ultralytics 8.0.97 confusion matrix, windows, docs updates (#2511)
Co-authored-by: Yonghye Kwon <developer.0hye@gmail.com> Co-authored-by: Dowon <ks2515@naver.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Laughing <61612323+Laughing-q@users.noreply.github.com>
This commit is contained in:
2
.github/workflows/publish.yml
vendored
2
.github/workflows/publish.yml
vendored
@ -23,6 +23,8 @@ jobs:
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: "0" # pulls all commits (needed correct last updated dates in Docs)
|
||||
- name: Set up Python environment
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to install the Ultralytics package in developer mode and build/serve locally using MkDocs. Deploy your project to your host easily.
|
||||
---
|
||||
|
||||
# Ultralytics Docs
|
||||
|
||||
Ultralytics Docs are deployed to [https://docs.ultralytics.com](https://docs.ultralytics.com).
|
||||
@ -82,4 +86,4 @@ for your repository and updating the "Custom domain" field in the "GitHub Pages"
|
||||
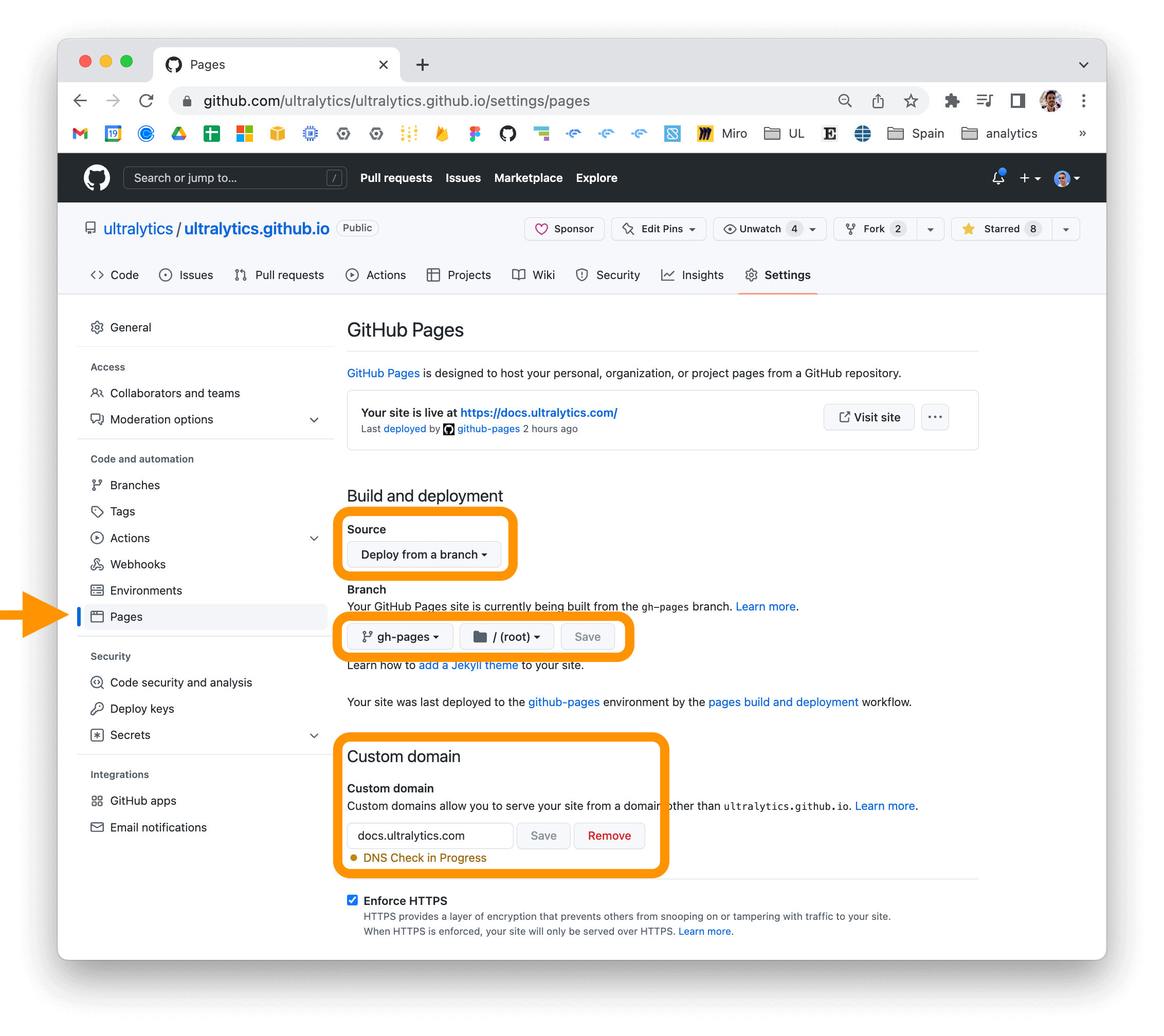
|
||||
|
||||
For more information on deploying your MkDocs documentation site, see
|
||||
the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
||||
the [MkDocs documentation](https://www.mkdocs.org/user-guide/deploying-your-docs/).
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how Ultralytics prioritize security. Get insights into Snyk and GitHub CodeQL scans, and how to report security issues in YOLOv8.
|
||||
---
|
||||
|
||||
# Security Policy
|
||||
|
||||
At [Ultralytics](https://ultralytics.com), the security of our users' data and systems is of utmost importance. To
|
||||
@ -25,4 +29,4 @@ reach out to us directly via our [contact form](https://ultralytics.com/contact)
|
||||
via [security@ultralytics.com](mailto:security@ultralytics.com). Our security team will investigate and respond as soon
|
||||
as possible.
|
||||
|
||||
We appreciate your help in keeping the YOLOv8 repository secure and safe for everyone.
|
||||
We appreciate your help in keeping the YOLOv8 repository secure and safe for everyone.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how torchvision organizes classification image datasets. Use this code to create and train models. CLI and Python code shown.
|
||||
---
|
||||
|
||||
# Image Classification Datasets Overview
|
||||
@ -77,6 +78,7 @@ cifar-10-/
|
||||
In this example, the `train` directory contains subdirectories for each class in the dataset, and each class subdirectory contains all the images for that class. The `test` directory has a similar structure. The `root` directory also contains other files that are part of the CIFAR10 dataset.
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
@ -98,4 +100,5 @@ In this example, the `train` directory contains subdirectories for each class in
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
TODO
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the COCO dataset, designed to encourage research on object detection, segmentation, and captioning with standardized evaluation metrics.
|
||||
---
|
||||
|
||||
# COCO Dataset
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about supported dataset formats for training YOLO detection models, including Ultralytics YOLO and COCO, in this Object Detection Datasets Overview.
|
||||
---
|
||||
|
||||
# Object Detection Datasets Overview
|
||||
@ -15,11 +16,12 @@ The dataset format used for training YOLO detection models is as follows:
|
||||
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
|
||||
2. One row per object: Each row in the text file corresponds to one object instance in the image.
|
||||
3. Object information per row: Each row contains the following information about the object instance:
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
|
||||
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
|
||||
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
|
||||
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
|
||||
|
||||
The format for a single row in the detection dataset file is as follows:
|
||||
|
||||
```
|
||||
<object-class> <x> <y> <width> <height>
|
||||
```
|
||||
@ -55,6 +57,7 @@ The `names` field is a list of the names of the object classes. The order of the
|
||||
NOTE: Either `nc` or `names` must be defined. Defining both are not mandatory
|
||||
|
||||
Alternatively, you can directly define class names like this:
|
||||
|
||||
```yaml
|
||||
names:
|
||||
0: person
|
||||
@ -72,6 +75,7 @@ names: ['person', 'car']
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
@ -93,6 +97,7 @@ names: ['person', 'car']
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
TODO
|
||||
|
||||
## Port or Convert label formats
|
||||
@ -103,4 +108,4 @@ TODO
|
||||
from ultralytics.yolo.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='../coco/annotations/')
|
||||
```
|
||||
```
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Ultralytics provides support for various datasets to facilitate multiple computer vision tasks. Check out our list of main datasets and their summaries.
