ultralytics 8.0.97 confusion matrix, windows, docs updates (#2511)
Co-authored-by: Yonghye Kwon <developer.0hye@gmail.com> Co-authored-by: Dowon <ks2515@naver.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Laughing <61612323+Laughing-q@users.noreply.github.com>
This commit is contained in:
@ -1,10 +1,12 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Ultralytics YOLOv5 Docs: Learn model structure, data augmentation & training strategies. Build targets and the losses of object detection.'
|
||||
---
|
||||
|
||||
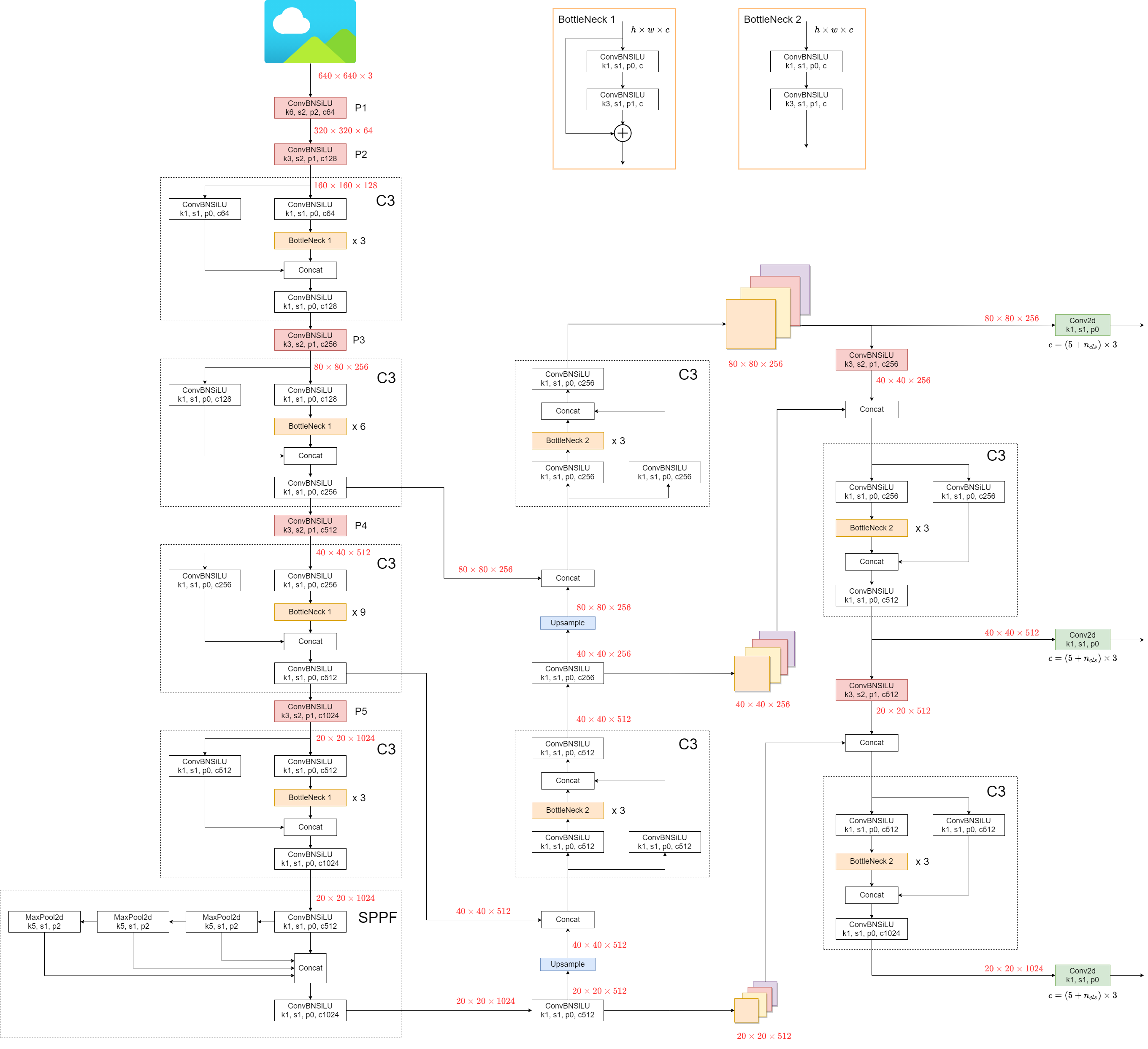
## 1. Model Structure
|
||||
|
||||
YOLOv5 (v6.0/6.1) consists of:
|
||||
|
||||
- **Backbone**: `New CSP-Darknet53`
|
||||
- **Neck**: `SPPF`, `New CSP-PAN`
|
||||
- **Head**: `YOLOv3 Head`
|
||||
@ -13,10 +15,9 @@ Model structure (`yolov5l.yaml`):
|
||||
|
||||
|
||||
|
||||
|
||||
Some minor changes compared to previous versions:
|
||||
|
||||
1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)
|
||||
1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)
|
||||
2. Replace the `SPP` structure with `SPPF`(more than double the speed)
|
||||
|
||||
<details markdown>
|
||||
@ -79,6 +80,7 @@ if __name__ == '__main__':
|
||||
```
|
||||
|
||||
result:
|
||||
|
||||
```
|
||||
True
|
||||
spp time: 0.5373051166534424
|
||||
@ -87,30 +89,26 @@ sppf time: 0.20780706405639648
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
## 2. Data Augmentation
|
||||
|
||||
- Mosaic
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109235-c7aad8f2-1d4f-41f9-8d5f-b2fde6f2885e.png#pic_center" width=80%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109235-c7aad8f2-1d4f-41f9-8d5f-b2fde6f2885e.png#pic_center" width=80%>
|
||||
|
||||
- Copy paste
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159116277-91b45033-6bec-4f82-afc4-41138866628e.png#pic_center" width=80%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159116277-91b45033-6bec-4f82-afc4-41138866628e.png#pic_center" width=80%>
|
||||
|
||||
- Random affine(Rotation, Scale, Translation and Shear)
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109326-45cd5acb-14fa-43e7-9235-0f21b0021c7d.png#pic_center" width=80%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109326-45cd5acb-14fa-43e7-9235-0f21b0021c7d.png#pic_center" width=80%>
|
||||
|
||||
- MixUp
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109361-3b24333b-f481-478b-ae00-df7838f0b5cd.png#pic_center" width=80%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109361-3b24333b-f481-478b-ae00-df7838f0b5cd.png#pic_center" width=80%>
|
||||
|
||||
- Albumentations
|
||||
- Augment HSV(Hue, Saturation, Value)
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109407-83d100ba-1aba-4f4b-aa03-4f048f815981.png#pic_center" width=80%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109407-83d100ba-1aba-4f4b-aa03-4f048f815981.png#pic_center" width=80%>
|
||||
|
||||
- Random horizontal flip
