepath), exist_ok=True)
|
os.makedirs(os.path.dirname(md_filepath), exist_ok=True)
|
||||||
with open(md_filepath, 'w') as file:
|
with open(md_filepath, 'w') as file:
|
||||||
@ -81,11 +84,11 @@ def create_nav_menu_yaml(nav_items):
|
|||||||
nav_tree_sorted = sort_nested_dict(nav_tree)
|
nav_tree_sorted = sort_nested_dict(nav_tree)
|
||||||
|
|
||||||
def _dict_to_yaml(d, level=0):
|
def _dict_to_yaml(d, level=0):
|
||||||
yaml_str = ""
|
yaml_str = ''
|
||||||
indent = " " * level
|
indent = ' ' * level
|
||||||
for k, v in d.items():
|
for k, v in d.items():
|
||||||
if isinstance(v, dict):
|
if isinstance(v, dict):
|
||||||
yaml_str += f"{indent}- {k}:\n{_dict_to_yaml(v, level + 1)}"
|
yaml_str += f'{indent}- {k}:\n{_dict_to_yaml(v, level + 1)}'
|
||||||
else:
|
else:
|
||||||
yaml_str += f"{indent}- {k}: {str(v).replace('docs/', '')}\n"
|
yaml_str += f"{indent}- {k}: {str(v).replace('docs/', '')}\n"
|
||||||
return yaml_str
|
return yaml_str
|
||||||
@ -99,7 +102,7 @@ def main():
|
|||||||
nav_items = []
|
nav_items = []
|
||||||
for root, _, files in os.walk(CODE_DIR):
|
for root, _, files in os.walk(CODE_DIR):
|
||||||
for file in files:
|
for file in files:
|
||||||
if file.endswith(".py"):
|
if file.endswith('.py'):
|
||||||
py_filepath = Path(root) / file
|
py_filepath = Path(root) / file
|
||||||
classes, functions = extract_classes_and_functions(py_filepath)
|
classes, functions = extract_classes_and_functions(py_filepath)
|
||||||
|
|
||||||
@ -113,5 +116,5 @@ def main():
|
|||||||
create_nav_menu_yaml(nav_items)
|
create_nav_menu_yaml(nav_items)
|
||||||
|
|
||||||
|
|
||||||
if __name__ == "__main__":
|
if __name__ == '__main__':
|
||||||
main()
|
main()
|
||||||
|
|||||||
@ -34,10 +34,10 @@ To train a YOLO model on the Caltech-101 dataset for 100 epochs, you can use the
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='caltech101', epochs=100, imgsz=416)
|
model.train(data='caltech101', epochs=100, imgsz=416)
|
||||||
```
|
```
|
||||||
@ -74,4 +74,4 @@ If you use the Caltech-101 dataset in your research or development work, please
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge Li Fei-Fei, Rob Fergus, and Pietro Perona for creating and maintaining the Caltech-101 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the Caltech-101 dataset and its creators, visit the [Caltech-101 dataset website](https://data.caltech.edu/records/mzrjq-6wc02).
|
We would like to acknowledge Li Fei-Fei, Rob Fergus, and Pietro Perona for creating and maintaining the Caltech-101 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the Caltech-101 dataset and its creators, visit the [Caltech-101 dataset website](https://data.caltech.edu/records/mzrjq-6wc02).
|
||||||
|
|||||||
@ -34,10 +34,10 @@ To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='caltech256', epochs=100, imgsz=416)
|
model.train(data='caltech256', epochs=100, imgsz=416)
|
||||||
```
|
```
|
||||||
@ -71,4 +71,4 @@ If you use the Caltech-256 dataset in your research or development work, please
|
|||||||
|
|
||||||
We would like to acknowledge Gregory Griffin, Alex Holub, and Pietro Perona for creating and maintaining the Caltech-256 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the
|
We would like to acknowledge Gregory Griffin, Alex Holub, and Pietro Perona for creating and maintaining the Caltech-256 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the
|
||||||
|
|
||||||
Caltech-256 dataset and its creators, visit the [Caltech-256 dataset website](https://data.caltech.edu/records/nyy15-4j048).
|
Caltech-256 dataset and its creators, visit the [Caltech-256 dataset website](https://data.caltech.edu/records/nyy15-4j048).
|
||||||
|
|||||||
@ -37,10 +37,10 @@ To train a YOLO model on the CIFAR-10 dataset for 100 epochs with an image size
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='cifar10', epochs=100, imgsz=32)
|
model.train(data='cifar10', epochs=100, imgsz=32)
|
||||||
```
|
```
|
||||||
@ -73,4 +73,4 @@ If you use the CIFAR-10 dataset in your research or development work, please cit
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-10 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-10 dataset and its creator, visit the [CIFAR-10 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
|
We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-10 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-10 dataset and its creator, visit the [CIFAR-10 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
|
||||||
|
|||||||
@ -37,10 +37,10 @@ To train a YOLO model on the CIFAR-100 dataset for 100 epochs with an image size
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='cifar100', epochs=100, imgsz=32)
|
model.train(data='cifar100', epochs=100, imgsz=32)
|
||||||
```
|
```
|
||||||
@ -73,4 +73,4 @@ If you use the CIFAR-100 dataset in your research or development work, please ci
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-100 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-100 dataset and its creator, visit the [CIFAR-100 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
|
We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-100 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-100 dataset and its creator, visit the [CIFAR-100 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
|
||||||
|
|||||||
@ -51,10 +51,10 @@ To train a CNN model on the Fashion-MNIST dataset for 100 epochs with an image s
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='fashion-mnist', epochs=100, imgsz=28)
|
model.train(data='fashion-mnist', epochs=100, imgsz=28)
|
||||||
```
|
```
|
||||||
@ -76,4 +76,4 @@ The example showcases the variety and complexity of the images in the Fashion-MN
|
|||||||
|
|
||||||
## Acknowledgments
|
## Acknowledgments
|
||||||
|
|
||||||
If you use the Fashion-MNIST dataset in your research or development work, please acknowledge the dataset by linking to the [GitHub repository](https://github.com/zalandoresearch/fashion-mnist). This dataset was made available by Zalando Research.
|
If you use the Fashion-MNIST dataset in your research or development work, please acknowledge the dataset by linking to the [GitHub repository](https://github.com/zalandoresearch/fashion-mnist). This dataset was made available by Zalando Research.
|
||||||
|
|||||||
@ -37,10 +37,10 @@ To train a deep learning model on the ImageNet dataset for 100 epochs with an im
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='imagenet', epochs=100, imgsz=224)
|
model.train(data='imagenet', epochs=100, imgsz=224)
|
||||||
```
|
```
|
||||||
@ -76,4 +76,4 @@ If you use the ImageNet dataset in your research or development work, please cit
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
|
We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
|
||||||
|
|||||||
@ -33,10 +33,10 @@ To test a deep learning model on the ImageNet10 dataset with an image size of 22
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='imagenet10', epochs=5, imgsz=224)
|
model.train(data='imagenet10', epochs=5, imgsz=224)
|
||||||
```
|
```
|
||||||
@ -71,4 +71,4 @@ If you use the ImageNet10 dataset in your research or development work, please c
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset. The ImageNet10 dataset, while a compact subset, is a valuable resource for quick testing and debugging in the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
|
We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset. The ImageNet10 dataset, while a compact subset, is a valuable resource for quick testing and debugging in the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
|
||||||
|
|||||||
@ -35,10 +35,10 @@ To train a model on the ImageNette dataset for 100 epochs with a standard image
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='imagenette', epochs=100, imgsz=224)
|
model.train(data='imagenette', epochs=100, imgsz=224)
|
||||||
```
|
```
|
||||||
@ -70,10 +70,10 @@ To use these datasets, simply replace 'imagenette' with 'imagenette160' or 'imag
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model with ImageNette160
|
# Train the model with ImageNette160
|
||||||
model.train(data='imagenette160', epochs=100, imgsz=160)
|
model.train(data='imagenette160', epochs=100, imgsz=160)
|
||||||
```
|
```
|
||||||
@ -91,10 +91,10 @@ To use these datasets, simply replace 'imagenette' with 'imagenette160' or 'imag
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model with ImageNette320
|
# Train the model with ImageNette320
|
||||||
model.train(data='imagenette320', epochs=100, imgsz=320)
|
model.train(data='imagenette320', epochs=100, imgsz=320)
|
||||||
```
|
```
|
||||||
@ -110,4 +110,4 @@ These smaller versions of the dataset allow for rapid iterations during the deve
|
|||||||
|
|
||||||
## Citations and Acknowledgments
|
## Citations and Acknowledgments
|
||||||
|
|
||||||
If you use the ImageNette dataset in your research or development work, please acknowledge it appropriately. For more information about the ImageNette dataset, visit the [ImageNette dataset GitHub page](https://github.com/fastai/imagenette).
|
If you use the ImageNette dataset in your research or development work, please acknowledge it appropriately. For more information about the ImageNette dataset, visit the [ImageNette dataset GitHub page](https://github.com/fastai/imagenette).
|
||||||
|
|||||||
@ -32,10 +32,10 @@ To train a CNN model on the ImageWoof dataset for 100 epochs with an image size
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='imagewoof', epochs=100, imgsz=224)
|
model.train(data='imagewoof', epochs=100, imgsz=224)
|
||||||
```
|
```
|
||||||
@ -81,4 +81,4 @@ The example showcases the subtle differences and similarities among the differen
|
|||||||
|
|
||||||
If you use the ImageWoof dataset in your research or development work, please make sure to acknowledge the creators of the dataset by linking to the [official dataset repository](https://github.com/fastai/imagenette). As of my knowledge cutoff in September 2021, there is no official publication specifically about ImageWoof for citation.
|
If you use the ImageWoof dataset in your research or development work, please make sure to acknowledge the creators of the dataset by linking to the [official dataset repository](https://github.com/fastai/imagenette). As of my knowledge cutoff in September 2021, there is no official publication specifically about ImageWoof for citation.
|
||||||
|
|
||||||
We would like to acknowledge the FastAI team for creating and maintaining the ImageWoof dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageWoof dataset, visit the [ImageWoof dataset repository](https://github.com/fastai/imagenette).
|
We would like to acknowledge the FastAI team for creating and maintaining the ImageWoof dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageWoof dataset, visit the [ImageWoof dataset repository](https://github.com/fastai/imagenette).
|
||||||
|
|||||||
@ -83,10 +83,10 @@ In this example, the `train` directory contains subdirectories for each class in
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
@ -94,7 +94,7 @@ In this example, the `train` directory contains subdirectories for each class in
|
|||||||
model.train(data='path/to/dataset', epochs=100, imgsz=640)
|
model.train(data='path/to/dataset', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Start training from a pretrained *.pt model
|
# Start training from a pretrained *.pt model
|
||||||
yolo detect train data=path/to/data model=yolov8n-cls.pt epochs=100 imgsz=640
|
yolo detect train data=path/to/data model=yolov8n-cls.pt epochs=100 imgsz=640
|
||||||
@ -117,4 +117,4 @@ Ultralytics supports the following datasets with automatic download:
|
|||||||
|
|
||||||
### Adding your own dataset
|
### Adding your own dataset
|
||||||
|
|
||||||
If you have your own dataset and would like to use it for training classification models with Ultralytics, ensure that it follows the format specified above under "Dataset format" and then point your `data` argument to the dataset directory.
|
If you have your own dataset and would like to use it for training classification models with Ultralytics, ensure that it follows the format specified above under "Dataset format" and then point your `data` argument to the dataset directory.
|
||||||
|
|||||||
@ -40,10 +40,10 @@ To train a CNN model on the MNIST dataset for 100 epochs with an image size of 3
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-cls.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='mnist', epochs=100, imgsz=32)
|
model.train(data='mnist', epochs=100, imgsz=32)
|
||||||
```
|
```
|
||||||
@ -79,4 +79,4 @@ research or development work, please cite the following paper:
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the machine learning and computer vision research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/).
|
We would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the machine learning and computer vision research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/).
|
||||||
|
|||||||
@ -47,10 +47,10 @@ To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image s
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='Argoverse.yaml', epochs=100, imgsz=640)
|
model.train(data='Argoverse.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -86,4 +86,4 @@ If you use the Argoverse dataset in your research or development work, please ci
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/).