|
||||
---
|
||||
|
||||
# Datasets Overview
|
||||
@ -10,48 +11,48 @@ Ultralytics provides support for various datasets to facilitate computer vision
|
||||
|
||||
Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
|
||||
|
||||
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
|
||||
* [COCO](detect/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning with over 200K labeled images.
|
||||
* [COCO8](detect/coco8.md): Contains the first 4 images from COCO train and COCO val, suitable for quick tests.
|
||||
* [Global Wheat 2020](detect/globalwheat2020.md): A dataset of wheat head images collected from around the world for object detection and localization tasks.
|
||||
* [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
|
||||
* [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
|
||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||
* [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
|
||||
* [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
|
||||
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
|
||||
* [COCO](detect/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning with over 200K labeled images.
|
||||
* [COCO8](detect/coco8.md): Contains the first 4 images from COCO train and COCO val, suitable for quick tests.
|
||||
* [Global Wheat 2020](detect/globalwheat2020.md): A dataset of wheat head images collected from around the world for object detection and localization tasks.
|
||||
* [Objects365](detect/objects365.md): A high-quality, large-scale dataset for object detection with 365 object categories and over 600K annotated images.
|
||||
* [SKU-110K](detect/sku-110k.md): A dataset featuring dense object detection in retail environments with over 11K images and 1.7 million bounding boxes.
|
||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||
* [VOC](detect/voc.md): The Pascal Visual Object Classes (VOC) dataset for object detection and segmentation with 20 object classes and over 11K images.
|
||||
* [xView](detect/xview.md): A dataset for object detection in overhead imagery with 60 object categories and over 1 million annotated objects.
|
||||
|
||||
## [Instance Segmentation Datasets](segment/index.md)
|
||||
|
||||
Instance segmentation is a computer vision technique that involves identifying and localizing objects in an image at the pixel level.
|
||||
|
||||
* [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.
|
||||
* [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.
|
||||
* [COCO](segment/coco.md): A large-scale dataset designed for object detection, segmentation, and captioning tasks with over 200K labeled images.
|
||||
* [COCO8-seg](segment/coco8-seg.md): A smaller dataset for instance segmentation tasks, containing a subset of 8 COCO images with segmentation annotations.
|
||||
|
||||
## [Pose Estimation](pose/index.md)
|
||||
|
||||
Pose estimation is a technique used to determine the pose of the object relative to the camera or the world coordinate system.
|
||||
|
||||
* [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.
|
||||
* [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.
|
||||
* [COCO](pose/coco.md): A large-scale dataset with human pose annotations designed for pose estimation tasks.
|
||||
* [COCO8-pose](pose/coco8-pose.md): A smaller dataset for pose estimation tasks, containing a subset of 8 COCO images with human pose annotations.
|
||||
|
||||
## [Classification](classify/index.md)
|
||||
|
||||
Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
|
||||
|
||||
* [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
|
||||
* [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
|
||||
* [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
|
||||
* [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
|
||||
* [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
|
||||
* [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
|
||||
* [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
|
||||
* [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
|
||||
* [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
|
||||
* [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
|
||||
* [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
|
||||
* [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
|
||||
* [CIFAR-10](classify/cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
|
||||
* [CIFAR-100](classify/cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
|
||||
* [Fashion-MNIST](classify/fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
|
||||
* [ImageNet](classify/imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
|
||||
* [ImageNet-10](classify/imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
|
||||
* [Imagenette](classify/imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
|
||||
* [Imagewoof](classify/imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
|
||||
* [MNIST](classify/mnist.md): A dataset of 70,000 grayscale images of handwritten digits for image classification tasks.
|
||||
|
||||
## [Multi-Object Tracking](track/index.md)
|
||||
|
||||
Multi-object tracking is a computer vision technique that involves detecting and tracking multiple objects over time in a video sequence.
|
||||
|
||||
* [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations for multi-object tracking tasks.
|
||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||
* [VisDrone](detect/visdrone.md): A dataset containing object detection and multi-object tracking data from drone-captured imagery with over 10K images and video sequences.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to format your dataset for training YOLO models with Ultralytics YOLO format using our concise tutorial and example YAML files.
|
||||
---
|
||||
|
||||
# Pose Estimation Datasets Overview
|
||||
@ -15,26 +16,26 @@ The dataset format used for training YOLO segmentation models is as follows:
|
||||
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
|
||||
2. One row per object: Each row in the text file corresponds to one object instance in the image.
|
||||
3. Object information per row: Each row contains the following information about the object instance:
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
|
||||
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
|
||||
- Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object center coordinates: The x and y coordinates of the center of the object, normalized to be between 0 and 1.
|
||||
- Object width and height: The width and height of the object, normalized to be between 0 and 1.
|
||||
- Object keypoint coordinates: The keypoints of the object, normalized to be between 0 and 1.
|
||||
|
||||
Here is an example of the label format for pose estimation task:
|
||||
|
||||
Format with Dim = 2
|
||||
|
||||
```
|
||||
<class-index> <x> <y> <width> <height> <px1> <py1> <px2> <py2> <pxn> <pyn>
|
||||
<class-index> <x> <y> <width> <height> <px1> <py1> <px2> <py2> ... <pxn> <pyn>
|
||||
```
|
||||
|
||||
Format with Dim = 3
|
||||
|
||||
```
|
||||
<class-index> <x> <y> <width> <height> <px1> <py1> <p1-visibility> <px2> <py2> <p2-visibility> <pxn> <pyn> <p2-visibility>
|
||||
```
|
||||
|
||||
In this format, `<class-index>` is the index of the class for the object,`<x> <y> <width> <height>` are coordinates of boudning box, and `<px1> <py1> <px2> <py2> <pxn> <pyn>` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
|
||||
|
||||
In this format, `<class-index>` is the index of the class for the object,`<x> <y> <width> <height>` are coordinates of boudning box, and `<px1> <py1> <px2> <py2> ... <pxn> <pyn>` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
|
||||
|
||||
** Dataset file format **
|
||||
|
||||
@ -62,6 +63,7 @@ The `names` field is a list of the names of the object classes. The order of the
|
||||
NOTE: Either `nc` or `names` must be defined. Defining both are not mandatory
|
||||
|
||||
Alternatively, you can directly define class names like this:
|
||||
|
||||
```
|
||||
names:
|
||||
0: person
|
||||
@ -69,7 +71,7 @@ names:
|
||||
```
|
||||
|
||||
(Optional) if the points are symmetric then need flip_idx, like left-right side of human or face.
|
||||
For example let's say there're five keypoints of facial landmark: [left eye, right eye, nose, left point of mouth, right point of mouse], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3].(just exchange the left-right index, i.e 0-1 and 3-4, and do not modify others like nose in this example)
|
||||
For example let's say there're five keypoints of facial landmark: [left eye, right eye, nose, left point of mouth, right point of mouse], and the original index is [0, 1, 2, 3, 4], then flip_idx is [1, 0, 2, 4, 3].(just exchange the left-right index, i.e 0-1 and 3-4, and do not modify others like nose in this example)
|
||||
|
||||
** Example **
|
||||
|
||||
@ -86,6 +88,7 @@ flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
@ -107,6 +110,7 @@ flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
|
||||
```
|
||||
|
||||
## Supported Datasets
|
||||
|
||||
TODO
|
||||
|
||||
## Port or Convert label formats
|
||||
@ -117,4 +121,4 @@ TODO
|
||||
from ultralytics.yolo.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='../coco/annotations/', use_keypoints=True)
|
||||
```
|
||||
```
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the Ultralytics YOLO dataset format for segmentation models. Use YAML to train Detection Models. Convert COCO to YOLO format using Python.
|
||||
---
|
||||
|
||||
# Instance Segmentation Datasets Overview
|
||||
@ -15,8 +16,8 @@ The dataset format used for training YOLO segmentation models is as follows:
|
||||
1. One text file per image: Each image in the dataset has a corresponding text file with the same name as the image file and the ".txt" extension.
|
||||
2. One row per object: Each row in the text file corresponds to one object instance in the image.
|
||||
3. Object information per row: Each row contains the following information about the object instance:
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
|
||||
- Object class index: An integer representing the class of the object (e.g., 0 for person, 1 for car, etc.).
|
||||
- Object bounding coordinates: The bounding coordinates around the mask area, normalized to be between 0 and 1.