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109429-0d44619a-a76a-49eb-bfc0-6709860c043e.png#pic_center" width=80%>
|
||||
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109429-0d44619a-a76a-49eb-bfc0-6709860c043e.png#pic_center" width=80%>
|
||||
|
||||
## 3. Training Strategies
|
||||
|
||||
@ -121,13 +119,11 @@ sppf time: 0.20780706405639648
|
||||
- Mixed precision
|
||||
- Evolve hyper-parameters
|
||||
|
||||
|
||||
|
||||
## 4. Others
|
||||
|
||||
### 4.1 Compute Losses
|
||||
|
||||
The YOLOv5 loss consists of three parts:
|
||||
The YOLOv5 loss consists of three parts:
|
||||
|
||||
- Classes loss(BCE loss)
|
||||
- Objectness loss(BCE loss)
|
||||
@ -136,12 +132,14 @@ The YOLOv5 loss consists of three parts:
|
||||

|
||||
|
||||
### 4.2 Balance Losses
|
||||
|
||||
The objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.
|
||||
|
||||

|
||||
|
||||
### 4.3 Eliminate Grid Sensitivity
|
||||
In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:
|
||||
|
||||
In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:
|
||||
|
||||
+c_x)
|
||||
+c_y)
|
||||
@ -152,12 +150,12 @@ In YOLOv2 and YOLOv3, the formula for calculating the predicted target informati
|
||||
|
||||
|
||||
|
||||
In YOLOv5, the formula is:
|
||||
In YOLOv5, the formula is:
|
||||
|
||||
-0.5)+c_x)
|
||||
-0.5)+c_y)
|
||||
)^2)
|
||||
)^2)
|
||||
)^2)
|
||||
|
||||
Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).
|
||||
Therefore, offset can easily get 0 or 1.
|
||||
@ -168,8 +166,8 @@ Compare the height and width scaling ratio(relative to anchor) before and after
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508089-5ac0c7a3-6358-44b7-863e-a6e45babb842.png#pic_center" width=40%>
|
||||
|
||||
|
||||
### 4.4 Build Targets
|
||||
|
||||
Match positive samples:
|
||||
|
||||
- Calculate the aspect ratio of GT and Anchor Templates
|
||||
@ -194,4 +192,4 @@ Match positive samples:
|
||||
|
||||
- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70%>
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Integrate ClearML with YOLOv5 to track experiments and manage data versions. Optimize hyperparameters and remotely monitor your runs.
|
||||
---
|
||||
|
||||
# ClearML Integration
|
||||
@ -238,4 +239,4 @@ ClearML comes with autoscalers too! This tool will automatically spin up new rem
|
||||
|
||||
Check out the autoscalers getting started video below.
|
||||
|
||||
[](https://youtu.be/j4XVMAaUt3E)
|
||||
[](https://youtu.be/j4XVMAaUt3E)
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to use YOLOv5 with Comet, a tool for logging and visualizing machine learning model metrics in real-time. Install, log and analyze seamlessly.
|
||||
---
|
||||
|
||||
<img src="https://cdn.comet.ml/img/notebook_logo.png">
|
||||
@ -218,7 +219,7 @@ If your training run is interrupted for any reason, e.g. disrupted internet conn
|
||||
|
||||
The Run Path has the following format `comet://<your workspace name>/<your project name>/<experiment id>`.