|
We would like to acknowledge Argo AI for creating and maintaining the Argoverse dataset as a valuable resource for the autonomous driving research community. For more information about the Argoverse dataset and its creators, visit the [Argoverse dataset website](https://www.argoverse.org/).
|
||||||
|
|||||||
@ -47,10 +47,10 @@ To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size o
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco.yaml', epochs=100, imgsz=640)
|
model.train(data='coco.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -78,7 +78,7 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lin2015microsoft,
|
@misc{lin2015microsoft,
|
||||||
title={Microsoft COCO: Common Objects in Context},
|
title={Microsoft COCO: Common Objects in Context},
|
||||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||||
year={2015},
|
year={2015},
|
||||||
eprint={1405.0312},
|
eprint={1405.0312},
|
||||||
@ -87,4 +87,4 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||||
|
|||||||
@ -37,10 +37,10 @@ To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
model.train(data='coco8.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -68,7 +68,7 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lin2015microsoft,
|
@misc{lin2015microsoft,
|
||||||
title={Microsoft COCO: Common Objects in Context},
|
title={Microsoft COCO: Common Objects in Context},
|
||||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||||
year={2015},
|
year={2015},
|
||||||
eprint={1405.0312},
|
eprint={1405.0312},
|
||||||
@ -77,4 +77,4 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||||
|
|||||||
@ -46,10 +46,10 @@ To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)
|
model.train(data='GlobalWheat2020.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -84,4 +84,4 @@ If you use the Global Wheat Head Dataset in your research or development work, p
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](http://www.global-wheat.com/).
|
We would like to acknowledge the researchers and institutions that contributed to the creation and maintenance of the Global Wheat Head Dataset as a valuable resource for the plant phenotyping and crop management research community. For more information about the dataset and its creators, visit the [Global Wheat Head Dataset website](http://www.global-wheat.com/).
|
||||||
|
|||||||
@ -51,10 +51,10 @@ Here's how you can use these formats to train your model:
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
@ -62,7 +62,7 @@ Here's how you can use these formats to train your model:
|
|||||||
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Start training from a pretrained *.pt model
|
# Start training from a pretrained *.pt model
|
||||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
|
||||||
@ -100,4 +100,4 @@ convert_coco(labels_dir='../coco/annotations/')
|
|||||||
|
|
||||||
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
|
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format.
|
||||||
|
|
||||||
Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
|
Remember to double-check if the dataset you want to use is compatible with your model and follows the necessary format conventions. Properly formatted datasets are crucial for training successful object detection models.
|
||||||
|
|||||||
@ -46,10 +46,10 @@ To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='Objects365.yaml', epochs=100, imgsz=640)
|
model.train(data='Objects365.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -85,4 +85,4 @@ If you use the Objects365 dataset in your research or development work, please c
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).
|
We would like to acknowledge the team of researchers who created and maintain the Objects365 dataset as a valuable resource for the computer vision research community. For more information about the Objects365 dataset and its creators, visit the [Objects365 dataset website](https://www.objects365.org/).
|
||||||
|
|||||||
@ -48,10 +48,10 @@ To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image si
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)
|
model.train(data='SKU-110K.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -86,4 +86,4 @@ If you use the SKU-110k dataset in your research or development work, please cit
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19).
|
We would like to acknowledge Eran Goldman et al. for creating and maintaining the SKU-110k dataset as a valuable resource for the computer vision research community. For more information about the SKU-110k dataset and its creators, visit the [SKU-110k dataset GitHub repository](https://github.com/eg4000/SKU110K_CVPR19).
|
||||||
|
|||||||
@ -44,10 +44,10 @@ To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image si
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='VisDrone.yaml', epochs=100, imgsz=640)
|
model.train(data='VisDrone.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -76,8 +76,8 @@ If you use the VisDrone dataset in your research or development work, please cit
|
|||||||
```bibtex
|
```bibtex
|
||||||
@ARTICLE{9573394,
|
@ARTICLE{9573394,
|
||||||
author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},
|
author={Zhu, Pengfei and Wen, Longyin and Du, Dawei and Bian, Xiao and Fan, Heng and Hu, Qinghua and Ling, Haibin},
|
||||||
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
|
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
|
||||||
title={Detection and Tracking Meet Drones Challenge},
|
title={Detection and Tracking Meet Drones Challenge},
|
||||||
year={2021},
|
year={2021},
|
||||||
volume={},
|
volume={},
|
||||||
number={},
|
number={},
|
||||||
@ -85,4 +85,4 @@ If you use the VisDrone dataset in your research or development work, please cit
|
|||||||
doi={10.1109/TPAMI.2021.3119563}}
|
doi={10.1109/TPAMI.2021.3119563}}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
|
We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
|
||||||
|
|||||||
@ -47,10 +47,10 @@ To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='VOC.yaml', epochs=100, imgsz=640)
|
model.train(data='VOC.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -79,7 +79,7 @@ If you use the VOC dataset in your research or development work, please cite the
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{everingham2010pascal,
|
@misc{everingham2010pascal,
|
||||||
title={The PASCAL Visual Object Classes (VOC) Challenge},
|
title={The PASCAL Visual Object Classes (VOC) Challenge},
|
||||||
author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},
|
author={Mark Everingham and Luc Van Gool and Christopher K. I. Williams and John Winn and Andrew Zisserman},
|
||||||
year={2010},
|
year={2010},
|
||||||
eprint={0909.5206},
|
eprint={0909.5206},
|
||||||
@ -88,4 +88,4 @@ If you use the VOC dataset in your research or development work, please cite the
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
|
We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
|
||||||
|
|||||||
@ -50,10 +50,10 @@ To train a model on the xView dataset for 100 epochs with an image size of 640,
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='xView.yaml', epochs=100, imgsz=640)
|
model.train(data='xView.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -81,7 +81,7 @@ If you use the xView dataset in your research or development work, please cite t
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lam2018xview,
|
@misc{lam2018xview,
|
||||||
title={xView: Objects in Context in Overhead Imagery},
|
title={xView: Objects in Context in Overhead Imagery},
|
||||||
author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},
|
author={Darius Lam and Richard Kuzma and Kevin McGee and Samuel Dooley and Michael Laielli and Matthew Klaric and Yaroslav Bulatov and Brendan McCord},
|
||||||
year={2018},
|
year={2018},
|
||||||
eprint={1802.07856},
|
eprint={1802.07856},
|
||||||
@ -90,4 +90,4 @@ If you use the xView dataset in your research or development work, please cite t
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).
|
We would like to acknowledge the [Defense Innovation Unit](https://www.diu.mil/) (DIU) and the creators of the xView dataset for their valuable contribution to the computer vision research community. For more information about the xView dataset and its creators, visit the [xView dataset website](http://xviewdataset.org/).
|
||||||
|
|||||||
@ -56,4 +56,4 @@ Image classification is a computer vision task that involves categorizing an ima
|
|||||||
Multi-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.
|
Multi-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.
|
||||||
|
|
||||||
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.
|
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.
|
||||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||||
|
|||||||
@ -48,10 +48,10 @@ To train a YOLOv8n-pose model on the COCO-Pose dataset for 100 epochs with an im
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco-pose.yaml', epochs=100, imgsz=640)
|
model.train(data='coco-pose.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -79,7 +79,7 @@ If you use the COCO-Pose dataset in your research or development work, please ci
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lin2015microsoft,
|
@misc{lin2015microsoft,
|
||||||
title={Microsoft COCO: Common Objects in Context},
|
title={Microsoft COCO: Common Objects in Context},
|
||||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||||
year={2015},
|
year={2015},
|
||||||
eprint={1405.0312},
|
eprint={1405.0312},
|
||||||
@ -88,4 +88,4 @@ If you use the COCO-Pose dataset in your research or development work, please ci
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO-Pose dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO-Pose dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||||
|
|||||||
@ -37,10 +37,10 @@ To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an i
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
|
model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -68,7 +68,7 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lin2015microsoft,
|
@misc{lin2015microsoft,
|
||||||
title={Microsoft COCO: Common Objects in Context},
|
title={Microsoft COCO: Common Objects in Context},
|
||||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||||
year={2015},
|
year={2015},
|
||||||
eprint={1405.0312},
|
eprint={1405.0312},
|
||||||
@ -77,4 +77,4 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||||
|
|||||||
@ -70,10 +70,10 @@ For example if we assume five keypoints of facial landmark: [left eye, right eye
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-pose.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
@ -81,7 +81,7 @@ For example if we assume five keypoints of facial landmark: [left eye, right eye
|
|||||||
model.train(data='coco128-pose.yaml', epochs=100, imgsz=640)
|
model.train(data='coco128-pose.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Start training from a pretrained *.pt model
|
# Start training from a pretrained *.pt model
|
||||||
yolo detect train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
yolo detect train data=coco128-pose.yaml model=yolov8n-pose.pt epochs=100 imgsz=640
|
||||||
@ -125,4 +125,4 @@ from ultralytics.data.converter import convert_coco
|
|||||||
convert_coco(labels_dir='../coco/annotations/', use_keypoints=True)
|
convert_coco(labels_dir='../coco/annotations/', use_keypoints=True)
|
||||||
```
|
```
|
||||||
|
|
||||||
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format. The `use_keypoints` parameter specifies whether to include keypoints (for pose estimation) in the converted labels.
|
This conversion tool can be used to convert the COCO dataset or any dataset in the COCO format to the Ultralytics YOLO format. The `use_keypoints` parameter specifies whether to include keypoints (for pose estimation) in the converted labels.
|
||||||
|
|||||||
@ -47,10 +47,10 @@ To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an imag
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco-seg.yaml', epochs=100, imgsz=640)
|
model.train(data='coco-seg.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -78,7 +78,7 @@ If you use the COCO-Seg dataset in your research or development work, please cit
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lin2015microsoft,
|
@misc{lin2015microsoft,
|
||||||
title={Microsoft COCO: Common Objects in Context},
|
title={Microsoft COCO: Common Objects in Context},
|
||||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||||
year={2015},
|
year={2015},
|
||||||
eprint={1405.0312},
|
eprint={1405.0312},
|
||||||
@ -87,4 +87,4 @@ If you use the COCO-Seg dataset in your research or development work, please cit
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We extend our thanks to the COCO Consortium for creating and maintaining this invaluable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
We extend our thanks to the COCO Consortium for creating and maintaining this invaluable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||||
|
|||||||
@ -37,10 +37,10 @@ To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 epochs with an ima
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)
|
model.train(data='coco8-seg.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
@ -68,7 +68,7 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{lin2015microsoft,
|
@misc{lin2015microsoft,
|
||||||
title={Microsoft COCO: Common Objects in Context},
|
title={Microsoft COCO: Common Objects in Context},
|
||||||
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
author={Tsung-Yi Lin and Michael Maire and Serge Belongie and Lubomir Bourdev and Ross Girshick and James Hays and Pietro Perona and Deva Ramanan and C. Lawrence Zitnick and Piotr Dollár},
|
||||||
year={2015},
|
year={2015},
|
||||||
eprint={1405.0312},
|
eprint={1405.0312},
|
||||||
@ -77,4 +77,4 @@ If you use the COCO dataset in your research or development work, please cite th
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
|
||||||
|
|||||||
@ -71,10 +71,10 @@ The `train` and `val` fields specify the paths to the directories containing the
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n-seg.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
@ -82,7 +82,7 @@ The `train` and `val` fields specify the paths to the directories containing the
|
|||||||
model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
model.train(data='coco128-seg.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Start training from a pretrained *.pt model
|
# Start training from a pretrained *.pt model
|
||||||
yolo detect train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
yolo detect train data=coco128-seg.yaml model=yolov8n-seg.pt epochs=100 imgsz=640
|
||||||
@ -137,4 +137,4 @@ auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model='sam_b.pt
|
|||||||
|
|
||||||
The `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](https://docs.ultralytics.com/models/sam), the device to run the models on, and the output directory for saving the annotated results.
|
The `auto_annotate` function takes the path to your images, along with optional arguments for specifying the pre-trained detection and [SAM segmentation models](https://docs.ultralytics.com/models/sam), the device to run the models on, and the output directory for saving the annotated results.
|
||||||
|
|
||||||
By leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
|
By leveraging the power of pre-trained models, auto-annotation can significantly reduce the time and effort required for creating high-quality segmentation datasets. This feature is particularly useful for researchers and developers working with large image collections, as it allows them to focus on model development and evaluation rather than manual annotation.