|
||||
|
||||
The format for a single row in the segmentation dataset file is as follows:
|
||||
|
||||
@ -24,7 +25,7 @@ The format for a single row in the segmentation dataset file is as follows:
|
||||
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>
|
||||
```
|
||||
|
||||
In this format, `<class-index>` is the index of the class for the object, and `<x1> <y1> <x2> <y2> ... <xn> <yn>` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.
|
||||
In this format, `<class-index>` is the index of the class for the object, and `<x1> <y1> <x2> <y2> ... <xn> <yn>` are the bounding coordinates of the object's segmentation mask. The coordinates are separated by spaces.
|
||||
|
||||
Here is an example of the YOLO dataset format for a single image with two object instances:
|
||||
|
||||
@ -32,6 +33,7 @@ Here is an example of the YOLO dataset format for a single image with two object
|
||||
0 0.6812 0.48541 0.67 0.4875 0.67656 0.487 0.675 0.489 0.66
|
||||
1 0.5046 0.0 0.5015 0.004 0.4984 0.00416 0.4937 0.010 0.492 0.0104
|
||||
```
|
||||
|
||||
Note: The length of each row does not have to be equal.
|
||||
|
||||
** Dataset file format **
|
||||
@ -56,6 +58,7 @@ The `names` field is a list of the names of the object classes. The order of the
|
||||
NOTE: Either `nc` or `names` must be defined. Defining both are not mandatory.
|
||||
|
||||
Alternatively, you can directly define class names like this:
|
||||
|
||||
```yaml
|
||||
names:
|
||||
0: person
|
||||
@ -73,6 +76,7 @@ names: ['person', 'car']
|
||||
```
|
||||
|
||||
## Usage
|
||||
|
||||
!!! example ""
|
||||
|
||||
=== "Python"
|
||||
@ -103,4 +107,4 @@ names: ['person', 'car']
|
||||
from ultralytics.yolo.data.converter import convert_coco
|
||||
|
||||
convert_coco(labels_dir='../coco/annotations/', use_segments=True)
|
||||
```
|
||||
```
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Discover the datasets compatible with Multi-Object Detector. Train your trackers and make your detections more efficient with Ultralytics' YOLO.
|
||||
---
|
||||
|
||||
# Multi-object Tracking Datasets Overview
|
||||
@ -25,5 +26,4 @@ Support for training trackers alone is coming soon
|
||||
|
||||
```bash
|
||||
yolo track model=yolov8n.pt source="https://youtu.be/Zgi9g1ksQHc" conf=0.3, iou=0.5 show
|
||||
```
|
||||
|
||||
```
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Individual Contributor License Agreement. Settle Intellectual Property issues for Contributions made to anything open source released by Ultralytics.
|
||||
---
|
||||
|
||||
# Ultralytics Individual Contributor License Agreement
|
||||
|
||||
Thank you for your interest in contributing to open source software projects (“Projects”) made available by Ultralytics
|
||||
@ -62,4 +66,4 @@ that any of the provisions of this Agreement shall be held by a court or other t
|
||||
to be unenforceable, the remaining portions hereof shall remain in full force and effect.
|
||||
|
||||
**Assignment.** You agree that Ultralytics may assign this Agreement, and all of its rights, obligations and licenses
|
||||
hereunder.
|
||||
hereunder.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Get quick answers to common Ultralytics YOLO questions: Hardware requirements, fine-tuning, conversion, real-time detection, and accuracy tips.'
|
||||
---
|
||||
|
||||
# Ultralytics YOLO Frequently Asked Questions (FAQ)
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Read the Ultralytics Contributor Covenant Code of Conduct. Learn ways to create a welcoming community & consequences for inappropriate conduct.
|
||||
---
|
||||
|
||||
# Ultralytics Contributor Covenant Code of Conduct
|
||||
@ -110,7 +111,7 @@ Violating these terms may lead to a permanent ban.
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
@ -129,4 +130,4 @@ For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to contribute to Ultralytics Open-Source YOLO Repositories with contributions guidelines, pull requests requirements, and GitHub CI tests.
|
||||
---
|
||||
|
||||
# Contributing to Ultralytics Open-Source YOLO Repositories
|
||||
@ -10,11 +11,11 @@ First of all, thank you for your interest in contributing to Ultralytics open-so
|
||||
|
||||
- [Code of Conduct](#code-of-conduct)
|
||||
- [Pull Requests](#pull-requests)
|
||||
- [CLA Signing](#cla-signing)
|
||||
- [Google-Style Docstrings](#google-style-docstrings)
|
||||
- [GitHub Actions CI Tests](#github-actions-ci-tests)
|
||||
- [CLA Signing](#cla-signing)
|
||||
- [Google-Style Docstrings](#google-style-docstrings)
|
||||
- [GitHub Actions CI Tests](#github-actions-ci-tests)
|
||||
- [Bug Reports](#bug-reports)
|
||||
- [Minimum Reproducible Example](#minimum-reproducible-example)
|
||||
- [Minimum Reproducible Example](#minimum-reproducible-example)
|
||||
- [License and Copyright](#license-and-copyright)
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get comprehensive resources for Ultralytics YOLO repositories. Find guides, FAQs, MRE creation, CLA & more. Join the supportive community now!
|
||||
---
|
||||
|
||||
Welcome to the Ultralytics Help page! We are committed to providing you with comprehensive resources to make your experience with Ultralytics YOLO repositories as smooth and enjoyable as possible. On this page, you'll find essential links to guides and documents that will help you navigate through common tasks and address any questions you might have while using our repositories.
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to create a Minimum Reproducible Example (MRE) for Ultralytics YOLO bug reports to help maintainers and contributors understand your issue better.
|
||||
---
|
||||
|
||||
# Creating a Minimum Reproducible Example for Bug Reports in Ultralytics YOLO Repositories
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Run YOLO models on your Android device for real-time object detection with Ultralytics Android App. Utilizes TensorFlow Lite and hardware delegates.
|
||||
---
|
||||
|
||||
# Ultralytics Android App: Real-time Object Detection with YOLO Models
|
||||
@ -19,7 +20,7 @@ FP16 (or half-precision) quantization converts the model's 32-bit floating-point
|
||||
INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision.
|
||||
|
||||
!!! tip "mAP Reduction in INT8 Models"
|
||||
|
||||
|
||||
The reduced numerical precision in INT8 models can lead to some loss of information during the quantization process, which may result in a slight decrease in mAP. However, this trade-off is often acceptable considering the substantial performance gains offered by INT8 quantization.
|
||||
|
||||
## Delegates and Performance Variability
|
||||
@ -61,4 +62,4 @@ To get started with the Ultralytics Android App, follow these steps:
|
||||
|
||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||
|
||||
With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
|
||||
With the Ultralytics Android App, you now have the power of real-time object detection using YOLO models right at your fingertips. Enjoy exploring the app's features and optimizing its settings to suit your specific use cases.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Experience the power of YOLOv5 and YOLOv8 models with Ultralytics HUB app. Download from Google Play and App Store now.
|
||||
---
|
||||
|
||||
# Ultralytics HUB App
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with the Ultralytics iOS app and run YOLO models in real-time for object detection on your iPhone or iPad with the Apple Neural Engine.
|
||||
---
|
||||
|
||||
# Ultralytics iOS App: Real-time Object Detection with YOLO Models
|
||||
@ -33,7 +34,6 @@ By combining quantized YOLO models with the Apple Neural Engine, the Ultralytics
|
||||
| 2021 | [iPhone 13](https://en.wikipedia.org/wiki/IPhone_13) | [A15 Bionic](https://en.wikipedia.org/wiki/Apple_A15) | 5 nm | 15.8 |
|
||||
| 2022 | [iPhone 14](https://en.wikipedia.org/wiki/IPhone_14) | [A16 Bionic](https://en.wikipedia.org/wiki/Apple_A16) | 4 nm | 17.0 |
|
||||
|
||||
|
||||
Please note that this list only includes iPhone models from 2017 onwards, and the ANE TOPs values are approximate.