|
||||
|
||||
This will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI
|
||||
This will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI
|
||||
|
||||
```shell
|
||||
python train.py \
|
||||
@ -259,4 +260,4 @@ comet optimizer -j <set number of workers> utils/loggers/comet/hpo.py \
|
||||
|
||||
Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
|
||||
|
||||
<img width="1626" alt="hyperparameter-yolo" src="https://user-images.githubusercontent.com/7529846/186914869-7dc1de14-583f-4323-967b-c9a66a29e495.png">
|
||||
<img width="1626" alt="hyperparameter-yolo" src="https://user-images.githubusercontent.com/7529846/186914869-7dc1de14-583f-4323-967b-c9a66a29e495.png">
|
||||
@ -1,12 +1,12 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn to find optimum YOLOv5 hyperparameters via **evolution**. A guide to learn hyperparameter tuning with Genetic Algorithms.
|
||||
---
|
||||
|
||||
📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.
|
||||
📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.
|
||||
|
||||
Hyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.
|
||||
|
||||
|
||||
## Before You Start
|
||||
|
||||
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||
@ -17,7 +17,6 @@ cd yolov5
|
||||
pip install -r requirements.txt # install
|
||||
```
|
||||
|
||||
|
||||
## 1. Initialize Hyperparameters
|
||||
|
||||
YOLOv5 has about 30 hyperparameters used for various training settings. These are defined in `*.yaml` files in the `/data/hyps` directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.
|
||||
@ -73,10 +72,13 @@ def fitness(x):
|
||||
## 3. Evolve
|
||||
|
||||
Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
|
||||
|
||||
```bash
|
||||
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
|
||||
```
|
||||
|
||||
To evolve hyperparameters **specific to this scenario**, starting from our initial values defined in **Section 1.**, and maximizing the fitness defined in **Section 2.**, append `--evolve`:
|
||||
|
||||
```bash
|
||||
# Single-GPU
|
||||
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
|
||||
@ -100,6 +102,7 @@ The default evolution settings will run the base scenario 300 times, i.e. for 30
|
||||
https://github.com/ultralytics/yolov5/blob/6a3ee7cf03efb17fbffde0e68b1a854e80fe3213/train.py#L608
|
||||
|
||||
The main genetic operators are **crossover** and **mutation**. In this work mutation is used, with an 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to `runs/evolve/exp/evolve.csv`, and the highest fitness offspring is saved every generation as `runs/evolve/hyp_evolved.yaml`:
|
||||
|
||||
```yaml
|
||||
# YOLOv5 Hyperparameter Evolution Results
|
||||
# Best generation: 287
|
||||
@ -140,14 +143,12 @@ copy_paste: 0.0 # segment copy-paste (probability)
|
||||
|
||||
We recommend a minimum of 300 generations of evolution for best results. Note that **evolution is generally expensive and time-consuming**, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
|
||||
|
||||
|
||||
## 4. Visualize
|
||||
|
||||
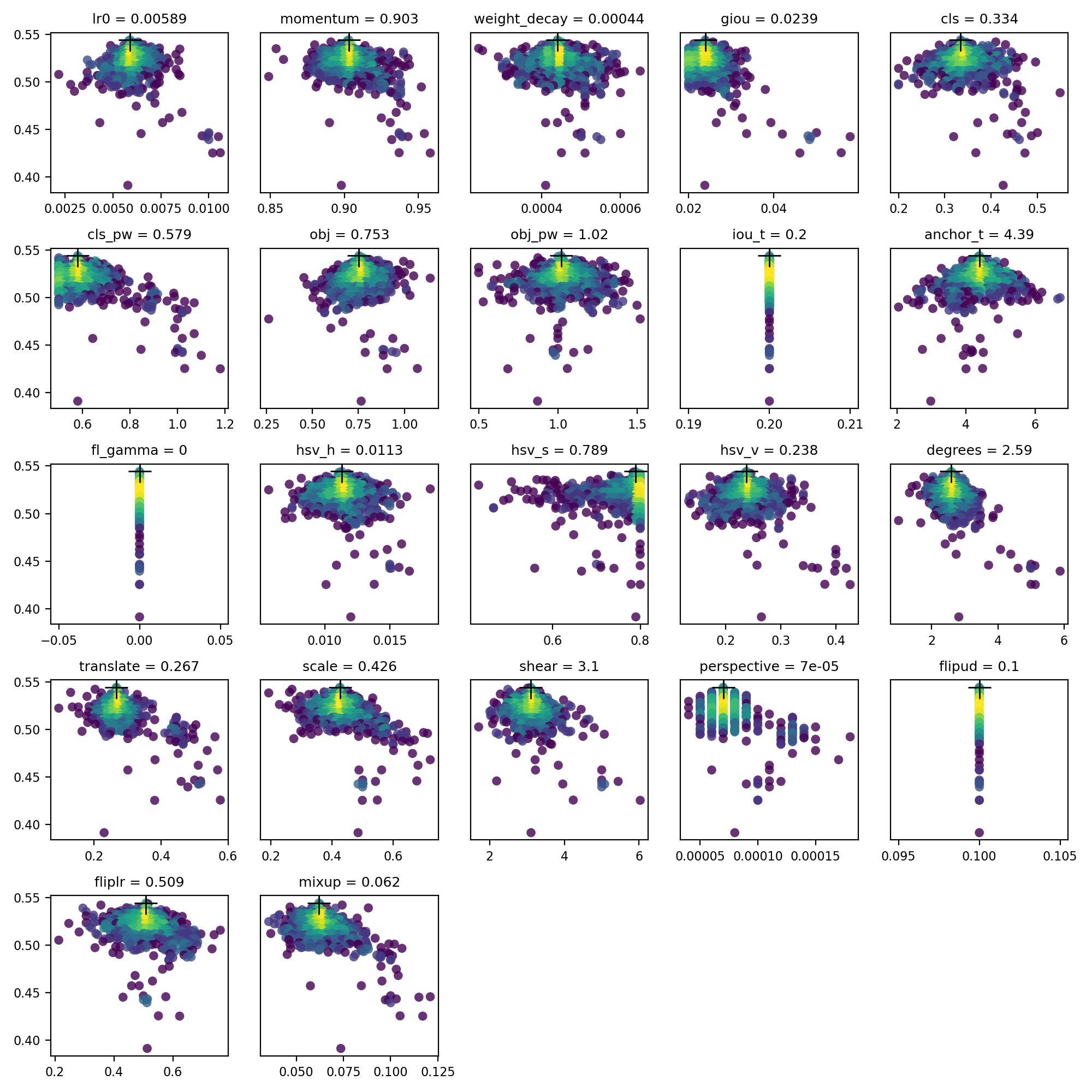