|
||||||
|
|||||||
@ -16,15 +16,15 @@ Support for training trackers alone is coming soon
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
||||||
```
|
```
|
||||||
|
|||||||
@ -32,4 +32,4 @@ If you notice a test failing, it would be a great help if you could report it th
|
|||||||
|
|
||||||
Remember, a successful CI test does not mean that everything is perfect. It is always recommended to manually review the code before deployment or merging changes.
|
Remember, a successful CI test does not mean that everything is perfect. It is always recommended to manually review the code before deployment or merging changes.
|
||||||
|
|
||||||
Happy coding!
|
Happy coding!
|
||||||
|
|||||||
@ -67,4 +67,4 @@ that any of the provisions of this Agreement shall be held by a court or other t
|
|||||||
to be unenforceable, the remaining portions hereof shall remain in full force and effect.
|
to be unenforceable, the remaining portions hereof shall remain in full force and effect.
|
||||||
|
|
||||||
**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses
|
**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses
|
||||||
hereunder.
|
hereunder.
|
||||||
|
|||||||
@ -36,4 +36,4 @@ Improving the accuracy of a YOLO model may involve several strategies, such as:
|
|||||||
|
|
||||||
Remember that there's often a trade-off between accuracy and inference speed, so finding the right balance is crucial for your specific application.
|
Remember that there's often a trade-off between accuracy and inference speed, so finding the right balance is crucial for your specific application.
|
||||||
|
|
||||||
If you have any more questions or need assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through GitHub Issues or the official discussion forum.
|
If you have any more questions or need assistance, don't hesitate to consult the Ultralytics documentation or reach out to the community through GitHub Issues or the official discussion forum.
|
||||||
|
|||||||
@ -131,4 +131,4 @@ For answers to common questions about this code of conduct, see the FAQ at
|
|||||||
https://www.contributor-covenant.org/faq. Translations are available at
|
https://www.contributor-covenant.org/faq. Translations are available at
|
||||||
https://www.contributor-covenant.org/translations.
|
https://www.contributor-covenant.org/translations.
|
||||||
|
|
||||||
[homepage]: https://www.contributor-covenant.org
|
[homepage]: https://www.contributor-covenant.org
|
||||||
|
|||||||
@ -72,4 +72,4 @@ def example_function(arg1: int, arg2: str) -> bool:
|
|||||||
|
|
||||||
### GitHub Actions CI Tests
|
### GitHub Actions CI Tests
|
||||||
|
|
||||||
Before your pull request can be merged, all GitHub Actions Continuous Integration (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues
|
Before your pull request can be merged, all GitHub Actions Continuous Integration (CI) tests must pass. These tests include linting, unit tests, and other checks to ensure that your changes meet the quality standards of the project. Make sure to review the output of the GitHub Actions and fix any issues
|
||||||
|
|||||||
@ -34,4 +34,4 @@ At Ultralytics, we recognize that the long-term success of our company relies no
|
|||||||
|
|
||||||
This policy reflects our commitment to minimizing our environmental footprint, ensuring the safety and well-being of our employees, and continuously improving our performance.
|
This policy reflects our commitment to minimizing our environmental footprint, ensuring the safety and well-being of our employees, and continuously improving our performance.
|
||||||
|
|
||||||
Please remember that the implementation of an effective EHS policy requires the involvement and commitment of everyone working at or with Ultralytics. We encourage you to take personal responsibility for your safety and the safety of others, and to take care of the environment in which we live and work.
|
Please remember that the implementation of an effective EHS policy requires the involvement and commitment of everyone working at or with Ultralytics. We encourage you to take personal responsibility for your safety and the safety of others, and to take care of the environment in which we live and work.
|
||||||
|
|||||||
@ -15,4 +15,4 @@ Welcome to the Ultralytics Help page! We are committed to providing you with com
|
|||||||
- [Environmental, Health and Safety (EHS) Policy](environmental-health-safety.md): Explore Ultralytics' dedicated approach towards maintaining a sustainable, safe, and healthy work environment for all our stakeholders.
|
- [Environmental, Health and Safety (EHS) Policy](environmental-health-safety.md): Explore Ultralytics' dedicated approach towards maintaining a sustainable, safe, and healthy work environment for all our stakeholders.
|
||||||
- [Security Policy](../SECURITY.md): Understand our security practices and how to report security vulnerabilities responsibly.
|
- [Security Policy](../SECURITY.md): Understand our security practices and how to report security vulnerabilities responsibly.
|
||||||
|
|
||||||
We highly recommend going through these guides to make the most of your collaboration with the Ultralytics community. Our goal is to maintain a welcoming and supportive environment for all users and contributors. If you need further assistance, don't hesitate to reach out to us through GitHub Issues or the official discussion forum. Happy coding!
|
We highly recommend going through these guides to make the most of your collaboration with the Ultralytics community. Our goal is to maintain a welcoming and supportive environment for all users and contributors. If you need further assistance, don't hesitate to reach out to us through GitHub Issues or the official discussion forum. Happy coding!
|
||||||
|
|||||||
@ -75,4 +75,4 @@ RuntimeError: Expected input[1, 0, 640, 640] to have 3 channels, but got 0 chann
|
|||||||
|
|
||||||
In this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model ('yolov8n.pt'), includes all necessary dependencies, and provides a clear description of the problem along with the error message.
|
In this example, the MRE demonstrates the issue with a minimal amount of code, uses a public model ('yolov8n.pt'), includes all necessary dependencies, and provides a clear description of the problem along with the error message.
|
||||||
|
|
||||||
By following these guidelines, you'll help the maintainers and contributors of Ultralytics YOLO repositories to understand and resolve your issue more efficiently.
|
By following these guidelines, you'll help the maintainers and contributors of Ultralytics YOLO repositories to understand and resolve your issue more efficiently.
|
||||||
|
|||||||
@ -63,4 +63,4 @@ To get started with the Ultralytics Android App, follow these steps:
|
|||||||
|
|
||||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||||
|
|
||||||
With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
|
With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
|
||||||
|
|||||||
@ -49,4 +49,4 @@ Welcome to the Ultralytics HUB App! We are excited to introduce this powerful mo
|
|||||||
- [**iOS**](./ios.md): Learn about YOLO CoreML models accelerated on Apple's Neural Engine for iPhones and iPads.
|
- [**iOS**](./ios.md): Learn about YOLO CoreML models accelerated on Apple's Neural Engine for iPhones and iPads.
|
||||||
- [**Android**](./android.md): Explore TFLite acceleration on Android mobile devices.
|
- [**Android**](./android.md): Explore TFLite acceleration on Android mobile devices.
|
||||||
|
|
||||||
Get started today by downloading the Ultralytics HUB App on your mobile device and unlock the potential of YOLOv5 and YOLOv8 models on-the-go. Don't forget to check out our comprehensive [HUB Docs](../) for more information on training, deploying, and using your custom models with the Ultralytics HUB platform.
|
Get started today by downloading the Ultralytics HUB App on your mobile device and unlock the potential of YOLOv5 and YOLOv8 models on-the-go. Don't forget to check out our comprehensive [HUB Docs](../) for more information on training, deploying, and using your custom models with the Ultralytics HUB platform.
|
||||||
|
|||||||
@ -53,4 +53,4 @@ To get started with the Ultralytics iOS App, follow these steps:
|
|||||||
|
|
||||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||||
|
|
||||||
With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
|
With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
|
||||||
|
|||||||
@ -156,4 +156,4 @@ Navigate to the Dataset page of the dataset you want to delete, open the dataset
|
|||||||
|
|
||||||
If you change your mind, you can restore the dataset from the [Trash](https://hub.ultralytics.com/trash) page.
|
If you change your mind, you can restore the dataset from the [Trash](https://hub.ultralytics.com/trash) page.
|
||||||
|
|
||||||
|

|
||||||
|
|||||||
@ -39,4 +39,4 @@ We hope that the resources here will help you get the most out of HUB. Please br
|
|||||||
- [**Ultralytics HUB App**](./app/index.md). Learn about the Ultralytics App for iOS and Android, which allows you to run models directly on your mobile device.
|
- [**Ultralytics HUB App**](./app/index.md). Learn about the Ultralytics App for iOS and Android, which allows you to run models directly on your mobile device.
|
||||||
* [**iOS**](./app/ios.md). Learn about YOLO CoreML models accelerated on Apple's Neural Engine on iPhones and iPads.
|
* [**iOS**](./app/ios.md). Learn about YOLO CoreML models accelerated on Apple's Neural Engine on iPhones and iPads.
|
||||||
* [**Android**](./app/android.md). Explore TFLite acceleration on mobile devices.
|
* [**Android**](./app/android.md). Explore TFLite acceleration on mobile devices.
|
||||||
- [**Inference API**](./inference_api.md). Understand how to use the Inference API for running your trained models in the cloud to generate predictions.
|
- [**Inference API**](./inference_api.md). Understand how to use the Inference API for running your trained models in the cloud to generate predictions.