|
||||
|
||||
## Getting Started with the Ultralytics iOS App
|
||||
@ -52,4 +52,4 @@ To get started with the Ultralytics iOS App, follow these steps:
|
||||
|
||||
6. Explore the app's settings to adjust the detection threshold, enable or disable specific object classes, and more.
|
||||
|
||||
With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
|
||||
With the Ultralytics iOS App, you can now leverage the power of YOLO models for real-time object detection on your iPhone or iPad, powered by the Apple Neural Engine and optimized with FP16 or INT8 quantization.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Upload custom datasets to Ultralytics HUB for YOLOv5 and YOLOv8 models. Follow YAML structure, zip and upload. Scan & train new models.
|
||||
---
|
||||
|
||||
# HUB Datasets
|
||||
@ -46,4 +47,4 @@ names:
|
||||
After zipping your dataset, sign in to [Ultralytics HUB](https://bit.ly/ultralytics_hub) and click the Datasets tab.
|
||||
Click 'Upload Dataset' to upload, scan and visualize your new dataset before training new YOLOv5 or YOLOv8 models on it!
|
||||
|
||||
<img width="100%" alt="HUB Dataset Upload" src="https://user-images.githubusercontent.com/26833433/216763338-9a8812c8-a4e5-4362-8102-40dad7818396.png">
|
||||
<img width="100%" alt="HUB Dataset Upload" src="https://user-images.githubusercontent.com/26833433/216763338-9a8812c8-a4e5-4362-8102-40dad7818396.png">
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Ultralytics HUB: Train & deploy YOLO models from one spot! Use drag-and-drop interface with templates & pre-training models. Check quickstart, datasets, and more.'
|
||||
---
|
||||
|
||||
# Ultralytics HUB
|
||||
@ -20,7 +21,6 @@ comments: true
|
||||
launch [Ultralytics HUB](https://bit.ly/ultralytics_hub), a new web tool for training and deploying all your YOLOv5 and YOLOv8 🚀
|
||||
models from one spot!
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
HUB is designed to be user-friendly and intuitive, with a drag-and-drop interface that allows users to
|
||||
|
||||
@ -6,7 +6,6 @@ comments: true
|
||||
|
||||
This page is currently under construction!️ 👷Please check back later for updates. 😃🔜
|
||||
|
||||
|
||||
# YOLO Inference API
|
||||
|
||||
The YOLO Inference API allows you to access the YOLOv8 object detection capabilities via a RESTful API. This enables you to run object detection on images without the need to install and set up the YOLOv8 environment locally.
|
||||
@ -45,7 +44,6 @@ print(response.json())
|
||||
|
||||
In this example, replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `path/to/image.jpg` with the path to the image you want to analyze.
|
||||
|
||||
|
||||
## Example Usage with CLI
|
||||
|
||||
You can use the YOLO Inference API with the command-line interface (CLI) by utilizing the `curl` command. Replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `image.jpg` with the path to the image you want to analyze:
|
||||
@ -334,7 +332,6 @@ YOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses fr
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### Pose Model Format
|
||||
|
||||
YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Train and Deploy your Model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle or directly on Mobile.
|
||||
---
|
||||
|
||||
# HUB Models
|
||||
@ -11,7 +12,6 @@ Connect to the Ultralytics HUB notebook and use your model API key to begin trai
|
||||
<a href="https://colab.research.google.com/github/ultralytics/hub/blob/master/hub.ipynb" target="_blank">
|
||||
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
||||
|
||||
|
||||
## Deploy to Real World
|
||||
|
||||
Export your model to 13 different formats, including TensorFlow, ONNX, OpenVINO, CoreML, Paddle and many others. Run
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Explore Ultralytics YOLOv8, a cutting-edge real-time object detection and image segmentation model for various applications and hardware platforms.
|
||||
---
|
||||
|
||||
<div align="center">
|
||||
@ -23,7 +24,7 @@ Explore the YOLOv8 Docs, a comprehensive resource designed to help you understan
|
||||
## Where to Start
|
||||
|
||||
- **Install** `ultralytics` with pip and get up and running in minutes [:material-clock-fast: Get Started](quickstart.md){ .md-button }
|
||||
- **Predict** new images and videos with YOLOv8 [:octicons-image-16: Predict on Images](modes/predict.md){ .md-button }
|
||||
- **Predict** new images and videos with YOLOv8 [:octicons-image-16: Predict on Images](modes/predict.md){ .md-button }
|
||||
- **Train** a new YOLOv8 model on your own custom dataset [:fontawesome-solid-brain: Train a Model](modes/train.md){ .md-button }
|
||||
- **Explore** YOLOv8 tasks like segment, classify, pose and track [:material-magnify-expand: Explore Tasks](tasks/index.md){ .md-button }
|
||||
|
||||
@ -37,4 +38,4 @@ Explore the YOLOv8 Docs, a comprehensive resource designed to help you understan
|
||||
- [YOLOv5](https://github.com/ultralytics/yolov5) further improved the model's performance and added new features such as hyperparameter optimization, integrated experiment tracking and automatic export to popular export formats.
|
||||
- [YOLOv6](https://github.com/meituan/YOLOv6) was open-sourced by [Meituan](https://about.meituan.com/) in 2022 and is in use in many of the company's autonomous delivery robots.
|
||||
- [YOLOv7](https://github.com/WongKinYiu/yolov7) added additional tasks such as pose estimation on the COCO keypoints dataset.
|
||||
- [YOLOv8](https://github.com/ultralytics/ultralytics) is the latest version of YOLO by Ultralytics. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports a full range of vision AI tasks, including [detection](tasks/detect.md), [segmentation](tasks/segment.md), [pose estimation](tasks/pose.md), [tracking](modes/track.md), and [classification](tasks/classify.md). This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains.
|
||||
- [YOLOv8](https://github.com/ultralytics/ultralytics) is the latest version of YOLO by Ultralytics. As a cutting-edge, state-of-the-art (SOTA) model, YOLOv8 builds on the success of previous versions, introducing new features and improvements for enhanced performance, flexibility, and efficiency. YOLOv8 supports a full range of vision AI tasks, including [detection](tasks/detect.md), [segmentation](tasks/segment.md), [pose estimation](tasks/pose.md), [tracking](modes/track.md), and [classification](tasks/classify.md). This versatility allows users to leverage YOLOv8's capabilities across diverse applications and domains.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the supported models and architectures, such as YOLOv3, YOLOv5, and YOLOv8, and how to contribute your own model to Ultralytics.
|
||||
---
|
||||
|
||||
# Models
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about the Vision Transformer (ViT) and segment anything with SAM models. Train and use pre-trained models with Python API.
|
||||
---
|
||||
|
||||
# Vision Transformers
|
||||
@ -9,11 +10,11 @@ Vit models currently support Python environment:
|
||||
```python
|
||||
from ultralytics.vit import SAM
|
||||
|
||||
# from ultralytics.vit import MODEL_TYPe
|
||||
# from ultralytics.vit import MODEL_TYPE
|
||||
|
||||
model = SAM("sam_b.pt")
|
||||
model.info() # display model information
|
||||
model.predict(...) # train the model
|
||||
model.predict(...) # predict
|
||||
```
|
||||
|
||||
# Segment Anything
|
||||
@ -33,4 +34,4 @@ model.predict(...) # train the model
|
||||
|------------|--------------------|
|
||||
| Inference | :heavy_check_mark: |
|
||||
| Validation | :x: |
|
||||
| Training | :x: |
|
||||
| Training | :x: |
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Detect objects faster and more accurately using Ultralytics YOLOv5u. Find pre-trained models for each task, including Inference, Validation and Training.
|
||||
---
|
||||
|
||||
# YOLOv5u
|
||||
@ -38,4 +39,4 @@ Anchor-free YOLOv5 models with improved accuracy-speed tradeoff.
|
||||
| [YOLOv5s6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5s6u.pt) | 1280 | 48.6 | - | - | 15.3 | 24.6 |
|
||||
| [YOLOv5m6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5m6u.pt) | 1280 | 53.6 | - | - | 41.2 | 65.7 |
|
||||
| [YOLOv5l6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5l6u.pt) | 1280 | 55.7 | - | - | 86.1 | 137.4 |
|
||||
| [YOLOv5x6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5x6u.pt) | 1280 | 56.8 | - | - | 155.4 | 250.7 |
|
||||
| [YOLOv5x6u](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov5x6u.pt) | 1280 | 56.8 | - | - | 155.4 | 250.7 |
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn about YOLOv8's pre-trained weights supporting detection, instance segmentation, pose, and classification tasks. Get performance details.