`evolve.csv` is plotted as `evolve.png` by `utils.plots.plot_evolve()` after evolution finishes with one subplot per hyperparameter showing fitness (y-axis) vs hyperparameter values (x-axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the `meta` dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.
|
||||
|
||||
|
||||
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
@ -157,7 +158,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to ensemble YOLOv5 models for improved mAP and Recall! Clone the repo, install requirements, and start testing and inference.
|
||||
---
|
||||
|
||||
📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
|
||||
📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
|
||||
UPDATED 25 September 2022.
|
||||
|
||||
From [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):
|
||||
> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
|
||||
|
||||
|
||||
## Before You Start
|
||||
|
||||
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||
@ -22,11 +22,13 @@ pip install -r requirements.txt # install
|
||||
## Test Normally
|
||||
|
||||
Before ensembling we want to establish the baseline performance of a single model. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||
|
||||
```bash
|
||||
python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```shell
|
||||
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||
@ -59,6 +61,7 @@ Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
|
||||
## Ensemble Test
|
||||
|
||||
Multiple pretrained models may be ensembled together at test and inference time by simply appending extra models to the `--weights` argument in any existing val.py or detect.py command. This example tests an ensemble of 2 models together:
|
||||
|
||||
- YOLOv5x
|
||||
- YOLOv5l6
|
||||
|
||||
@ -67,6 +70,7 @@ python val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```shell
|
||||
val: data=./data/coco.yaml, weights=['yolov5x.pt', 'yolov5l6.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||
@ -101,11 +105,13 @@ Evaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...
|
||||
## Ensemble Inference
|
||||
|
||||
Append extra models to the `--weights` argument to run ensemble inference:
|
||||
|
||||
```bash
|
||||
python detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```bash
|
||||
detect: weights=['yolov5x.pt', 'yolov5l6.pt'], source=data/images, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_width=3, hide_labels=False, hide_conf=False, half=False
|
||||
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||
@ -121,8 +127,8 @@ image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 3 persons, 2 ties, Don
|
||||
Results saved to runs/detect/exp2
|
||||
Done. (0.223s)
|
||||
```
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124489091-ea4f9a00-ddb0-11eb-8ef1-d6f335c97f6f.jpg" width="500">
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124489091-ea4f9a00-ddb0-11eb-8ef1-d6f335c97f6f.jpg" width="500">
|
||||
|
||||
## Environments
|
||||
|
||||
@ -133,7 +139,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Export YOLOv5 models to TFLite, ONNX, CoreML, and TensorRT formats. Achieve up to 5x GPU speedup using TensorRT. Benchmarks included.