|
||||||
|
|||||||
@ -111,7 +111,7 @@ YOLO detection models, such as `yolov8n.pt`, can return JSON responses from loca
|
|||||||
=== "Local"
|
=== "Local"
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load model
|
# Load model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
@ -119,12 +119,12 @@ YOLO detection models, such as `yolov8n.pt`, can return JSON responses from loca
|
|||||||
results = model('image.jpg')
|
results = model('image.jpg')
|
||||||
|
|
||||||
# Print image.jpg results in JSON format
|
# Print image.jpg results in JSON format
|
||||||
print(results[0].tojson())
|
print(results[0].tojson())
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "CLI API"
|
=== "CLI API"
|
||||||
```bash
|
```bash
|
||||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||||
-H "x-api-key: API_KEY" \
|
-H "x-api-key: API_KEY" \
|
||||||
-F "image=@/path/to/image.jpg" \
|
-F "image=@/path/to/image.jpg" \
|
||||||
-F "size=640" \
|
-F "size=640" \
|
||||||
@ -135,21 +135,21 @@ YOLO detection models, such as `yolov8n.pt`, can return JSON responses from loca
|
|||||||
=== "Python API"
|
=== "Python API"
|
||||||
```python
|
```python
|
||||||
import requests
|
import requests
|
||||||
|
|
||||||
# API URL, use actual MODEL_ID
|
# API URL, use actual MODEL_ID
|
||||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||||
|
|
||||||
# Headers, use actual API_KEY
|
# Headers, use actual API_KEY
|
||||||
headers = {"x-api-key": "API_KEY"}
|
headers = {"x-api-key": "API_KEY"}
|
||||||
|
|
||||||
# Inference arguments (optional)
|
# Inference arguments (optional)
|
||||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||||
|
|
||||||
# Load image and send request
|
# Load image and send request
|
||||||
with open("path/to/image.jpg", "rb") as image_file:
|
with open("path/to/image.jpg", "rb") as image_file:
|
||||||
files = {"image": image_file}
|
files = {"image": image_file}
|
||||||
response = requests.post(url, headers=headers, files=files, data=data)
|
response = requests.post(url, headers=headers, files=files, data=data)
|
||||||
|
|
||||||
print(response.json())
|
print(response.json())
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -205,7 +205,7 @@ YOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses fr
|
|||||||
=== "Local"
|
=== "Local"
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load model
|
# Load model
|
||||||
model = YOLO('yolov8n-seg.pt')
|
model = YOLO('yolov8n-seg.pt')
|
||||||
|
|
||||||
@ -213,12 +213,12 @@ YOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses fr
|
|||||||
results = model('image.jpg')
|
results = model('image.jpg')
|
||||||
|
|
||||||
# Print image.jpg results in JSON format
|
# Print image.jpg results in JSON format
|
||||||
print(results[0].tojson())
|
print(results[0].tojson())
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "CLI API"
|
=== "CLI API"
|
||||||
```bash
|
```bash
|
||||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||||
-H "x-api-key: API_KEY" \
|
-H "x-api-key: API_KEY" \
|
||||||
-F "image=@/path/to/image.jpg" \
|
-F "image=@/path/to/image.jpg" \
|
||||||
-F "size=640" \
|
-F "size=640" \
|
||||||
@ -229,21 +229,21 @@ YOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses fr
|
|||||||
=== "Python API"
|
=== "Python API"
|
||||||
```python
|
```python
|
||||||
import requests
|
import requests
|
||||||
|
|
||||||
# API URL, use actual MODEL_ID
|
# API URL, use actual MODEL_ID
|
||||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||||
|
|
||||||
# Headers, use actual API_KEY
|
# Headers, use actual API_KEY
|
||||||
headers = {"x-api-key": "API_KEY"}
|
headers = {"x-api-key": "API_KEY"}
|
||||||
|
|
||||||
# Inference arguments (optional)
|
# Inference arguments (optional)
|
||||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||||
|
|
||||||
# Load image and send request
|
# Load image and send request
|
||||||
with open("path/to/image.jpg", "rb") as image_file:
|
with open("path/to/image.jpg", "rb") as image_file:
|
||||||
files = {"image": image_file}
|
files = {"image": image_file}
|
||||||
response = requests.post(url, headers=headers, files=files, data=data)
|
response = requests.post(url, headers=headers, files=files, data=data)
|
||||||
|
|
||||||
print(response.json())
|
print(response.json())
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -342,7 +342,7 @@ YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from loca
|
|||||||
=== "Local"
|
=== "Local"
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load model
|
# Load model
|
||||||
model = YOLO('yolov8n-seg.pt')
|
model = YOLO('yolov8n-seg.pt')
|
||||||
|
|
||||||
@ -350,12 +350,12 @@ YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from loca
|
|||||||
results = model('image.jpg')
|
results = model('image.jpg')
|
||||||
|
|
||||||
# Print image.jpg results in JSON format
|
# Print image.jpg results in JSON format
|
||||||
print(results[0].tojson())
|
print(results[0].tojson())
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "CLI API"
|
=== "CLI API"
|
||||||
```bash
|
```bash
|
||||||
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
|
||||||
-H "x-api-key: API_KEY" \
|
-H "x-api-key: API_KEY" \
|
||||||
-F "image=@/path/to/image.jpg" \
|
-F "image=@/path/to/image.jpg" \
|
||||||
-F "size=640" \
|
-F "size=640" \
|
||||||
@ -366,21 +366,21 @@ YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from loca
|
|||||||
=== "Python API"
|
=== "Python API"
|
||||||
```python
|
```python
|
||||||
import requests
|
import requests
|
||||||
|
|
||||||
# API URL, use actual MODEL_ID
|
# API URL, use actual MODEL_ID
|
||||||
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
url = f"https://api.ultralytics.com/v1/predict/MODEL_ID"
|
||||||
|
|
||||||
# Headers, use actual API_KEY
|
# Headers, use actual API_KEY
|
||||||
headers = {"x-api-key": "API_KEY"}
|
headers = {"x-api-key": "API_KEY"}
|
||||||
|
|
||||||
# Inference arguments (optional)
|
# Inference arguments (optional)
|
||||||
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
data = {"size": 640, "confidence": 0.25, "iou": 0.45}
|
||||||
|
|
||||||
# Load image and send request
|
# Load image and send request
|
||||||
with open("path/to/image.jpg", "rb") as image_file:
|
with open("path/to/image.jpg", "rb") as image_file:
|
||||||
files = {"image": image_file}
|
files = {"image": image_file}
|
||||||
response = requests.post(url, headers=headers, files=files, data=data)
|
response = requests.post(url, headers=headers, files=files, data=data)
|
||||||
|
|
||||||
print(response.json())
|
print(response.json())
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -455,4 +455,4 @@ YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from loca
|
|||||||
}
|
}
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|||||||
@ -210,4 +210,4 @@ Navigate to the Model page of the model you want to delete, open the model actio
|
|||||||
|
|
||||||
If you change your mind, you can restore the model from the [Trash](https://hub.ultralytics.com/trash) page.
|
If you change your mind, you can restore the model from the [Trash](https://hub.ultralytics.com/trash) page.
|
||||||
|
|
||||||
|

|
||||||
|
|||||||
@ -166,4 +166,4 @@ Navigate to the Project page of the project where the model you want to mode is
|
|||||||
|
|
||||||
Select the project you want to transfer the model to and click **Save**.
|
Select the project you want to transfer the model to and click **Save**.
|
||||||
|
|
||||||
|

|
||||||
|
|||||||
@ -48,4 +48,4 @@ Ultralytics YOLO repositories like YOLOv3, YOLOv5, or YOLOv8 are available under
|
|||||||
- **AGPL-3.0 License**: See [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file for details.
|
- **AGPL-3.0 License**: See [LICENSE](https://github.com/ultralytics/ultralytics/blob/main/LICENSE) file for details.
|
||||||
- **Enterprise License**: Provides greater flexibility for commercial product development without the open-source requirements of AGPL-3.0. Typical use cases are embedding Ultralytics software and AI models in commercial products and applications. Request an Enterprise License at [Ultralytics Licensing](https://ultralytics.com/license).
|
- **Enterprise License**: Provides greater flexibility for commercial product development without the open-source requirements of AGPL-3.0. Typical use cases are embedding Ultralytics software and AI models in commercial products and applications. Request an Enterprise License at [Ultralytics Licensing](https://ultralytics.com/license).
|
||||||
|
|
||||||
Please note our licensing approach ensures that any enhancements made to our open-source projects are shared back to the community. We firmly believe in the principles of open source, and we are committed to ensuring that our work can be used and improved upon in a manner that benefits everyone.
|
Please note our licensing approach ensures that any enhancements made to our open-source projects are shared back to the community. We firmly believe in the principles of open source, and we are committed to ensuring that our work can be used and improved upon in a manner that benefits everyone.
|
||||||
|
|||||||
@ -166,4 +166,4 @@ We would like to acknowledge the FastSAM authors for their significant contribut
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
The original FastSAM paper can be found on [arXiv](https://arxiv.org/abs/2306.12156). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/CASIA-IVA-Lab/FastSAM). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
The original FastSAM paper can be found on [arXiv](https://arxiv.org/abs/2306.12156). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/CASIA-IVA-Lab/FastSAM). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
||||||
|
|||||||
@ -45,4 +45,4 @@ model.info() # display model information
|
|||||||
model.train(data="coco128.yaml", epochs=100) # train the model
|
model.train(data="coco128.yaml", epochs=100) # train the model
|
||||||
```
|
```
|
||||||
|
|
||||||
For more details on each model, their supported tasks, modes, and performance, please visit their respective documentation pages linked above.
|
For more details on each model, their supported tasks, modes, and performance, please visit their respective documentation pages linked above.
|
||||||
|
|||||||
@ -96,4 +96,4 @@ If you find MobileSAM useful in your research or development work, please consid
|
|||||||
journal={arXiv preprint arXiv:2306.14289},
|
journal={arXiv preprint arXiv:2306.14289},
|
||||||
year={2023}
|
year={2023}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|||||||
@ -71,4 +71,4 @@ If you use Baidu's RT-DETR in your research or development work, please cite the
|
|||||||
|
|
||||||
We would like to acknowledge Baidu and the [PaddlePaddle](https://github.com/PaddlePaddle/PaddleDetection) team for creating and maintaining this valuable resource for the computer vision community. Their contribution to the field with the development of the Vision Transformers-based real-time object detector, RT-DETR, is greatly appreciated.
|
We would like to acknowledge Baidu and the [PaddlePaddle](https://github.com/PaddlePaddle/PaddleDetection) team for creating and maintaining this valuable resource for the computer vision community. Their contribution to the field with the development of the Vision Transformers-based real-time object detector, RT-DETR, is greatly appreciated.
|
||||||
|
|
||||||
*Keywords: RT-DETR, Transformer, ViT, Vision Transformers, Baidu RT-DETR, PaddlePaddle, Paddle Paddle RT-DETR, real-time object detection, Vision Transformers-based object detection, pre-trained PaddlePaddle RT-DETR models, Baidu's RT-DETR usage, Ultralytics Python API*
|
*Keywords: RT-DETR, Transformer, ViT, Vision Transformers, Baidu RT-DETR, PaddlePaddle, Paddle Paddle RT-DETR, real-time object detection, Vision Transformers-based object detection, pre-trained PaddlePaddle RT-DETR models, Baidu's RT-DETR usage, Ultralytics Python API*
|
||||||
|
|||||||
@ -37,10 +37,10 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
|
|||||||
Segment image with given prompts.
|
Segment image with given prompts.
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import SAM
|
from ultralytics import SAM
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = SAM('sam_b.pt')
|
model = SAM('sam_b.pt')
|
||||||
|
|
||||||
@ -59,10 +59,10 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
|
|||||||
Segment the whole image.
|
Segment the whole image.
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import SAM
|
from ultralytics import SAM
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = SAM('sam_b.pt')
|
model = SAM('sam_b.pt')
|
||||||
|
|
||||||
@ -73,7 +73,7 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
|
|||||||
model('path/to/image.jpg')
|
model('path/to/image.jpg')
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Run inference with a SAM model
|
# Run inference with a SAM model
|
||||||
yolo predict model=sam_b.pt source=path/to/image.jpg
|
yolo predict model=sam_b.pt source=path/to/image.jpg
|
||||||
@ -86,7 +86,7 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
|
|||||||
This way you can set image once and run prompts inference multiple times without running image encoder multiple times.
|
This way you can set image once and run prompts inference multiple times without running image encoder multiple times.
|
||||||
|
|
||||||
=== "Prompt inference"
|
=== "Prompt inference"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics.models.sam import Predictor as SAMPredictor
|
from ultralytics.models.sam import Predictor as SAMPredictor
|
||||||
|
|
||||||
@ -106,7 +106,7 @@ The Segment Anything Model can be employed for a multitude of downstream tasks t
|
|||||||
Segment everything with additional args.
|
Segment everything with additional args.
|
||||||
|
|
||||||
=== "Segment everything"
|
=== "Segment everything"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics.models.sam import Predictor as SAMPredictor
|
from ultralytics.models.sam import Predictor as SAMPredictor
|
||||||
|
|
||||||
@ -207,7 +207,7 @@ If you find SAM useful in your research or development work, please consider cit
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{kirillov2023segment,
|
@misc{kirillov2023segment,
|
||||||
title={Segment Anything},
|
title={Segment Anything},
|
||||||
author={Alexander Kirillov and Eric Mintun and Nikhila Ravi and Hanzi Mao and Chloe Rolland and Laura Gustafson and Tete Xiao and Spencer Whitehead and Alexander C. Berg and Wan-Yen Lo and Piotr Dollár and Ross Girshick},
|
author={Alexander Kirillov and Eric Mintun and Nikhila Ravi and Hanzi Mao and Chloe Rolland and Laura Gustafson and Tete Xiao and Spencer Whitehead and Alexander C. Berg and Wan-Yen Lo and Piotr Dollár and Ross Girshick},
|
||||||
year={2023},
|
year={2023},
|
||||||
eprint={2304.02643},
|
eprint={2304.02643},
|
||||||
@ -218,4 +218,4 @@ If you find SAM useful in your research or development work, please consider cit
|
|||||||
|
|
||||||
We would like to express our gratitude to Meta AI for creating and maintaining this valuable resource for the computer vision community.
|
We would like to express our gratitude to Meta AI for creating and maintaining this valuable resource for the computer vision community.
|
||||||
|
|
||||||
*keywords: Segment Anything, Segment Anything Model, SAM, Meta SAM, image segmentation, promptable segmentation, zero-shot performance, SA-1B dataset, advanced architecture, auto-annotation, Ultralytics, pre-trained models, SAM base, SAM large, instance segmentation, computer vision, AI, artificial intelligence, machine learning, data annotation, segmentation masks, detection model, YOLO detection model, bibtex, Meta AI.*
|
*keywords: Segment Anything, Segment Anything Model, SAM, Meta SAM, image segmentation, promptable segmentation, zero-shot performance, SA-1B dataset, advanced architecture, auto-annotation, Ultralytics, pre-trained models, SAM base, SAM large, instance segmentation, computer vision, AI, artificial intelligence, machine learning, data annotation, segmentation masks, detection model, YOLO detection model, bibtex, Meta AI.*
|
||||||
|
|||||||
@ -106,4 +106,4 @@ If you employ YOLO-NAS in your research or development work, please cite SuperGr
|
|||||||
|
|
||||||
We express our gratitude to Deci AI's [SuperGradients](https://github.com/Deci-AI/super-gradients/) team for their efforts in creating and maintaining this valuable resource for the computer vision community. We believe YOLO-NAS, with its innovative architecture and superior object detection capabilities, will become a critical tool for developers and researchers alike.