|
||||
---
|
||||
|
||||
# YOLOv8
|
||||
@ -64,4 +65,4 @@ comments: true
|
||||
| [YOLOv8m-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m-pose.pt) | 640 | 65.0 | 88.8 | 456.3 | 2.00 | 26.4 | 81.0 |
|
||||
| [YOLOv8l-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l-pose.pt) | 640 | 67.6 | 90.0 | 784.5 | 2.59 | 44.4 | 168.6 |
|
||||
| [YOLOv8x-pose](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose.pt) | 640 | 69.2 | 90.2 | 1607.1 | 3.73 | 69.4 | 263.2 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
|
||||
| [YOLOv8x-pose-p6](https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x-pose-p6.pt) | 1280 | 71.6 | 91.2 | 4088.7 | 10.04 | 99.1 | 1066.4 |
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Benchmark mode compares speed and accuracy of various YOLOv8 export formats like ONNX or OpenVINO. Optimize formats for speed or accuracy.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Export mode: Create a deployment-ready YOLOv8 model by converting it to various formats. Export to ONNX or OpenVINO for up to 3x CPU speedup.'
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
@ -82,4 +83,4 @@ i.e. `format='onnx'` or `format='engine'`.
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Use Ultralytics YOLOv8 Modes (Train, Val, Predict, Export, Track, Benchmark) to train, validate, predict, track, export or benchmark.
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv8 Modes
|
||||
@ -63,4 +64,4 @@ or `accuracy_top5` metrics (for classification), and the inference time in milli
|
||||
formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
|
||||
their specific use case based on their requirements for speed and accuracy.
|
||||
|
||||
[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
|
||||
[Benchmark Examples](benchmark.md){ .md-button .md-button--primary}
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with YOLOv8 Predict mode and input sources. Accepts various input sources such as images, videos, and directories.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
@ -58,10 +59,11 @@ whether each source can be used in streaming mode with `stream=True` ✅ and an
|
||||
| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
|
||||
| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
|
||||
|
||||
|
||||
## Arguments
|
||||
|
||||
`model.predict` accepts multiple arguments that control the prediction operation. These arguments can be passed directly to `model.predict`:
|
||||
!!! example
|
||||
|
||||
```
|
||||
model.predict(source, save=True, imgsz=320, conf=0.5)
|
||||
```
|
||||
@ -220,6 +222,7 @@ masks, classification logits, etc.) found in the results object
|
||||
res_plotted = res[0].plot()
|
||||
cv2.imshow("result", res_plotted)
|
||||
```
|
||||
|
||||
| Argument | Description |
|
||||
|-------------------------------|----------------------------------------------------------------------------------------|
|
||||
| `conf (bool)` | Whether to plot the detection confidence score. |
|
||||
@ -234,7 +237,6 @@ masks, classification logits, etc.) found in the results object
|
||||
| `masks (bool)` | Whether to plot the masks. |
|
||||
| `probs (bool)` | Whether to plot classification probability. |
|
||||
|
||||
|
||||
## Streaming Source `for`-loop
|
||||
|
||||
Here's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video frames. This script assumes you have already installed the necessary packages (opencv-python and ultralytics).
|
||||
@ -277,4 +279,4 @@ Here's a Python script using OpenCV (cv2) and YOLOv8 to run inference on video f
|
||||
# Release the video capture object and close the display window
|
||||
cap.release()
|
||||
cv2.destroyAllWindows()
|
||||
```
|
||||
```
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Validate and improve YOLOv8n model accuracy on COCO128 and other datasets using hyperparameter & configuration tuning, in Val mode.
|
||||
---
|
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png">
|
||||
@ -87,4 +88,4 @@ i.e. `format='onnx'` or `format='engine'`.
|
||||
| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ | `imgsz`, `half`, `int8` |
|
||||
| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ | `imgsz` |
|
||||
| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ | `imgsz` |
|
||||
@ -5,22 +5,22 @@ https://github.com/squidfunk/mkdocs-material/blob/master/src/partials/source-fil
|
||||
|
||||
<br>
|
||||
<div class="md-source-file">
|
||||
<small>
|
||||
<small>
|
||||
|
||||
<!-- mkdocs-git-revision-date-localized-plugin -->
|
||||
{% if page.meta.git_revision_date_localized %}
|
||||
📅 {{ lang.t("source.file.date.updated") }}:
|
||||
{{ page.meta.git_revision_date_localized }}
|
||||
{% if page.meta.git_creation_date_localized %}
|
||||
<br />
|
||||
<!-- mkdocs-git-revision-date-localized-plugin -->
|
||||
{% if page.meta.git_revision_date_localized %}
|
||||
📅 {{ lang.t("source.file.date.updated") }}:
|
||||
{{ page.meta.git_revision_date_localized }}
|
||||
{% if page.meta.git_creation_date_localized %}
|
||||
<br/>
|
||||
🎂 {{ lang.t("source.file.date.created") }}:
|
||||
{{ page.meta.git_creation_date_localized }}
|
||||
{% endif %}
|
||||
{% endif %}
|
||||
|
||||
<!-- mkdocs-git-revision-date-plugin -->
|
||||
{% elif page.meta.revision_date %}
|
||||
📅 {{ lang.t("source.file.date.updated") }}:
|
||||
{{ page.meta.revision_date }}
|
||||
{% endif %}
|
||||
</small>
|
||||
<!-- mkdocs-git-revision-date-plugin -->
|
||||
{% elif page.meta.revision_date %}
|
||||
📅 {{ lang.t("source.file.date.updated") }}:
|
||||
{{ page.meta.revision_date }}
|
||||
{% endif %}
|
||||
</small>
|
||||
</div>
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Install and use YOLOv8 via CLI or Python. Run single-line commands or integrate with Python projects for object detection, segmentation, and classification.
|
||||
---
|
||||
|
||||
## Install
|
||||
@ -32,13 +33,11 @@ See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralyt
|
||||
<img width="800" alt="PyTorch Installation Instructions" src="https://user-images.githubusercontent.com/26833433/228650108-ab0ec98a-b328-4f40-a40d-95355e8a84e3.png">
|
||||
</a>
|
||||
|
||||
|
||||
## Use with CLI
|
||||
|
||||
The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
|
||||
CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
|
||||
|
||||
|
||||
!!! example
|
||||
|
||||
=== "Syntax"
|
||||
@ -93,7 +92,6 @@ CLI requires no customization or Python code. You can simply run all tasks from
|
||||
yolo cfg
|
||||
```
|
||||
|
||||
|
||||
!!! warning "Warning"
|
||||
|
||||
Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` between arguments.
|
||||
@ -134,4 +132,4 @@ For example, users can load a model, train it, evaluate its performance on a val
|
||||
success = model.export(format='onnx')
|
||||
```
|
||||
|
||||
[Python Guide](usage/python.md){.md-button .md-button--primary}
|
||||
[Python Guide](usage/python.md){.md-button .md-button--primary}
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Learn how to use Ultralytics hub authentication in your projects with examples and guidelines from the Auth page on Ultralytics Docs.
|
||||
---
|
||||
|
||||
# Auth
|
||||
---
|
||||
:::ultralytics.hub.auth.Auth
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Accelerate your AI development with the Ultralytics HUB Training Session. High-performance training of object detection models.
|
||||
---
|
||||
|
||||
# HUBTrainingSession
|
||||
---
|
||||
:::ultralytics.hub.session.HUBTrainingSession
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Explore Ultralytics events, including 'request_with_credentials' and 'smart_request', to improve your project's performance and efficiency.
|
||||
---
|
||||
|
||||
# Events
|
||||
---
|
||||
:::ultralytics.hub.utils.Events
|
||||
@ -16,4 +20,4 @@
|
||||
# smart_request
|
||||
---
|
||||
:::ultralytics.hub.utils.smart_request
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Ensure class names match filenames for easy imports. Use AutoBackend to automatically rename and refactor model files.