|
||||
---
|
||||
|
||||
# TFLite, ONNX, CoreML, TensorRT Export
|
||||
@ -41,10 +42,10 @@ YOLOv5 inference is officially supported in 11 formats:
|
||||
| [TensorFlow.js](https://www.tensorflow.org/js) | `tfjs` | `yolov5s_web_model/` |
|
||||
| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov5s_paddle_model/` |
|
||||
|
||||
|
||||
## Benchmarks
|
||||
|
||||
Benchmarks below run on a Colab Pro with the YOLOv5 tutorial notebook <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>. To reproduce:
|
||||
|
||||
```bash
|
||||
python benchmarks.py --weights yolov5s.pt --imgsz 640 --device 0
|
||||
```
|
||||
@ -98,6 +99,7 @@ Benchmarks complete (241.20s)
|
||||
## Export a Trained YOLOv5 Model
|
||||
|
||||
This command exports a pretrained YOLOv5s model to TorchScript and ONNX formats. `yolov5s.pt` is the 'small' model, the second-smallest model available. Other options are `yolov5n.pt`, `yolov5m.pt`, `yolov5l.pt` and `yolov5x.pt`, along with their P6 counterparts i.e. `yolov5s6.pt` or you own custom training checkpoint i.e. `runs/exp/weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||
|
||||
```bash
|
||||
python export.py --weights yolov5s.pt --include torchscript onnx
|
||||
```
|
||||
@ -105,6 +107,7 @@ python export.py --weights yolov5s.pt --include torchscript onnx
|
||||
💡 ProTip: Add `--half` to export models at FP16 half precision for smaller file sizes
|
||||
|
||||
Output:
|
||||
|
||||
```bash
|
||||
export: data=data/coco128.yaml, weights=['yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['torchscript', 'onnx']
|
||||
YOLOv5 🚀 v6.2-104-ge3e5122 Python-3.7.13 torch-1.12.1+cu113 CPU
|
||||
@ -137,10 +140,10 @@ The 3 exported models will be saved alongside the original PyTorch model:
|
||||
[Netron Viewer](https://github.com/lutzroeder/netron) is recommended for visualizing exported models:
|
||||
<p align="center"><img width="850" src="https://user-images.githubusercontent.com/26833433/191003260-f94011a7-5b2e-4fe3-93c1-e1a935e0a728.png"></p>
|
||||
|
||||
|
||||
## Exported Model Usage Examples
|
||||
|
||||
`detect.py` runs inference on exported models:
|
||||
|
||||
```bash
|
||||
python detect.py --weights yolov5s.pt # PyTorch
|
||||
yolov5s.torchscript # TorchScript
|
||||
@ -156,6 +159,7 @@ python detect.py --weights yolov5s.pt # PyTorch
|
||||
```
|
||||
|
||||
`val.py` runs validation on exported models:
|
||||
|
||||
```bash
|
||||
python val.py --weights yolov5s.pt # PyTorch
|
||||
yolov5s.torchscript # TorchScript
|
||||
@ -171,6 +175,7 @@ python val.py --weights yolov5s.pt # PyTorch
|
||||
```
|
||||
|
||||
Use PyTorch Hub with exported YOLOv5 models:
|
||||
|
||||
``` python
|
||||
import torch
|
||||
|
||||
@ -200,6 +205,7 @@ results.print() # or .show(), .save(), .crop(), .pandas(), etc.
|
||||
## OpenCV DNN inference
|
||||
|
||||
OpenCV inference with ONNX models:
|
||||
|
||||
```bash
|
||||
python export.py --weights yolov5s.pt --include onnx
|
||||
|
||||
@ -232,7 +238,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to apply pruning to your YOLOv5 models. See the before and after performance with an explanation of sparsity and more.
|
||||
---
|
||||
|
||||
📚 This guide explains how to apply **pruning** to YOLOv5 🚀 models.
|
||||
@ -18,11 +19,13 @@ pip install -r requirements.txt # install
|
||||
## Test Normally
|
||||
|
||||
Before pruning we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||
|
||||
```bash
|
||||
python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```shell
|
||||
val: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False
|
||||
YOLOv5 🚀 v6.0-224-g4c40933 torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)
|
||||
@ -58,6 +61,7 @@ We repeat the above test with a pruned model by using the `torch_utils.prune()`
|
||||
<img width="894" alt="Screenshot 2022-02-02 at 22 54 18" src="https://user-images.githubusercontent.com/26833433/152243799-b0ac2777-b1a8-47b1-801a-2e4c93c06ead.png">
|
||||
|
||||
30% pruned output:
|
||||
|
||||
```bash
|
||||
val: data=/content/yolov5/data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False
|
||||
YOLOv5 🚀 v6.0-224-g4c40933 torch 1.10.0+cu111 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)
|
||||
@ -89,7 +93,6 @@ Results saved to runs/val/exp3
|
||||
|
||||
In the results we can observe that we have achieved a **sparsity of 30%** in our model after pruning, which means that 30% of the model's weight parameters in `nn.Conv2d` layers are equal to 0. **Inference time is essentially unchanged**, while the model's **AP and AR scores a slightly reduced**.
|
||||
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
@ -99,7 +102,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to train your dataset on single or multiple machines using YOLOv5 on multiple GPUs. Use simple commands with DDP mode for faster performance.
|
||||
---
|
||||
|
||||
📚 This guide explains how to properly use **multiple** GPUs to train a dataset with YOLOv5 🚀 on single or multiple machine(s).
|
||||
@ -21,11 +22,10 @@ pip install -r requirements.txt # install
|
||||
|
||||
## Training
|
||||
|
||||
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.
|
||||
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.
|
||||
|
||||
<p align="center"><img width="700" alt="YOLOv5 Models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||
|
||||
|
||||
### Single GPU
|
||||
|
||||
```bash
|
||||
@ -35,6 +35,7 @@ python train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0
|
||||
### Multi-GPU [DataParallel](https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel) Mode (⚠️ not recommended)
|
||||
|
||||
You can increase the `device` to use Multiple GPUs in DataParallel mode.