|
We express our gratitude to Deci AI's [SuperGradients](https://github.com/Deci-AI/super-gradients/) team for their efforts in creating and maintaining this valuable resource for the computer vision community. We believe YOLO-NAS, with its innovative architecture and superior object detection capabilities, will become a critical tool for developers and researchers alike.
|
||||||
|
|
||||||
*Keywords: YOLO-NAS, Deci AI, object detection, deep learning, neural architecture search, Ultralytics Python API, YOLO model, SuperGradients, pre-trained models, quantization-friendly basic block, advanced training schemes, post-training quantization, AutoNAC optimization, COCO, Objects365, Roboflow 100*
|
*Keywords: YOLO-NAS, Deci AI, object detection, deep learning, neural architecture search, Ultralytics Python API, YOLO model, SuperGradients, pre-trained models, quantization-friendly basic block, advanced training schemes, post-training quantization, AutoNAC optimization, COCO, Objects365, Roboflow 100*
|
||||||
|
|||||||
@ -77,4 +77,4 @@ If you use YOLOv3 in your research, please cite the original YOLO papers and the
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Thank you to Joseph Redmon and Ali Farhadi for developing the original YOLOv3.
|
Thank you to Joseph Redmon and Ali Farhadi for developing the original YOLOv3.
|
||||||
|
|||||||
@ -55,7 +55,7 @@ We would like to acknowledge the YOLOv4 authors for their significant contributi
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{bochkovskiy2020yolov4,
|
@misc{bochkovskiy2020yolov4,
|
||||||
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
|
title={YOLOv4: Optimal Speed and Accuracy of Object Detection},
|
||||||
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
|
author={Alexey Bochkovskiy and Chien-Yao Wang and Hong-Yuan Mark Liao},
|
||||||
year={2020},
|
year={2020},
|
||||||
eprint={2004.10934},
|
eprint={2004.10934},
|
||||||
@ -64,4 +64,4 @@ We would like to acknowledge the YOLOv4 authors for their significant contributi
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
The original YOLOv4 paper can be found on [arXiv](https://arxiv.org/pdf/2004.10934.pdf). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/AlexeyAB/darknet). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
The original YOLOv4 paper can be found on [arXiv](https://arxiv.org/pdf/2004.10934.pdf). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/AlexeyAB/darknet). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
||||||
|
|||||||
@ -86,4 +86,4 @@ If you use YOLOv5 or YOLOv5u in your research, please cite the Ultralytics YOLOv
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Special thanks to Glenn Jocher and the Ultralytics team for their work on developing and maintaining the YOLOv5 and YOLOv5u models.
|
Special thanks to Glenn Jocher and the Ultralytics team for their work on developing and maintaining the YOLOv5 and YOLOv5u models.
|
||||||
|
|||||||
@ -70,7 +70,7 @@ We would like to acknowledge the authors for their significant contributions in
|
|||||||
|
|
||||||
```bibtex
|
```bibtex
|
||||||
@misc{li2023yolov6,
|
@misc{li2023yolov6,
|
||||||
title={YOLOv6 v3.0: A Full-Scale Reloading},
|
title={YOLOv6 v3.0: A Full-Scale Reloading},
|
||||||
author={Chuyi Li and Lulu Li and Yifei Geng and Hongliang Jiang and Meng Cheng and Bo Zhang and Zaidan Ke and Xiaoming Xu and Xiangxiang Chu},
|
author={Chuyi Li and Lulu Li and Yifei Geng and Hongliang Jiang and Meng Cheng and Bo Zhang and Zaidan Ke and Xiaoming Xu and Xiangxiang Chu},
|
||||||
year={2023},
|
year={2023},
|
||||||
eprint={2301.05586},
|
eprint={2301.05586},
|
||||||
@ -79,4 +79,4 @@ We would like to acknowledge the authors for their significant contributions in
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
The original YOLOv6 paper can be found on [arXiv](https://arxiv.org/abs/2301.05586). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/meituan/YOLOv6). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
The original YOLOv6 paper can be found on [arXiv](https://arxiv.org/abs/2301.05586). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/meituan/YOLOv6). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
||||||
|
|||||||
@ -58,4 +58,4 @@ We would like to acknowledge the YOLOv7 authors for their significant contributi
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
The original YOLOv7 paper can be found on [arXiv](https://arxiv.org/pdf/2207.02696.pdf). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/WongKinYiu/yolov7). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
The original YOLOv7 paper can be found on [arXiv](https://arxiv.org/pdf/2207.02696.pdf). The authors have made their work publicly available, and the codebase can be accessed on [GitHub](https://github.com/WongKinYiu/yolov7). We appreciate their efforts in advancing the field and making their work accessible to the broader community.
|
||||||
|
|||||||
@ -112,4 +112,4 @@ If you use the YOLOv8 model or any other software from this repository in your w
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
Please note that the DOI is pending and will be added to the citation once it is available. The usage of the software is in accordance with the AGPL-3.0 license.
|
Please note that the DOI is pending and will be added to the citation once it is available. The usage of the software is in accordance with the AGPL-3.0 license.
|
||||||
|
|||||||
@ -25,15 +25,15 @@ full list of export arguments.
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics.utils.benchmarks import benchmark
|
from ultralytics.utils.benchmarks import benchmark
|
||||||
|
|
||||||
# Benchmark on GPU
|
# Benchmark on GPU
|
||||||
benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
|
benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
|
yolo benchmark model=yolov8n.pt data='coco8.yaml' imgsz=640 half=False device=0
|
||||||
```
|
```
|
||||||
|
|||||||
@ -23,19 +23,19 @@ export arguments.
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load an official model
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
model = YOLO('path/to/best.pt') # load a custom trained
|
model = YOLO('path/to/best.pt') # load a custom trained
|
||||||
|
|
||||||
# Export the model
|
# Export the model
|
||||||
model.export(format='onnx')
|
model.export(format='onnx')
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo export model=yolov8n.pt format=onnx # export official model
|
yolo export model=yolov8n.pt format=onnx # export official model
|
||||||
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
yolo export model=path/to/best.pt format=onnx # export custom trained model
|
||||||
@ -85,4 +85,4 @@ i.e. `format='onnx'` or `format='engine'`.
|
|||||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||||
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
| [ncnn](https://github.com/Tencent/ncnn) | `ncnn` | `yolov8n_ncnn_model/` | ✅ | `imgsz`, `half` |
|
||||||
|
|||||||
@ -65,4 +65,4 @@ or `accuracy_top5` metrics (for classification), and the inference time in milli
|
|||||||
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||||
their specific use case based on their requirements for speed and accuracy.
|
their specific use case based on their requirements for speed and accuracy.
|
||||||
|
|
||||||
[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
|
[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
|
||||||
|
|||||||
@ -21,7 +21,7 @@ passing `stream=True` in the predictor's call method.
|
|||||||
|
|
||||||
# Run batched inference on a list of images
|
# Run batched inference on a list of images
|
||||||
results = model(['im1.jpg', 'im2.jpg']) # return a list of Results objects
|
results = model(['im1.jpg', 'im2.jpg']) # return a list of Results objects
|
||||||
|
|
||||||
# Process results list
|
# Process results list
|
||||||
for result in results:
|
for result in results:
|
||||||
boxes = result.boxes # Boxes object for bbox outputs
|
boxes = result.boxes # Boxes object for bbox outputs
|
||||||
@ -39,7 +39,7 @@ passing `stream=True` in the predictor's call method.
|
|||||||
|
|
||||||
# Run batched inference on a list of images
|
# Run batched inference on a list of images
|
||||||
results = model(['im1.jpg', 'im2.jpg'], stream=True) # return a generator of Results objects
|
results = model(['im1.jpg', 'im2.jpg'], stream=True) # return a generator of Results objects
|
||||||
|
|
||||||
# Process results generator
|
# Process results generator
|
||||||
for result in results:
|
for result in results:
|
||||||
boxes = result.boxes # Boxes object for bbox outputs
|
boxes = result.boxes # Boxes object for bbox outputs
|
||||||
@ -65,7 +65,7 @@ YOLOv8 can process different types of input sources for inference, as shown in t
|
|||||||
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` of `uint8 (0-255)` | HWC format with BGR channels. |
|
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` of `uint8 (0-255)` | HWC format with BGR channels. |
|
||||||
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` of `uint8 (0-255)` | HWC format with BGR channels. |
|
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` of `uint8 (0-255)` | HWC format with BGR channels. |
|
||||||
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` of `float32 (0.0-1.0)` | BCHW format with RGB channels. |
|
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` of `float32 (0.0-1.0)` | BCHW format with RGB channels. |
|
||||||
| CSV | `'sources.csv'` | `str` or `Path` | CSV file containing paths to images, videos, or directories. |
|
| CSV | `'sources.csv'` | `str` or `Path` | CSV file containing paths to images, videos, or directories. |
|
||||||
| video ✅ | `'video.mp4'` | `str` or `Path` | Video file in formats like MP4, AVI, etc. |
|
| video ✅ | `'video.mp4'` | `str` or `Path` | Video file in formats like MP4, AVI, etc. |
|
||||||
| directory ✅ | `'path/'` | `str` or `Path` | Path to a directory containing images or videos. |
|
| directory ✅ | `'path/'` | `str` or `Path` | Path to a directory containing images or videos. |
|
||||||
| glob ✅ | `'path/*.jpg'` | `str` | Glob pattern to match multiple files. Use the `*` character as a wildcard. |
|
| glob ✅ | `'path/*.jpg'` | `str` | Glob pattern to match multiple files. Use the `*` character as a wildcard. |
|
||||||
@ -77,204 +77,204 @@ Below are code examples for using each source type:
|
|||||||
!!! example "Prediction sources"
|
!!! example "Prediction sources"
|
||||||
|
|
||||||
=== "image"
|
=== "image"
|
||||||
Run inference on an image file.
|
Run inference on an image file.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define path to the image file
|
# Define path to the image file
|
||||||
source = 'path/to/image.jpg'
|
source = 'path/to/image.jpg'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "screenshot"
|
=== "screenshot"
|
||||||
Run inference on the current screen content as a screenshot.
|
Run inference on the current screen content as a screenshot.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define current screenshot as source
|
# Define current screenshot as source
|
||||||
source = 'screen'
|
source = 'screen'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "URL"
|
=== "URL"
|
||||||
Run inference on an image or video hosted remotely via URL.
|
Run inference on an image or video hosted remotely via URL.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define remote image or video URL
|
# Define remote image or video URL
|
||||||
source = 'https://ultralytics.com/images/bus.jpg'
|
source = 'https://ultralytics.com/images/bus.jpg'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "PIL"
|
=== "PIL"
|
||||||
Run inference on an image opened with Python Imaging Library (PIL).
|
Run inference on an image opened with Python Imaging Library (PIL).
|
||||||
```python
|
```python
|
||||||
from PIL import Image
|
from PIL import Image
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Open an image using PIL
|
# Open an image using PIL
|
||||||
source = Image.open('path/to/image.jpg')
|
source = Image.open('path/to/image.jpg')
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "OpenCV"
|
=== "OpenCV"
|
||||||
Run inference on an image read with OpenCV.
|
Run inference on an image read with OpenCV.
|
||||||
```python
|
```python
|
||||||
import cv2
|
import cv2
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Read an image using OpenCV
|
# Read an image using OpenCV
|
||||||
source = cv2.imread('path/to/image.jpg')
|
source = cv2.imread('path/to/image.jpg')
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "numpy"
|
=== "numpy"
|
||||||
Run inference on an image represented as a numpy array.
|
Run inference on an image represented as a numpy array.
|
||||||
```python
|
```python
|
||||||
import numpy as np
|
import numpy as np
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Create a random numpy array of HWC shape (640, 640, 3) with values in range [0, 255] and type uint8
|
# Create a random numpy array of HWC shape (640, 640, 3) with values in range [0, 255] and type uint8
|
||||||
source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
|
source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8')
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "torch"
|
=== "torch"
|
||||||
Run inference on an image represented as a PyTorch tensor.