|
||||
---
|
||||
|
||||
# AutoBackend
|
||||
---
|
||||
:::ultralytics.nn.autobackend.AutoBackend
|
||||
@ -6,4 +10,4 @@
|
||||
# check_class_names
|
||||
---
|
||||
:::ultralytics.nn.autobackend.check_class_names
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Detect 80+ object categories with bounding box coordinates and class probabilities using AutoShape in Ultralytics YOLO. Explore Detections now.
|
||||
---
|
||||
|
||||
# AutoShape
|
||||
---
|
||||
:::ultralytics.nn.autoshape.AutoShape
|
||||
@ -6,4 +10,4 @@
|
||||
# Detections
|
||||
---
|
||||
:::ultralytics.nn.autoshape.Detections
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Explore Ultralytics neural network modules for convolution, attention, detection, pose, and classification in PyTorch.
|
||||
---
|
||||
|
||||
# Conv
|
||||
---
|
||||
:::ultralytics.nn.modules.Conv
|
||||
@ -166,4 +170,4 @@
|
||||
# autopad
|
||||
---
|
||||
:::ultralytics.nn.modules.autopad
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to work with Ultralytics YOLO Detection, Segmentation & Classification Models, load weights and parse models in PyTorch.
|
||||
---
|
||||
|
||||
# BaseModel
|
||||
---
|
||||
:::ultralytics.nn.tasks.BaseModel
|
||||
@ -56,4 +60,4 @@
|
||||
# guess_model_task
|
||||
---
|
||||
:::ultralytics.nn.tasks.guess_model_task
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to register custom event-tracking and track predictions with Ultralytics YOLO via on_predict_start and register_tracker methods.
|
||||
---
|
||||
|
||||
# on_predict_start
|
||||
---
|
||||
:::ultralytics.tracker.track.on_predict_start
|
||||
@ -11,4 +15,4 @@
|
||||
# register_tracker
|
||||
---
|
||||
:::ultralytics.tracker.track.register_tracker
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: 'TrackState: A comprehensive guide to Ultralytics tracker''s BaseTrack for monitoring model performance. Improve your tracking capabilities now!'
|
||||
---
|
||||
|
||||
# TrackState
|
||||
---
|
||||
:::ultralytics.tracker.trackers.basetrack.TrackState
|
||||
@ -6,4 +10,4 @@
|
||||
# BaseTrack
|
||||
---
|
||||
:::ultralytics.tracker.trackers.basetrack.BaseTrack
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: '"Optimize tracking with Ultralytics BOTrack. Easily sort and track bots with BOTSORT. Streamline data collection for improved performance."'
|
||||
---
|
||||
|
||||
# BOTrack
|
||||
---
|
||||
:::ultralytics.tracker.trackers.bot_sort.BOTrack
|
||||
@ -6,4 +10,4 @@
|
||||
# BOTSORT
|
||||
---
|
||||
:::ultralytics.tracker.trackers.bot_sort.BOTSORT
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to track ByteAI model sizes and tips for model optimization with STrack, a byte tracking tool from Ultralytics.
|
||||
---
|
||||
|
||||
# STrack
|
||||
---
|
||||
:::ultralytics.tracker.trackers.byte_tracker.STrack
|
||||
@ -6,4 +10,4 @@
|
||||
# BYTETracker
|
||||
---
|
||||
:::ultralytics.tracker.trackers.byte_tracker.BYTETracker
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: '"Track Google Marketing Campaigns in GMC with Ultralytics Tracker. Learn to set up and use GMC for detailed analytics. Get started now."'
|
||||
---
|
||||
|
||||
# GMC
|
||||
---
|
||||
:::ultralytics.tracker.utils.gmc.GMC
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Improve object tracking with KalmanFilterXYAH in Ultralytics YOLO - an efficient and accurate algorithm for state estimation.
|
||||
---
|
||||
|
||||
# KalmanFilterXYAH
|
||||
---
|
||||
:::ultralytics.tracker.utils.kalman_filter.KalmanFilterXYAH
|
||||
@ -6,4 +10,4 @@
|
||||
# KalmanFilterXYWH
|
||||
---
|
||||
:::ultralytics.tracker.utils.kalman_filter.KalmanFilterXYWH
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to match and fuse object detections for accurate target tracking using Ultralytics' YOLO merge_matches, iou_distance, and embedding_distance.
|
||||
---
|
||||
|
||||
# merge_matches
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.merge_matches
|
||||
@ -56,4 +60,4 @@
|
||||
# bbox_ious
|
||||
---
|
||||
:::ultralytics.tracker.utils.matching.bbox_ious
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Learn how to use auto_annotate in Ultralytics YOLO to generate annotations automatically for your dataset. Simplify object detection workflows.
|
||||
---
|
||||
|
||||
# auto_annotate
|
||||
---
|
||||
:::ultralytics.yolo.data.annotator.auto_annotate
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Use Ultralytics YOLO Data Augmentation transforms with Base, MixUp, and Albumentations for object detection and classification.
|
||||
---
|
||||
|
||||
# BaseTransform
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.BaseTransform
|
||||
@ -86,4 +90,4 @@
|
||||
# classify_albumentations
|
||||
---
|
||||
:::ultralytics.yolo.data.augment.classify_albumentations
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Learn about BaseDataset in Ultralytics YOLO, a flexible dataset class for object detection. Maximize your YOLO performance with custom datasets.
|
||||
---
|
||||
|
||||
# BaseDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.base.BaseDataset
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Maximize YOLO performance with Ultralytics' InfiniteDataLoader, seed_worker, build_dataloader, and load_inference_source functions.
|
||||
---
|
||||
|
||||
# InfiniteDataLoader
|
||||
---
|
||||
:::ultralytics.yolo.data.build.InfiniteDataLoader
|
||||
@ -31,4 +35,4 @@
|
||||
# load_inference_source
|
||||
---
|
||||
:::ultralytics.yolo.data.build.load_inference_source
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Convert COCO-91 to COCO-80 class, RLE to polygon, and merge multi-segment images with Ultralytics YOLO data converter. Improve your object detection.
|
||||
---
|
||||
|
||||
# coco91_to_coco80_class
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.coco91_to_coco80_class
|
||||
@ -26,4 +30,4 @@
|
||||
# delete_dsstore
|
||||
---
|
||||
:::ultralytics.yolo.data.converter.delete_dsstore
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: 'Ultralytics YOLO Docs: Learn about stream loaders for image and tensor data, as well as autocasting techniques. Check out SourceTypes and more.'
|
||||
---
|
||||
|
||||
# SourceTypes
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.SourceTypes
|
||||
@ -31,4 +35,4 @@
|
||||
# autocast_list
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.stream_loaders.autocast_list
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Enhance image data with Albumentations CenterCrop, normalize, augment_hsv, replicate, random_perspective, cutout, & box_candidates.
|
||||
---
|
||||
|
||||
# Albumentations
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.Albumentations
|
||||
@ -81,4 +85,4 @@
|
||||
# classify_transforms
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5augmentations.classify_transforms
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Efficiently load images and labels to models using Ultralytics YOLO's InfiniteDataLoader, LoadScreenshots, and LoadStreams.
|
||||
---
|
||||
|
||||
# InfiniteDataLoader
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.InfiniteDataLoader
|
||||
@ -86,4 +90,4 @@
|
||||
# create_classification_dataloader
|
||||
---
|
||||
:::ultralytics.yolo.data.dataloaders.v5loader.create_classification_dataloader
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Create custom YOLOv5 datasets with Ultralytics YOLODataset and SemanticDataset. Streamline your object detection and segmentation projects.
|
||||
---
|
||||
|
||||
# YOLODataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset.YOLODataset
|
||||
@ -11,4 +15,4 @@
|
||||
# SemanticDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset.SemanticDataset
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Create a custom dataset of mixed and oriented rectangular objects with Ultralytics YOLO's MixAndRectDataset.
|
||||
---
|
||||
|
||||
# MixAndRectDataset
|
||||
---
|
||||
:::ultralytics.yolo.data.dataset_wrappers.MixAndRectDataset
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Efficiently handle data in YOLO with Ultralytics. Utilize HUBDatasetStats and customize dataset with these data utility functions.