|
||||
|
||||
```bash
|
||||
python train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0,1
|
||||
```
|
||||
@ -68,21 +69,22 @@ python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data co
|
||||
<details markdown>
|
||||
<summary>Use SyncBatchNorm (click to expand)</summary>
|
||||
|
||||
[SyncBatchNorm](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html) could increase accuracy for multiple gpu training, however, it will slow down training by a significant factor. It is **only** available for Multiple GPU DistributedDataParallel training.
|
||||
[SyncBatchNorm](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html) could increase accuracy for multiple gpu training, however, it will slow down training by a significant factor. It is **only** available for Multiple GPU DistributedDataParallel training.
|
||||
|
||||
It is best used when the batch-size on **each** GPU is small (<= 8).
|
||||
|
||||
To use SyncBatchNorm, simple pass `--sync-bn` to the command like below,
|
||||
To use SyncBatchNorm, simple pass `--sync-bn` to the command like below,
|
||||
|
||||
```bash
|
||||
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --sync-bn
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<details markdown>
|
||||
<summary>Use Multiple machines (click to expand)</summary>
|
||||
|
||||
This is **only** available for Multiple GPU DistributedDataParallel training.
|
||||
This is **only** available for Multiple GPU DistributedDataParallel training.
|
||||
|
||||
Before we continue, make sure the files on all machines are the same, dataset, codebase, etc. Afterwards, make sure the machines can communicate to each other.
|
||||
|
||||
@ -94,18 +96,19 @@ To use it, you can do as the following,
|
||||
# On master machine 0
|
||||
python -m torch.distributed.run --nproc_per_node G --nnodes N --node_rank 0 --master_addr "192.168.1.1" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''
|
||||
```
|
||||
|
||||
```bash
|
||||
# On machine R
|
||||
python -m torch.distributed.run --nproc_per_node G --nnodes N --node_rank R --master_addr "192.168.1.1" --master_port 1234 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights ''
|
||||
```
|
||||
where `G` is number of GPU per machine, `N` is the number of machines, and `R` is the machine number from `0...(N-1)`.
|
||||
|
||||
where `G` is number of GPU per machine, `N` is the number of machines, and `R` is the machine number from `0...(N-1)`.
|
||||
Let's say I have two machines with two GPUs each, it would be `G = 2` , `N = 2`, and `R = 1` for the above.
|
||||
|
||||
Training will not start until <b>all </b> `N` machines are connected. Output will only be shown on master machine!
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
### Notes
|
||||
|
||||
- Windows support is untested, Linux is recommended.
|
||||
@ -167,7 +170,6 @@ If you went through all the above, feel free to raise an Issue by giving as much
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
@ -177,14 +179,12 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||
|
||||
|
||||
## Credits
|
||||
|
||||
I would like to thank @MagicFrogSJTU, who did all the heavy lifting, and @glenn-jocher for guiding us along the way.
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to deploy YOLOv5 with DeepSparse to achieve exceptional CPU performance close to GPUs, using pruning, and quantization.<br>
|
||||
---
|
||||
|
||||
<!--
|
||||
@ -30,17 +31,18 @@ DeepSparse is an inference runtime with exceptional performance on CPUs. For ins
|
||||
|
||||
For the first time, your deep learning workloads can meet the performance demands of production without the complexity and costs of hardware accelerators.
|
||||
Put simply, DeepSparse gives you the performance of GPUs and the simplicity of software:
|
||||
|
||||
- **Flexible Deployments**: Run consistently across cloud, data center, and edge with any hardware provider from Intel to AMD to ARM
|
||||
- **Infinite Scalability**: Scale vertically to 100s of cores, out with standard Kubernetes, or fully-abstracted with Serverless
|
||||
- **Easy Integration**: Clean APIs for integrating your model into an application and monitoring it in production
|
||||
|
||||
### How Does DeepSparse Achieve GPU-Class Performance?
|
||||
|
||||
DeepSparse takes advantage of model sparsity to gain its performance speedup.
|
||||
DeepSparse takes advantage of model sparsity to gain its performance speedup.
|
||||
|
||||
Sparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to
|
||||
Sparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to
|
||||
execute a network, while maintaining high accuracy. DeepSparse is sparsity-aware, meaning it skips the zeroed out parameters, shrinking amount of compute
|
||||
in a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns,
|
||||
in a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns,
|
||||
vertical stripes of computation that fit in cache.
|
||||
|
||||
<p align="center">
|
||||
@ -70,10 +72,12 @@ pip install deepsparse[server,yolo,onnxruntime]
|
||||
### Collect an ONNX File
|
||||
|
||||
DeepSparse accepts a model in the ONNX format, passed either as:
|
||||
|
||||
- A SparseZoo stub which identifies an ONNX file in the SparseZoo
|
||||
- A local path to an ONNX model in a filesystem
|
||||
|
||||
The examples below use the standard dense and pruned-quantized YOLOv5s checkpoints, identified by the following SparseZoo stubs:
|
||||
|
||||
```bash
|
||||
zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-none
|
||||
zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
|
||||
@ -81,16 +85,17 @@ zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none
|
||||
|
||||
### Deploy a Model
|
||||
|
||||
DeepSparse offers convenient APIs for integrating your model into an application.