|
Run inference on an image represented as a PyTorch tensor.
|
||||||
```python
|
```python
|
||||||
import torch
|
import torch
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
|
# Create a random torch tensor of BCHW shape (1, 3, 640, 640) with values in range [0, 1] and type float32
|
||||||
source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
|
source = torch.rand(1, 3, 640, 640, dtype=torch.float32)
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "CSV"
|
=== "CSV"
|
||||||
Run inference on a collection of images, URLs, videos and directories listed in a CSV file.
|
Run inference on a collection of images, URLs, videos and directories listed in a CSV file.
|
||||||
```python
|
```python
|
||||||
import torch
|
import torch
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define a path to a CSV file with images, URLs, videos and directories
|
# Define a path to a CSV file with images, URLs, videos and directories
|
||||||
source = 'path/to/file.csv'
|
source = 'path/to/file.csv'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source) # list of Results objects
|
results = model(source) # list of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "video"
|
=== "video"
|
||||||
Run inference on a video file. By using `stream=True`, you can create a generator of Results objects to reduce memory usage.
|
Run inference on a video file. By using `stream=True`, you can create a generator of Results objects to reduce memory usage.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define path to video file
|
# Define path to video file
|
||||||
source = 'path/to/video.mp4'
|
source = 'path/to/video.mp4'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source, stream=True) # generator of Results objects
|
results = model(source, stream=True) # generator of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "directory"
|
=== "directory"
|
||||||
Run inference on all images and videos in a directory. To also capture images and videos in subdirectories use a glob pattern, i.e. `path/to/dir/**/*`.
|
Run inference on all images and videos in a directory. To also capture images and videos in subdirectories use a glob pattern, i.e. `path/to/dir/**/*`.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define path to directory containing images and videos for inference
|
# Define path to directory containing images and videos for inference
|
||||||
source = 'path/to/dir'
|
source = 'path/to/dir'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source, stream=True) # generator of Results objects
|
results = model(source, stream=True) # generator of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "glob"
|
=== "glob"
|
||||||
Run inference on all images and videos that match a glob expression with `*` characters.
|
Run inference on all images and videos that match a glob expression with `*` characters.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define a glob search for all JPG files in a directory
|
# Define a glob search for all JPG files in a directory
|
||||||
source = 'path/to/dir/*.jpg'
|
source = 'path/to/dir/*.jpg'
|
||||||
|
|
||||||
# OR define a recursive glob search for all JPG files including subdirectories
|
# OR define a recursive glob search for all JPG files including subdirectories
|
||||||
source = 'path/to/dir/**/*.jpg'
|
source = 'path/to/dir/**/*.jpg'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source, stream=True) # generator of Results objects
|
results = model(source, stream=True) # generator of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "YouTube"
|
=== "YouTube"
|
||||||
Run inference on a YouTube video. By using `stream=True`, you can create a generator of Results objects to reduce memory usage for long videos.
|
Run inference on a YouTube video. By using `stream=True`, you can create a generator of Results objects to reduce memory usage for long videos.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define source as YouTube video URL
|
# Define source as YouTube video URL
|
||||||
source = 'https://youtu.be/Zgi9g1ksQHc'
|
source = 'https://youtu.be/Zgi9g1ksQHc'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source, stream=True) # generator of Results objects
|
results = model(source, stream=True) # generator of Results objects
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "Stream"
|
=== "Stream"
|
||||||
Run inference on remote streaming sources using RTSP, RTMP, and IP address protocols.
|
Run inference on remote streaming sources using RTSP, RTMP, and IP address protocols.
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a pretrained YOLOv8n model
|
# Load a pretrained YOLOv8n model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Define source as RTSP, RTMP or IP streaming address
|
# Define source as RTSP, RTMP or IP streaming address
|
||||||
source = 'rtsp://example.com/media.mp4'
|
source = 'rtsp://example.com/media.mp4'
|
||||||
|
|
||||||
# Run inference on the source
|
# Run inference on the source
|
||||||
results = model(source, stream=True) # generator of Results objects
|
results = model(source, stream=True) # generator of Results objects
|
||||||
```
|
```
|
||||||
@ -417,7 +417,7 @@ operations are cached, meaning they're only calculated once per object, and thos
|
|||||||
masks = results[0].masks # Masks object
|
masks = results[0].masks # Masks object
|
||||||
masks.xy # x, y segments (pixels), List[segment] * N
|
masks.xy # x, y segments (pixels), List[segment] * N
|
||||||
masks.xyn # x, y segments (normalized), List[segment] * N
|
masks.xyn # x, y segments (normalized), List[segment] * N
|
||||||
masks.data # raw masks tensor, (N, H, W) or masks.masks
|
masks.data # raw masks tensor, (N, H, W) or masks.masks
|
||||||
```
|
```
|
||||||
|
|
||||||
### Keypoints
|
### Keypoints
|
||||||
@ -432,7 +432,7 @@ operations are cached, meaning they're only calculated once per object, and thos
|
|||||||
keypoints.xy # x, y keypoints (pixels), (num_dets, num_kpts, 2/3), the last dimension can be 2 or 3, depends the model.
|
keypoints.xy # x, y keypoints (pixels), (num_dets, num_kpts, 2/3), the last dimension can be 2 or 3, depends the model.
|
||||||
keypoints.xyn # x, y keypoints (normalized), (num_dets, num_kpts, 2/3)
|
keypoints.xyn # x, y keypoints (normalized), (num_dets, num_kpts, 2/3)
|
||||||
keypoints.conf # confidence score(num_dets, num_kpts) of each keypoint if the last dimension is 3.
|
keypoints.conf # confidence score(num_dets, num_kpts) of each keypoint if the last dimension is 3.
|
||||||
keypoints.data # raw keypoints tensor, (num_dets, num_kpts, 2/3)
|
keypoints.data # raw keypoints tensor, (num_dets, num_kpts, 2/3)
|
||||||
```
|
```
|
||||||
|
|
||||||
### probs
|
### probs
|
||||||
@ -448,7 +448,7 @@ operations are cached, meaning they're only calculated once per object, and thos
|
|||||||
probs.top1 # The top1 indices of classification, a value with Int type.
|
probs.top1 # The top1 indices of classification, a value with Int type.
|
||||||
probs.top5conf # The top5 scores of classification, a tensor with shape (5, ).
|
probs.top5conf # The top5 scores of classification, a tensor with shape (5, ).
|
||||||
probs.top1conf # The top1 scores of classification. a value with torch.tensor type.
|
probs.top1conf # The top1 scores of classification. a value with torch.tensor type.
|
||||||
keypoints.data # raw probs tensor, (num_class, )
|
keypoints.data # raw probs tensor, (num_class, )
|
||||||
```
|
```
|
||||||
|
|
||||||
Class reference documentation for `Results` module and its components can be found [here](../reference/engine/results.md)
|
Class reference documentation for `Results` module and its components can be found [here](../reference/engine/results.md)
|
||||||
@ -489,37 +489,37 @@ Here's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video f
|
|||||||
```python
|
```python
|
||||||
import cv2
|
import cv2
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load the YOLOv8 model
|
# Load the YOLOv8 model
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Open the video file
|
# Open the video file
|
||||||
video_path = "path/to/your/video/file.mp4"
|
video_path = "path/to/your/video/file.mp4"
|
||||||
cap = cv2.VideoCapture(video_path)
|
cap = cv2.VideoCapture(video_path)
|
||||||
|
|
||||||
# Loop through the video frames
|
# Loop through the video frames
|
||||||
while cap.isOpened():
|
while cap.isOpened():
|
||||||
# Read a frame from the video
|
# Read a frame from the video
|
||||||
success, frame = cap.read()
|
success, frame = cap.read()
|
||||||
|
|
||||||
if success:
|
if success:
|
||||||
# Run YOLOv8 inference on the frame
|
# Run YOLOv8 inference on the frame
|
||||||
results = model(frame)
|
results = model(frame)
|
||||||
|
|
||||||
# Visualize the results on the frame
|
# Visualize the results on the frame
|
||||||
annotated_frame = results[0].plot()
|
annotated_frame = results[0].plot()
|
||||||
|
|
||||||
# Display the annotated frame
|
# Display the annotated frame
|
||||||
cv2.imshow("YOLOv8 Inference", annotated_frame)
|
cv2.imshow("YOLOv8 Inference", annotated_frame)
|
||||||
|
|
||||||
# Break the loop if 'q' is pressed
|
# Break the loop if 'q' is pressed
|
||||||
if cv2.waitKey(1) & 0xFF == ord("q"):
|
if cv2.waitKey(1) & 0xFF == ord("q"):
|
||||||
break
|
break
|
||||||
else:
|
else:
|
||||||
# Break the loop if the end of the video is reached
|
# Break the loop if the end of the video is reached
|
||||||
break
|
break
|
||||||
|
|
||||||
# Release the video capture object and close the display window
|
# Release the video capture object and close the display window
|
||||||
cap.release()
|
cap.release()
|
||||||
cv2.destroyAllWindows()
|
cv2.destroyAllWindows()
|
||||||
```
|
```
|
||||||
|
|||||||
@ -27,21 +27,21 @@ Use a trained YOLOv8n/YOLOv8n-seg model to run tracker on video streams.
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load an official detection model
|
model = YOLO('yolov8n.pt') # load an official detection model
|
||||||
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
|
model = YOLO('yolov8n-seg.pt') # load an official segmentation model
|
||||||
model = YOLO('path/to/best.pt') # load a custom model
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
# Track with the model
|
# Track with the model
|
||||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
|
||||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" # official detection model
|
||||||
yolo track model=yolov8n-seg.pt source=... # official segmentation model
|
yolo track model=yolov8n-seg.pt source=... # official segmentation model
|
||||||
@ -62,15 +62,15 @@ to [predict page](https://docs.ultralytics.com/modes/predict/).
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", conf=0.3, iou=0.5, show=True)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
||||||
|
|
||||||
@ -84,18 +84,18 @@ any configurations(expect the `tracker_type`) you need to.
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
|
results = model.track(source="https://youtu.be/Zgi9g1ksQHc", tracker='custom_tracker.yaml')
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
|
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" tracker='custom_tracker.yaml'
|
||||||
```
|
```
|
||||||
|
|
||||||
Please refer to [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers)
|
Please refer to [ultralytics/cfg/trackers](https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/trackers)
|
||||||
page
|
page
|
||||||
|
|||||||
@ -21,20 +21,20 @@ Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. See Argum
|
|||||||
Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
|
Device is determined automatically. If a GPU is available then it will be used, otherwise training will start on CPU.