|
||||
---
|
||||
|
||||
# HUBDatasetStats
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.HUBDatasetStats
|
||||
@ -61,4 +65,4 @@
|
||||
# zip_directory
|
||||
---
|
||||
:::ultralytics.yolo.data.utils.zip_directory
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to export your YOLO model in various formats using Ultralytics' exporter package - iOS, GDC, and more.
|
||||
---
|
||||
|
||||
# Exporter
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.Exporter
|
||||
@ -26,4 +30,4 @@
|
||||
# export
|
||||
---
|
||||
:::ultralytics.yolo.engine.exporter.export
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Discover the YOLO model of Ultralytics engine to simplify your object detection tasks with state-of-the-art models.
|
||||
---
|
||||
|
||||
# YOLO
|
||||
---
|
||||
:::ultralytics.yolo.engine.model.YOLO
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: '"The BasePredictor class in Ultralytics YOLO Engine predicts object detection in images and videos. Learn to implement YOLO with ease."'
|
||||
---
|
||||
|
||||
# BasePredictor
|
||||
---
|
||||
:::ultralytics.yolo.engine.predictor.BasePredictor
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about BaseTensor & Boxes in Ultralytics YOLO Engine. Check out Ultralytics Docs for quality tutorials and resources on object detection.
|
||||
---
|
||||
|
||||
# BaseTensor
|
||||
---
|
||||
:::ultralytics.yolo.engine.results.BaseTensor
|
||||
@ -16,4 +20,4 @@
|
||||
# Masks
|
||||
---
|
||||
:::ultralytics.yolo.engine.results.Masks
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Train faster with mixed precision. Learn how to use BaseTrainer with Advanced Mixed Precision to optimize YOLOv3 and YOLOv4 models.
|
||||
---
|
||||
|
||||
# BaseTrainer
|
||||
---
|
||||
:::ultralytics.yolo.engine.trainer.BaseTrainer
|
||||
@ -6,4 +10,4 @@
|
||||
# check_amp
|
||||
---
|
||||
:::ultralytics.yolo.engine.trainer.check_amp
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Ensure YOLOv5 models meet constraints and standards with the BaseValidator class. Learn how to use it here.
|
||||
---
|
||||
|
||||
# BaseValidator
|
||||
---
|
||||
:::ultralytics.yolo.engine.validator.BaseValidator
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Dynamically adjusts input size to optimize GPU memory usage during training. Learn how to use check_train_batch_size with Ultralytics YOLO.
|
||||
---
|
||||
|
||||
# check_train_batch_size
|
||||
---
|
||||
:::ultralytics.yolo.utils.autobatch.check_train_batch_size
|
||||
@ -6,4 +10,4 @@
|
||||
# autobatch
|
||||
---
|
||||
:::ultralytics.yolo.utils.autobatch.autobatch
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Improve your YOLO's performance and measure its speed. Benchmark utility for YOLOv5.
|
||||
---
|
||||
|
||||
# benchmark
|
||||
---
|
||||
:::ultralytics.yolo.utils.benchmarks.benchmark
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about YOLO's callback functions from on_train_start to add_integration_callbacks. See how these callbacks modify and save models.
|
||||
---
|
||||
|
||||
# on_pretrain_routine_start
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.base.on_pretrain_routine_start
|
||||
@ -131,4 +135,4 @@
|
||||
# add_integration_callbacks
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.base.add_integration_callbacks
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Improve your YOLOv5 model training with callbacks from ClearML. Learn about log debug samples, pre-training routines, validation and more.
|
||||
---
|
||||
|
||||
# _log_debug_samples
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.clearml._log_debug_samples
|
||||
@ -31,4 +35,4 @@
|
||||
# on_train_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.clearml.on_train_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about YOLO callbacks using the Comet.ml platform, enhancing object detection training and testing with custom logging and visualizations.
|
||||
---
|
||||
|
||||
# _get_comet_mode
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.comet._get_comet_mode
|
||||
@ -116,4 +120,4 @@
|
||||
# on_train_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.comet.on_train_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Improve YOLOv5 model training with Ultralytics' on-train callbacks. Boost performance on-pretrain-routine-end, model-save, train/predict start.
|
||||
---
|
||||
|
||||
# on_pretrain_routine_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.hub.on_pretrain_routine_end
|
||||
@ -36,4 +40,4 @@
|
||||
# on_export_start
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.hub.on_export_start
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Track model performance and metrics with MLflow in YOLOv5. Use callbacks like on_pretrain_routine_end or on_train_end to log information.
|
||||
---
|
||||
|
||||
# on_pretrain_routine_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.mlflow.on_pretrain_routine_end
|
||||
@ -11,4 +15,4 @@
|
||||
# on_train_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.mlflow.on_train_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Improve YOLOv5 training with Neptune, a powerful logging tool. Track metrics like images, plots, and epochs for better model performance.
|
||||
---
|
||||
|
||||
# _log_scalars
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.neptune._log_scalars
|
||||
@ -36,4 +40,4 @@
|
||||
# on_train_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.neptune.on_train_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: '"Improve YOLO model performance with on_fit_epoch_end callback. Learn to integrate with Ray Tune for hyperparameter tuning. Ultralytics YOLO docs."'
|
||||
---
|
||||
|
||||
# on_fit_epoch_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.raytune.on_fit_epoch_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to monitor the training process with Tensorboard using Ultralytics YOLO's "_log_scalars" and "on_batch_end" methods.
|
||||
---
|
||||
|
||||
# _log_scalars
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.tensorboard._log_scalars
|
||||
@ -16,4 +20,4 @@
|
||||
# on_fit_epoch_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.tensorboard.on_fit_epoch_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to use Ultralytics YOLO's built-in callbacks `on_pretrain_routine_start` and `on_train_epoch_end` for improved training performance.
|
||||
---
|
||||
|
||||
# on_pretrain_routine_start
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.wb.on_pretrain_routine_start
|
||||
@ -16,4 +20,4 @@
|
||||
# on_train_end
|
||||
---
|
||||
:::ultralytics.yolo.utils.callbacks.wb.on_train_end
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: 'Check functions for YOLO utils: image size, version, font, requirements, filename suffix, YAML file, YOLO, and Git version.'
|
||||
---
|
||||
|
||||
# is_ascii
|
||||
---
|
||||
:::ultralytics.yolo.utils.checks.is_ascii
|
||||
@ -76,4 +80,4 @@
|
||||
# print_args
|
||||
---
|
||||
:::ultralytics.yolo.utils.checks.print_args
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to find free network port and generate DDP (Distributed Data Parallel) command in Ultralytics YOLO with easy examples.
|
||||
---
|
||||
|
||||
# find_free_network_port
|
||||
---
|
||||
:::ultralytics.yolo.utils.dist.find_free_network_port
|
||||
@ -16,4 +20,4 @@
|
||||
# ddp_cleanup
|
||||
---
|
||||
:::ultralytics.yolo.utils.dist.ddp_cleanup
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Download and unzip YOLO pretrained models. Ultralytics YOLO docs utils.downloads.unzip_file, checks disk space, downloads and attempts assets.
|
||||
---
|
||||
|
||||
# is_url
|
||||
---
|
||||
:::ultralytics.yolo.utils.downloads.is_url
|
||||
@ -26,4 +30,4 @@
|
||||
# download
|
||||
---
|
||||
:::ultralytics.yolo.utils.downloads.download
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,4 +1,8 @@
|
||||
---
|
||||
description: Learn about HUBModelError in Ultralytics YOLO Docs. Resolve the error and get the most out of your YOLO model.
|
||||
---
|
||||
|
||||
# HUBModelError
|
||||
---
|
||||
:::ultralytics.yolo.utils.errors.HUBModelError
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: 'Learn about Ultralytics YOLO files and directory utilities: WorkingDirectory, file_age, file_size, and make_dirs.'
|
||||
---
|
||||
|
||||
# WorkingDirectory
|
||||
---
|
||||
:::ultralytics.yolo.utils.files.WorkingDirectory
|
||||
@ -31,4 +35,4 @@
|
||||
# make_dirs
|
||||
---
|
||||
:::ultralytics.yolo.utils.files.make_dirs
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about Bounding Boxes (Bboxes) and _ntuple in Ultralytics YOLO for object detection. Improve accuracy and speed with these powerful tools.