|
||||
DeepSparse offers convenient APIs for integrating your model into an application.
|
||||
|
||||
To try the deployment examples below, pull down a sample image and save it as `basilica.jpg` with the following:
|
||||
|
||||
```bash
|
||||
wget -O basilica.jpg https://raw.githubusercontent.com/neuralmagic/deepsparse/main/src/deepsparse/yolo/sample_images/basilica.jpg
|
||||
```
|
||||
|
||||
#### Python API
|
||||
|
||||
`Pipelines` wrap pre-processing and output post-processing around the runtime, providing a clean interface for adding DeepSparse to an application.
|
||||
|
||||
`Pipelines` wrap pre-processing and output post-processing around the runtime, providing a clean interface for adding DeepSparse to an application.
|
||||
The DeepSparse-Ultralytics integration includes an out-of-the-box `Pipeline` that accepts raw images and outputs the bounding boxes.
|
||||
|
||||
Create a `Pipeline` and run inference:
|
||||
@ -120,9 +125,9 @@ apt-get install libgl1-mesa-glx
|
||||
```
|
||||
|
||||
#### HTTP Server
|
||||
|
||||
DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model
|
||||
service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw
|
||||
|
||||
DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model
|
||||
service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw
|
||||
images to the endpoint and receive the bounding boxes.
|
||||
|
||||
Spin up the Server with the pruned-quantized YOLOv5s:
|
||||
@ -134,6 +139,7 @@ deepsparse.server \
|
||||
```
|
||||
|
||||
An example request, using Python's `requests` package:
|
||||
|
||||
```python
|
||||
import requests, json
|
||||
|
||||
@ -152,7 +158,9 @@ labels = annotations["labels"]
|
||||
```
|
||||
|
||||
#### Annotate CLI
|
||||
|
||||
You can also use the annotate command to have the engine save an annotated photo on disk. Try --source 0 to annotate your live webcam feed!
|
||||
|
||||
```bash
|
||||
deepsparse.object_detection.annotate --model_filepath zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65_quant-none --source basilica.jpg
|
||||
```
|
||||
@ -167,7 +175,7 @@ Running the above command will create an `annotation-results` folder and save th
|
||||
|
||||
We will compare DeepSparse's throughput to ONNX Runtime's throughput on YOLOv5s, using DeepSparse's benchmarking script.
|
||||
|
||||
The benchmarks were run on an AWS `c6i.8xlarge` instance (16 cores).
|
||||
The benchmarks were run on an AWS `c6i.8xlarge` instance (16 cores).
|
||||
|
||||
### Batch 32 Performance Comparison
|
||||
|
||||
@ -186,7 +194,7 @@ deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-non
|
||||
|
||||
#### DeepSparse Dense Performance
|
||||
|
||||
While DeepSparse offers its best performance with optimized sparse models, it also performs well with the standard dense YOLOv5s.
|
||||
While DeepSparse offers its best performance with optimized sparse models, it also performs well with the standard dense YOLOv5s.
|
||||
|
||||
At batch 32, DeepSparse achieves 70 images/sec with the standard dense YOLOv5s, a **1.7x performance improvement over ORT**!
|
||||
|
||||
@ -198,6 +206,7 @@ deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/base-non
|
||||
> Scenario: sync
|
||||
> Throughput (items/sec): 69.5546
|
||||
```
|
||||
|
||||
#### DeepSparse Sparse Performance
|
||||
|
||||
When sparsity is applied to the model, DeepSparse's performance gains over ONNX Runtime is even stronger.
|
||||
@ -218,6 +227,7 @@ deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65
|
||||
DeepSparse is also able to gain a speed-up over ONNX Runtime for the latency-sensitive, batch 1 scenario.
|
||||
|
||||
#### ONNX Runtime Baseline
|
||||
|
||||
At batch 1, ONNX Runtime achieves 48 images/sec with the standard, dense YOLOv5s.
|
||||
|
||||
```bash
|
||||
@ -242,7 +252,7 @@ deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned65
|
||||
> Throughput (items/sec): 134.9468
|
||||
```
|
||||
|
||||
Since `c6i.8xlarge` instances have VNNI instructions, DeepSparse's throughput can be pushed further if weights are pruned in blocks of 4.
|
||||
Since `c6i.8xlarge` instances have VNNI instructions, DeepSparse's throughput can be pushed further if weights are pruned in blocks of 4.
|
||||
|
||||
At batch 1, DeepSparse achieves 180 items/sec with a 4-block pruned-quantized YOLOv5s, a **3.7x performance gain over ONNX Runtime!**
|
||||
|
||||
@ -257,4 +267,4 @@ deepsparse.benchmark zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned35
|
||||
|
||||
## Get Started With DeepSparse
|
||||
|
||||
**Research or Testing?** DeepSparse Community is free for research and testing. Get started with our [Documentation](https://docs.neuralmagic.com/).
|
||||
**Research or Testing?** DeepSparse Community is free for research and testing. Get started with our [Documentation](https://docs.neuralmagic.com/).