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.yaml') # build a new model from YAML
|
model = YOLO('yolov8n.yaml') # build a new model from YAML
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
|
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
|
||||||
|
|
||||||
# Train the model
|
# Train the model
|
||||||
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
model.train(data='coco128.yaml', epochs=100, imgsz=640)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Build a new model from YAML and start training from scratch
|
# Build a new model from YAML and start training from scratch
|
||||||
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
yolo detect train data=coco128.yaml model=yolov8n.yaml epochs=100 imgsz=640
|
||||||
@ -53,18 +53,18 @@ The training device can be specified using the `device` argument. If no argument
|
|||||||
!!! example "Multi-GPU Training Example"
|
!!! example "Multi-GPU Training Example"
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model with 2 GPUs
|
# Train the model with 2 GPUs
|
||||||
model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
|
model.train(data='coco128.yaml', epochs=100, imgsz=640, device=[0, 1])
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Start training from a pretrained *.pt model using GPUs 0 and 1
|
# Start training from a pretrained *.pt model using GPUs 0 and 1
|
||||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=0,1
|
||||||
@ -79,18 +79,18 @@ To enable training on Apple M1 and M2 chips, you should specify 'mps' as your de
|
|||||||
!!! example "MPS Training Example"
|
!!! example "MPS Training Example"
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
|
||||||
|
|
||||||
# Train the model with 2 GPUs
|
# Train the model with 2 GPUs
|
||||||
model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
|
model.train(data='coco128.yaml', epochs=100, imgsz=640, device='mps')
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Start training from a pretrained *.pt model using GPUs 0 and 1
|
# Start training from a pretrained *.pt model using GPUs 0 and 1
|
||||||
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
|
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640 device=mps
|
||||||
@ -111,18 +111,18 @@ Below is an example of how to resume an interrupted training using Python and vi
|
|||||||
!!! example "Resume Training Example"
|
!!! example "Resume Training Example"
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('path/to/last.pt') # load a partially trained model
|
model = YOLO('path/to/last.pt') # load a partially trained model
|
||||||
|
|
||||||
# Resume training
|
# Resume training
|
||||||
model.train(resume=True)
|
model.train(resume=True)
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Resume an interrupted training
|
# Resume an interrupted training
|
||||||
yolo train resume model=path/to/last.pt
|
yolo train resume model=path/to/last.pt
|
||||||
@ -239,4 +239,4 @@ tensorboard --logdir ultralytics/runs # replace with 'runs' directory
|
|||||||
|
|
||||||
This will load TensorBoard and direct it to the directory where your training logs are saved.
|
This will load TensorBoard and direct it to the directory where your training logs are saved.
|
||||||
|
|
||||||
After setting up your logger, you can then proceed with your model training. All training metrics will be automatically logged in your chosen platform, and you can access these logs to monitor your model's performance over time, compare different models, and identify areas for improvement.
|
After setting up your logger, you can then proceed with your model training. All training metrics will be automatically logged in your chosen platform, and you can access these logs to monitor your model's performance over time, compare different models, and identify areas for improvement.
|
||||||
|
|||||||
@ -19,14 +19,14 @@ Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need
|
|||||||
!!! example ""
|
!!! example ""
|
||||||
|
|
||||||
=== "Python"
|
=== "Python"
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Load a model
|
# Load a model
|
||||||
model = YOLO('yolov8n.pt') # load an official model
|
model = YOLO('yolov8n.pt') # load an official model
|
||||||
model = YOLO('path/to/best.pt') # load a custom model
|
model = YOLO('path/to/best.pt') # load a custom model
|
||||||
|
|
||||||
# Validate the model
|
# Validate the model
|
||||||
metrics = model.val() # no arguments needed, dataset and settings remembered
|
metrics = model.val() # no arguments needed, dataset and settings remembered
|
||||||
metrics.box.map # map50-95
|
metrics.box.map # map50-95
|
||||||
@ -35,7 +35,7 @@ Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need
|
|||||||
metrics.box.maps # a list contains map50-95 of each category
|
metrics.box.maps # a list contains map50-95 of each category
|
||||||
```
|
```
|
||||||
=== "CLI"
|
=== "CLI"
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
yolo detect val model=yolov8n.pt # val official model
|
yolo detect val model=yolov8n.pt # val official model
|
||||||
yolo detect val model=path/to/best.pt # val custom model
|
yolo detect val model=path/to/best.pt # val custom model
|
||||||
@ -61,4 +61,4 @@ Validation settings for YOLO models refer to the various hyperparameters and con
|
|||||||
| `plots` | `False` | show plots during training |
|
| `plots` | `False` | show plots during training |
|
||||||
| `rect` | `False` | rectangular val with each batch collated for minimum padding |
|
| `rect` | `False` | rectangular val with each batch collated for minimum padding |
|
||||||
| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
|
| `split` | `val` | dataset split to use for validation, i.e. 'val', 'test' or 'train' |
|
||||||
|
|
|
|
||||||
|
|||||||
@ -19,7 +19,7 @@ Ultralytics provides various installation methods including pip, conda, and Dock
|
|||||||
# Install the ultralytics package using pip
|
# Install the ultralytics package using pip
|
||||||
pip install ultralytics
|
pip install ultralytics
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "Conda install"
|
=== "Conda install"
|
||||||
Conda is an alternative package manager to pip which may also be used for installation. Visit Anaconda for more details at [https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics). Ultralytics feedstock repository for updating the conda package is at [https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/).
|
Conda is an alternative package manager to pip which may also be used for installation. Visit Anaconda for more details at [https://anaconda.org/conda-forge/ultralytics](https://anaconda.org/conda-forge/ultralytics). Ultralytics feedstock repository for updating the conda package is at [https://github.com/conda-forge/ultralytics-feedstock/](https://github.com/conda-forge/ultralytics-feedstock/).
|
||||||
|
|
||||||
@ -30,16 +30,16 @@ Ultralytics provides various installation methods including pip, conda, and Dock
|
|||||||
# Install the ultralytics package using conda
|
# Install the ultralytics package using conda
|
||||||
conda install ultralytics
|
conda install ultralytics
|
||||||
```
|
```
|
||||||
|
|
||||||
=== "Git clone"
|
=== "Git clone"
|
||||||
Clone the `ultralytics` repository if you are interested in contributing to the development or wish to experiment with the latest source code. After cloning, navigate into the directory and install the package in editable mode `-e` using pip.
|
Clone the `ultralytics` repository if you are interested in contributing to the development or wish to experiment with the latest source code. After cloning, navigate into the directory and install the package in editable mode `-e` using pip.
|
||||||
```bash
|
```bash
|
||||||
# Clone the ultralytics repository
|
# Clone the ultralytics repository
|
||||||
git clone https://github.com/ultralytics/ultralytics
|
git clone https://github.com/ultralytics/ultralytics
|
||||||
|
|
||||||
# Navigate to the cloned directory
|
# Navigate to the cloned directory
|
||||||
cd ultralytics
|
cd ultralytics
|
||||||
|
|
||||||
# Install the package in editable mode for development
|
# Install the package in editable mode for development
|
||||||
pip install -e .
|
pip install -e .
|
||||||
```
|
```
|
||||||
@ -48,27 +48,27 @@ Ultralytics provides various installation methods including pip, conda, and Dock
|
|||||||
Utilize Docker to execute the `ultralytics` package in an isolated container. By employing the official `ultralytics` image from [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics), you can avoid local installation. Below are the commands to get the latest image and execute it:
|
Utilize Docker to execute the `ultralytics` package in an isolated container. By employing the official `ultralytics` image from [Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics), you can avoid local installation. Below are the commands to get the latest image and execute it:
|
||||||
|
|
||||||
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Pulls"></a>
|
<a href="https://hub.docker.com/r/ultralytics/ultralytics"><img src="https://img.shields.io/docker/pulls/ultralytics/ultralytics?logo=docker" alt="Docker Pulls"></a>
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Set image name as a variable
|
# Set image name as a variable
|
||||||
t=ultralytics/ultralytics:latest
|
t=ultralytics/ultralytics:latest
|
||||||
|
|
||||||
# Pull the latest ultralytics image from Docker Hub
|
# Pull the latest ultralytics image from Docker Hub
|
||||||
sudo docker pull $t
|
sudo docker pull $t
|
||||||
|
|
||||||
# Run the ultralytics image in a container with GPU support
|
# Run the ultralytics image in a container with GPU support
|
||||||
sudo docker run -it --ipc=host --gpus all $t
|
sudo docker run -it --ipc=host --gpus all $t
|
||||||
```
|
```
|
||||||
|
|
||||||
The above command initializes a Docker container with the latest `ultralytics` image. The `-it` flag assigns a pseudo-TTY and maintains stdin open, enabling you to interact with the container. The `--ipc=host` flag sets the IPC (Inter-Process Communication) namespace to the host, which is essential for sharing memory between processes. The `--gpus all` flag enables access to all available GPUs inside the container, which is crucial for tasks that require GPU computation.
|
The above command initializes a Docker container with the latest `ultralytics` image. The `-it` flag assigns a pseudo-TTY and maintains stdin open, enabling you to interact with the container. The `--ipc=host` flag sets the IPC (Inter-Process Communication) namespace to the host, which is essential for sharing memory between processes. The `--gpus all` flag enables access to all available GPUs inside the container, which is crucial for tasks that require GPU computation.
|
||||||
|
|
||||||
Note: To work with files on your local machine within the container, use Docker volumes for mounting a local directory into the container:
|
Note: To work with files on your local machine within the container, use Docker volumes for mounting a local directory into the container:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Mount local directory to a directory inside the container
|
# Mount local directory to a directory inside the container
|
||||||
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
|
sudo docker run -it --ipc=host --gpus all -v /path/on/host:/path/in/container $t
|
||||||
```
|
```
|
||||||
|
|
||||||
Alter `/path/on/host` with the directory path on your local machine, and `/path/in/container` with the desired path inside the Docker container for accessibility.
|
Alter `/path/on/host` with the directory path on your local machine, and `/path/in/container` with the desired path inside the Docker container for accessibility.
|
||||||
|
|
||||||
See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that all examples above install all required dependencies.
|
See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that all examples above install all required dependencies.
|
||||||
@ -160,24 +160,111 @@ For example, users can load a model, train it, evaluate its performance on a val
|
|||||||
|
|
||||||
```python
|
```python
|
||||||
from ultralytics import YOLO
|
from ultralytics import YOLO
|
||||||
|
|
||||||
# Create a new YOLO model from scratch
|
# Create a new YOLO model from scratch
|
||||||
model = YOLO('yolov8n.yaml')
|
model = YOLO('yolov8n.yaml')
|
||||||
|
|
||||||
# Load a pretrained YOLO model (recommended for training)
|
# Load a pretrained YOLO model (recommended for training)
|
||||||
model = YOLO('yolov8n.pt')
|
model = YOLO('yolov8n.pt')
|
||||||
|
|
||||||
# Train the model using the 'coco128.yaml' dataset for 3 epochs
|
# Train the model using the 'coco128.yaml' dataset for 3 epochs
|
||||||
results = model.train(data='coco128.yaml', epochs=3)
|
results = model.train(data='coco128.yaml', epochs=3)
|
||||||
|
|
||||||
# Evaluate the model's performance on the validation set
|
# Evaluate the model's performance on the validation set
|
||||||
results = model.val()
|
results = model.val()
|
||||||
|
|
||||||
# Perform object detection on an image using the model
|
# Perform object detection on an image using the model
|
||||||
results = model('https://ultralytics.com/images/bus.jpg')
|
results = model('https://ultralytics.com/images/bus.jpg')
|
||||||
|
|
||||||
# Export the model to ONNX format
|
# Export the model to ONNX format
|
||||||
success = model.export(format='onnx')
|
success = model.export(format='onnx')
|
||||||
```
|
```
|
||||||
|
|
||||||
[Python Guide](usage/python.md){.md-button .md-button--primary}
|
[Python Guide](usage/python.md){.md-button .md-button--primary}
|
||||||
|
|
||||||
|
## Ultralytics Settings
|
||||||
|
|
||||||
|
The Ultralytics library provides a powerful settings management system to enable fine-grained control over your experiments. By making use of the `SettingsManager` housed within the `ultralytics.utils` module, users can readily access and alter their settings. These are stored in a YAML file and can be viewed or modified either directly within the Python environment or via the Command-Line Interface (CLI).
|
||||||
|
|
||||||
|
### Inspecting Settings
|
||||||
|
|
||||||
|
To gain insight into the current configuration of your settings, you can view them directly:
|
||||||
|
|
||||||
|
!!! example "View settings"
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
You can use Python to view your settings. Start by importing the `settings` object from the `ultralytics` module. Print and return settings using the following commands:
|
||||||
|
```python
|
||||||
|
from ultralytics import settings
|
||||||
|
|
||||||
|
# View all settings
|
||||||
|
print(settings)
|
||||||
|
|
||||||
|
# Return a specific setting
|
||||||
|
value = settings['runs_dir']
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
Alternatively, the command-line interface allows you to check your settings with a simple command:
|
||||||
|
```bash
|
||||||
|
yolo settings
|
||||||
|
```
|
||||||
|
|
||||||
|
### Modifying Settings
|
||||||
|
|
||||||
|
Ultralytics allows users to easily modify their settings. Changes can be performed in the following ways:
|
||||||
|
|
||||||
|
!!! example "Update settings"
|
||||||
|
|
||||||
|
=== "Python"
|
||||||
|
Within the Python environment, call the `update` method on the `settings` object to change your settings:
|
||||||
|
```python
|
||||||
|
from ultralytics import settings
|
||||||
|
|
||||||
|
# Update a setting
|
||||||
|
settings.update({'runs_dir': '/path/to/runs'})
|
||||||
|
|
||||||
|
# Update multiple settings
|
||||||
|
settings.update({'runs_dir': '/path/to/runs', 'tensorboard': False})
|
||||||
|
|
||||||
|
# Reset settings to default values
|
||||||
|
settings.reset()
|
||||||
|
```
|
||||||
|
|
||||||
|
=== "CLI"
|
||||||
|
If you prefer using the command-line interface, the following command will allow you to modify your settings:
|
||||||
|
```bash
|
||||||
|
# Update a setting
|
||||||
|
yolo settings runs_dir='/path/to/runs'
|
||||||
|
|
||||||
|
# Update multiple settings
|
||||||
|
yolo settings runs_dir='/path/to/runs' tensorboard=False
|
||||||
|
|
||||||
|
# Reset settings to default values
|
||||||
|
yolo settings reset
|
||||||
|
```
|
||||||
|
|
||||||
|
### Understanding Settings
|
||||||
|
|
||||||
|
The table below provides an overview of the settings available for adjustment within Ultralytics. Each setting is outlined along with an example value, the data type, and a brief description.