|
||||
---
|
||||
|
||||
# Bboxes
|
||||
---
|
||||
:::ultralytics.yolo.utils.instance.Bboxes
|
||||
@ -11,4 +15,4 @@
|
||||
# _ntuple
|
||||
---
|
||||
:::ultralytics.yolo.utils.instance._ntuple
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about Varifocal Loss and Keypoint Loss in Ultralytics YOLO for advanced bounding box and pose estimation. Visit our docs for more.
|
||||
---
|
||||
|
||||
# VarifocalLoss
|
||||
---
|
||||
:::ultralytics.yolo.utils.loss.VarifocalLoss
|
||||
@ -11,4 +15,4 @@
|
||||
# KeypointLoss
|
||||
---
|
||||
:::ultralytics.yolo.utils.loss.KeypointLoss
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Explore Ultralytics YOLO's FocalLoss, DetMetrics, PoseMetrics, ClassifyMetrics, and more with Ultralytics Metrics documentation.
|
||||
---
|
||||
|
||||
# FocalLoss
|
||||
---
|
||||
:::ultralytics.yolo.utils.metrics.FocalLoss
|
||||
@ -91,4 +95,4 @@
|
||||
# ap_per_class
|
||||
---
|
||||
:::ultralytics.yolo.utils.metrics.ap_per_class
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about various utility functions in Ultralytics YOLO, including x, y, width, height conversions, non-max suppression, and more.
|
||||
---
|
||||
|
||||
# Profile
|
||||
---
|
||||
:::ultralytics.yolo.utils.ops.Profile
|
||||
@ -131,4 +135,4 @@
|
||||
# clean_str
|
||||
---
|
||||
:::ultralytics.yolo.utils.ops.clean_str
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: 'Discover the power of YOLO''s plotting functions: Colors, Labels and Images. Code examples to output targets and visualize features. Check it now.'
|
||||
---
|
||||
|
||||
# Colors
|
||||
---
|
||||
:::ultralytics.yolo.utils.plotting.Colors
|
||||
@ -36,4 +40,4 @@
|
||||
# feature_visualization
|
||||
---
|
||||
:::ultralytics.yolo.utils.plotting.feature_visualization
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Improve your YOLO models with Ultralytics' TaskAlignedAssigner, select_highest_overlaps, and dist2bbox utilities. Streamline your workflow today.
|
||||
---
|
||||
|
||||
# TaskAlignedAssigner
|
||||
---
|
||||
:::ultralytics.yolo.utils.tal.TaskAlignedAssigner
|
||||
@ -26,4 +30,4 @@
|
||||
# bbox2dist
|
||||
---
|
||||
:::ultralytics.yolo.utils.tal.bbox2dist
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Optimize your PyTorch models with Ultralytics YOLO's torch_utils functions such as ModelEMA, select_device, and is_parallel.
|
||||
---
|
||||
|
||||
# ModelEMA
|
||||
---
|
||||
:::ultralytics.yolo.utils.torch_utils.ModelEMA
|
||||
@ -116,4 +120,4 @@
|
||||
# profile
|
||||
---
|
||||
:::ultralytics.yolo.utils.torch_utils.profile
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn how to use ClassificationPredictor in Ultralytics YOLOv8 for object classification tasks in a simple and efficient way.
|
||||
---
|
||||
|
||||
# ClassificationPredictor
|
||||
---
|
||||
:::ultralytics.yolo.v8.classify.predict.ClassificationPredictor
|
||||
@ -6,4 +10,4 @@
|
||||
# predict
|
||||
---
|
||||
:::ultralytics.yolo.v8.classify.predict.predict
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Train a custom image classification model using Ultralytics YOLOv8 with ClassificationTrainer. Boost accuracy and efficiency today.
|
||||
---
|
||||
|
||||
# ClassificationTrainer
|
||||
---
|
||||
:::ultralytics.yolo.v8.classify.train.ClassificationTrainer
|
||||
@ -6,4 +10,4 @@
|
||||
# train
|
||||
---
|
||||
:::ultralytics.yolo.v8.classify.train.train
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Ensure model classification accuracy with Ultralytics YOLO's ClassificationValidator. Validate and improve your model with ease.
|
||||
---
|
||||
|
||||
# ClassificationValidator
|
||||
---
|
||||
:::ultralytics.yolo.v8.classify.val.ClassificationValidator
|
||||
@ -6,4 +10,4 @@
|
||||
# val
|
||||
---
|
||||
:::ultralytics.yolo.v8.classify.val.val
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Detect and predict objects in images and videos using the Ultralytics YOLO v8 model with DetectionPredictor.
|
||||
---
|
||||
|
||||
# DetectionPredictor
|
||||
---
|
||||
:::ultralytics.yolo.v8.detect.predict.DetectionPredictor
|
||||
@ -6,4 +10,4 @@
|
||||
# predict
|
||||
---
|
||||
:::ultralytics.yolo.v8.detect.predict.predict
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Train and optimize custom object detection models with Ultralytics DetectionTrainer and train functions. Get started with YOLO v8 today.
|
||||
---
|
||||
|
||||
# DetectionTrainer
|
||||
---
|
||||
:::ultralytics.yolo.v8.detect.train.DetectionTrainer
|
||||
@ -11,4 +15,4 @@
|
||||
# train
|
||||
---
|
||||
:::ultralytics.yolo.v8.detect.train.train
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Validate YOLOv5 detections using this PyTorch module. Ensure model accuracy with NMS IOU threshold tuning and label mapping.
|
||||
---
|
||||
|
||||
# DetectionValidator
|
||||
---
|
||||
:::ultralytics.yolo.v8.detect.val.DetectionValidator
|
||||
@ -6,4 +10,4 @@
|
||||
# val
|
||||
---
|
||||
:::ultralytics.yolo.v8.detect.val.val
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Predict human pose coordinates and confidence scores using YOLOv5. Use on real-time video streams or static images.
|
||||
---
|
||||
|
||||
# PosePredictor
|
||||
---
|
||||
:::ultralytics.yolo.v8.pose.predict.PosePredictor
|
||||
@ -6,4 +10,4 @@
|
||||
# predict
|
||||
---
|
||||
:::ultralytics.yolo.v8.pose.predict.predict
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Boost posture detection using PoseTrainer and train models using train() API. Learn PoseLoss for ultra-fast and accurate pose detection with Ultralytics YOLO.
|
||||
---
|
||||
|
||||
# PoseTrainer
|
||||
---
|
||||
:::ultralytics.yolo.v8.pose.train.PoseTrainer
|
||||
@ -11,4 +15,4 @@
|
||||
# train
|
||||
---
|
||||
:::ultralytics.yolo.v8.pose.train.train
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Ensure proper human poses in images with YOLOv8 Pose Validation, part of the Ultralytics YOLO v8 suite.
|
||||
---
|
||||
|
||||
# PoseValidator
|
||||
---
|
||||
:::ultralytics.yolo.v8.pose.val.PoseValidator
|
||||
@ -6,4 +10,4 @@
|
||||
# val
|
||||
---
|
||||
:::ultralytics.yolo.v8.pose.val.val
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: '"Use SegmentationPredictor in YOLOv8 for efficient object detection and segmentation. Explore Ultralytics YOLO Docs for more information."'
|
||||
---
|
||||
|
||||
# SegmentationPredictor
|
||||
---
|
||||
:::ultralytics.yolo.v8.segment.predict.SegmentationPredictor
|
||||
@ -6,4 +10,4 @@
|
||||
# predict
|
||||
---
|
||||
:::ultralytics.yolo.v8.segment.predict.predict
|
||||
<br><br>
|
||||
<br><br>
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
description: Learn about SegmentationTrainer and Train in Ultralytics YOLO v8 for efficient object detection models. Improve your training with Ultralytics Docs.
|
||||
---
|
||||
|
||||
# SegmentationTrainer
|
||||
---
|
||||
:::ultralytics.yolo.v8.segment.train.SegmentationTrainer
|
||||
@ -11,4 +15,4 @@
|
||||
# train
|
||||
---
|
||||
:::ultralytics.yolo.v8.segment.train.train
|
||||
<br><br>
|
||||
<br><br>
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user