|
||||||
|
|
||||||
|
| Name | Example Value | Data Type | Description |
|
||||||
|
|--------------------|-----------------------|-----------|------------------------------------------------------------------------------------------------------------------|
|
||||||
|
| `settings_version` | `'0.0.4'` | `str` | Ultralytics _settings_ version (different from Ultralytics [pip](https://pypi.org/project/ultralytics/) version) |
|
||||||
|
| `datasets_dir` | `'/path/to/datasets'` | `str` | The directory where the datasets are stored |
|
||||||
|
| `weights_dir` | `'/path/to/weights'` | `str` | The directory where the model weights are stored |
|
||||||
|
| `runs_dir` | `'/path/to/runs'` | `str` | The directory where the experiment runs are stored |
|
||||||
|
| `uuid` | `'a1b2c3d4'` | `str` | The unique identifier for the current settings |
|
||||||
|
| `sync` | `True` | `bool` | Whether to sync analytics and crashes to HUB |
|
||||||
|
| `api_key` | `''` | `str` | Ultralytics HUB [API Key](https://hub.ultralytics.com/settings?tab=api+keys) |
|
||||||
|
| `clearml` | `True` | `bool` | Whether to use ClearML logging |
|
||||||
|
| `comet` | `True` | `bool` | Whether to use [Comet ML](https://bit.ly/yolov8-readme-comet) for experiment tracking and visualization |
|
||||||
|
| `dvc` | `True` | `bool` | Whether to use DVC for version control |
|
||||||
|
| `hub` | `True` | `bool` | Whether to use [Ultralytics HUB](https://hub.ultralytics.com) integration |
|
||||||
|
| `mlflow` | `True` | `bool` | Whether to use MLFlow for experiment tracking |
|
||||||
|
| `neptune` | `True` | `bool` | Whether to use Neptune for experiment tracking |
|
||||||
|
| `raytune` | `True` | `bool` | Whether to use Ray Tune for hyperparameter tuning |
|
||||||
|
| `tensorboard` | `True` | `bool` | Whether to use TensorBoard for visualization |
|
||||||
|
| `wandb` | `True` | `bool` | Whether to use Weights & Biases logging |
|
||||||
|
|
||||||
|
As you navigate through your projects or experiments, be sure to revisit these settings to ensure that they are optimally configured for your needs.
|
||||||
|
|||||||
@ -18,9 +18,9 @@ keywords: Ultralytics, YOLO, Configuration, cfg2dict, handle_deprecation, merge_
|
|||||||
### ::: ultralytics.cfg._handle_deprecation
|
### ::: ultralytics.cfg._handle_deprecation
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|
||||||
## check_cfg_mismatch
|
## check_dict_alignment
|
||||||
---
|
---
|
||||||
### ::: ultralytics.cfg.check_cfg_mismatch
|
### ::: ultralytics.cfg.check_dict_alignment
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|
||||||
## merge_equals_args
|
## merge_equals_args
|
||||||
@ -38,6 +38,16 @@ keywords: Ultralytics, YOLO, Configuration, cfg2dict, handle_deprecation, merge_
|
|||||||
### ::: ultralytics.cfg.handle_yolo_settings
|
### ::: ultralytics.cfg.handle_yolo_settings
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|
||||||
|
## parse_key_value_pair
|
||||||
|
---
|
||||||
|
### ::: ultralytics.cfg.parse_key_value_pair
|
||||||
|
<br><br>
|
||||||
|
|
||||||
|
## smart_value
|
||||||
|
---
|
||||||
|
### ::: ultralytics.cfg.smart_value
|
||||||
|
<br><br>
|
||||||
|
|
||||||
## entrypoint
|
## entrypoint
|
||||||
---
|
---
|
||||||
### ::: ultralytics.cfg.entrypoint
|
### ::: ultralytics.cfg.entrypoint
|
||||||
@ -46,4 +56,4 @@ keywords: Ultralytics, YOLO, Configuration, cfg2dict, handle_deprecation, merge_
|
|||||||
## copy_default_cfg
|
## copy_default_cfg
|
||||||
---
|
---
|
||||||
### ::: ultralytics.cfg.copy_default_cfg
|
### ::: ultralytics.cfg.copy_default_cfg
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, Auto-Annotate, Machine Learning, AI, Annotation, Data Pro
|
|||||||
## auto_annotate
|
## auto_annotate
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.annotator.auto_annotate
|
### ::: ultralytics.data.annotator.auto_annotate
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -96,4 +96,4 @@ keywords: Ultralytics, Data Augmentation, BaseTransform, MixUp, RandomHSV, Lette
|
|||||||
## classify_albumentations
|
## classify_albumentations
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.augment.classify_albumentations
|
### ::: ultralytics.data.augment.classify_albumentations
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, docs, BaseDataset, data manipulation, dataset creation
|
|||||||
## BaseDataset
|
## BaseDataset
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.base.BaseDataset
|
### ::: ultralytics.data.base.BaseDataset
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -36,4 +36,4 @@ keywords: Ultralytics, YOLO v3, Data build, DataLoader, InfiniteDataLoader, seed
|
|||||||
## load_inference_source
|
## load_inference_source
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.build.load_inference_source
|
### ::: ultralytics.data.build.load_inference_source
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -31,4 +31,4 @@ keywords: Ultralytics, Data Converter, coco91_to_coco80_class, merge_multi_segme
|
|||||||
## delete_dsstore
|
## delete_dsstore
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.converter.delete_dsstore
|
### ::: ultralytics.data.converter.delete_dsstore
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -16,4 +16,4 @@ keywords: Ultralytics, YOLO, YOLODataset, SemanticDataset, data handling, data m
|
|||||||
## SemanticDataset
|
## SemanticDataset
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.dataset.SemanticDataset
|
### ::: ultralytics.data.dataset.SemanticDataset
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -41,4 +41,4 @@ keywords: Ultralytics, data loaders, LoadStreams, LoadImages, LoadTensor, YOLO,
|
|||||||
## get_best_youtube_url
|
## get_best_youtube_url
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.loaders.get_best_youtube_url
|
### ::: ultralytics.data.loaders.get_best_youtube_url
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -71,4 +71,4 @@ keywords: Ultralytics, data utils, YOLO, img2label_paths, exif_size, polygon2mas
|
|||||||
## autosplit
|
## autosplit
|
||||||
---
|
---
|
||||||
### ::: ultralytics.data.utils.autosplit
|
### ::: ultralytics.data.utils.autosplit
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -31,4 +31,4 @@ keywords: Ultralytics, Exporter, iOSDetectModel, Export Formats, Try export
|
|||||||
## export
|
## export
|
||||||
---
|
---
|
||||||
### ::: ultralytics.engine.exporter.export
|
### ::: ultralytics.engine.exporter.export
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, YOLO, engine model, documentation, guide, implementation,
|
|||||||
## YOLO
|
## YOLO
|
||||||
---
|
---
|
||||||
### ::: ultralytics.engine.model.YOLO
|
### ::: ultralytics.engine.model.YOLO
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, BasePredictor, YOLO, prediction, engine
|
|||||||
## BasePredictor
|
## BasePredictor
|
||||||
---
|
---
|
||||||
### ::: ultralytics.engine.predictor.BasePredictor
|
### ::: ultralytics.engine.predictor.BasePredictor
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -31,4 +31,4 @@ keywords: Ultralytics, engine, results, base tensor, boxes, keypoints
|
|||||||
## Probs
|
## Probs
|
||||||
---
|
---
|
||||||
### ::: ultralytics.engine.results.Probs
|
### ::: ultralytics.engine.results.Probs
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, BaseTrainer, Machine Learning, Training Control, Python l
|
|||||||
## BaseTrainer
|
## BaseTrainer
|
||||||
---
|
---
|
||||||
### ::: ultralytics.engine.trainer.BaseTrainer
|
### ::: ultralytics.engine.trainer.BaseTrainer
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, BaseValidator, Ultralytics engine, module, components
|
|||||||
## BaseValidator
|
## BaseValidator
|
||||||
---
|
---
|
||||||
### ::: ultralytics.engine.validator.BaseValidator
|
### ::: ultralytics.engine.validator.BaseValidator
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -41,4 +41,4 @@ keywords: Ultralytics, hub functions, model export, dataset check, reset model,
|
|||||||
## check_dataset
|
## check_dataset
|
||||||
---
|
---
|
||||||
### ::: ultralytics.hub.check_dataset
|
### ::: ultralytics.hub.check_dataset
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, Auth, API documentation, User Authentication, AI, Machine
|
|||||||
## Auth
|
## Auth
|
||||||
---
|
---
|
||||||
### ::: ultralytics.hub.auth.Auth
|
### ::: ultralytics.hub.auth.Auth
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, HUBTrainingSession, Documentation, Model Training, AI, Ma
|
|||||||
## HUBTrainingSession
|
## HUBTrainingSession
|
||||||
---
|
---
|
||||||
### ::: ultralytics.hub.session.HUBTrainingSession
|
### ::: ultralytics.hub.session.HUBTrainingSession
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -21,4 +21,4 @@ keywords: Ultralytics, Events, request_with_credentials, smart_request, Ultralyt
|
|||||||
## smart_request
|
## smart_request
|
||||||
---
|
---
|
||||||
### ::: ultralytics.hub.utils.smart_request
|
### ::: ultralytics.hub.utils.smart_request
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, FastSAM model, Model documentation, Efficient model train
|
|||||||
## FastSAM
|
## FastSAM
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.fastsam.model.FastSAM
|
### ::: ultralytics.models.fastsam.model.FastSAM
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, FastSAMPredictor, predictive modeling, AI optimization, m
|
|||||||
## FastSAMPredictor
|
## FastSAMPredictor
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.fastsam.predict.FastSAMPredictor
|
### ::: ultralytics.models.fastsam.predict.FastSAMPredictor
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, FastSAMPrompt, machine learning, model, guide, documentat
|
|||||||
## FastSAMPrompt
|
## FastSAMPrompt
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.fastsam.prompt.FastSAMPrompt
|
### ::: ultralytics.models.fastsam.prompt.FastSAMPrompt
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -11,4 +11,4 @@ keywords: Ultralytics, bounding boxes, Bboxes, image borders, object detection,
|
|||||||
## bbox_iou
|
## bbox_iou
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.fastsam.utils.bbox_iou
|
### ::: ultralytics.models.fastsam.utils.bbox_iou
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, FastSAMValidator, model, synthetic, AI, machine learning,
|
|||||||
## FastSAMValidator
|
## FastSAMValidator
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.fastsam.val.FastSAMValidator
|
### ::: ultralytics.models.fastsam.val.FastSAMValidator
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, NAS model, NAS guide, machine learning, model documentati
|
|||||||
## NAS
|
## NAS
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.nas.model.NAS
|
### ::: ultralytics.models.nas.model.NAS
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: NASPredictor, Ultralytics, Ultralytics model, model architecture, effi
|
|||||||
## NASPredictor
|
## NASPredictor
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.nas.predict.NASPredictor
|
### ::: ultralytics.models.nas.predict.NASPredictor
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
@ -6,4 +6,4 @@ keywords: Ultralytics, NASValidator, models.nas.val.NASValidator, AI models, all
|
|||||||
## NASValidator
|
## NASValidator
|
||||||
---
|
---
|
||||||
### ::: ultralytics.models.nas.val.NASValidator
|
### ::: ultralytics.models.nas.val.NASValidator
|
||||||
<br><br>
|
<br><br>
|
||||||
|
|||||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user