|
||||
@ -1,8 +1,9 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to load YOLOv5🚀 from PyTorch Hub at https://pytorch.org/hub/ultralytics_yolov5 and perform image inference. UPDATED 26 March 2023.
|
||||
---
|
||||
|
||||
📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5).
|
||||
📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5).
|
||||
UPDATED 26 March 2023.
|
||||
|
||||
## Before You Start
|
||||
@ -20,6 +21,7 @@ pip install -r https://raw.githubusercontent.com/ultralytics/yolov5/master/requi
|
||||
### Simple Example
|
||||
|
||||
This example loads a pretrained YOLOv5s model from PyTorch Hub as `model` and passes an image for inference. `'yolov5s'` is the lightest and fastest YOLOv5 model. For details on all available models please see the [README](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
@ -40,10 +42,10 @@ results.pandas().xyxy[0]
|
||||
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||
```
|
||||
|
||||
|
||||
### Detailed Example
|
||||
|
||||
This example shows **batched inference** with **PIL** and **OpenCV** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
|
||||
|
||||
```python
|
||||
import cv2
|
||||
import torch
|
||||
@ -73,12 +75,15 @@ results.pandas().xyxy[0] # im1 predictions (pandas)
|
||||
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
|
||||
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||
```
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124915064-62a49e00-dff1-11eb-86b3-a85b97061afb.jpg" width="500"> <img src="https://user-images.githubusercontent.com/26833433/124915055-60424400-dff1-11eb-9055-24585b375a29.jpg" width="300">
|
||||
|
||||
For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
|
||||
|
||||
### Inference Settings
|
||||
|
||||
YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
|
||||
|
||||
```python
|
||||
model.conf = 0.25 # NMS confidence threshold
|
||||
iou = 0.45 # NMS IoU threshold
|
||||
@ -91,9 +96,10 @@ model.conf = 0.25 # NMS confidence threshold
|
||||
results = model(im, size=320) # custom inference size
|
||||
```
|
||||
|
||||
|
||||
### Device
|
||||
|
||||
Models can be transferred to any device after creation:
|
||||
|
||||
```python
|
||||
model.cpu() # CPU
|
||||
model.cuda() # GPU
|
||||
@ -101,6 +107,7 @@ model.to(device) # i.e. device=torch.device(0)
|
||||
```
|
||||
|
||||
Models can also be created directly on any `device`:
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
|
||||
```
|
||||
@ -108,33 +115,45 @@ model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on
|
||||
💡 ProTip: Input images are automatically transferred to the correct model device before inference.
|
||||
|
||||
### Silence Outputs
|
||||
|
||||
Models can be loaded silently with `_verbose=False`:
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
|
||||
```
|
||||
|
||||
### Input Channels
|
||||
|
||||
To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
|
||||
```
|
||||
|
||||
In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
|
||||
|
||||
### Number of Classes
|
||||
|
||||
To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
|
||||
```
|
||||
|
||||
In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
|
||||
|
||||
### Force Reload
|
||||
|
||||
If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
|
||||
```
|
||||
|
||||
### Screenshot Inference
|
||||
|
||||
To run inference on your desktop screen:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from PIL import ImageGrab
|
||||
@ -171,14 +190,18 @@ threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.j
|
||||
```
|
||||
|
||||
### Training
|
||||
To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) for model training.
|
||||
|
||||
To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) for model training.
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
|
||||
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
|
||||
```
|
||||
|
||||
### Base64 Results
|
||||
|
||||
For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
|
||||
|
||||
```python
|
||||
results = model(im) # inference
|
||||
|
||||
@ -192,18 +215,23 @@ for im in results.ims:
|
||||
```
|
||||
|
||||
### Cropped Results
|
||||
|
||||
Results can be returned and saved as detection crops:
|
||||
|
||||
```python
|
||||
results = model(im) # inference
|
||||
crops = results.crop(save=True) # cropped detections dictionary
|
||||
```
|
||||
|
||||
### Pandas Results
|
||||
|
||||
Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
|
||||
|
||||
```python
|
||||
results = model(im) # inference
|
||||
results.pandas().xyxy[0] # Pandas DataFrame
|
||||
```
|
||||
|
||||
<details markdown>
|
||||
<summary>Pandas Output (click to expand)</summary>
|
||||
|
||||
@ -215,24 +243,31 @@ print(results.pandas().xyxy[0])
|
||||
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
|
||||
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
### Sorted Results
|
||||
|
||||
Results can be sorted by column, i.e. to sort license plate digit detection left-to-right (x-axis):
|
||||
|
||||
```python
|
||||
results = model(im) # inference
|
||||
results.pandas().xyxy[0].sort_values('xmin') # sorted left-right
|
||||
```
|
||||
|
||||
### Box-Cropped Results
|
||||
|
||||
Results can be returned and saved as detection crops:
|
||||
|
||||
```python
|
||||
results = model(im) # inference
|
||||
crops = results.crop(save=True) # cropped detections dictionary
|
||||
```
|
||||
|
||||
### JSON Results
|
||||
|
||||
Results can be returned in JSON format once converted to `.pandas()` dataframes using the `.to_json()` method. The JSON format can be modified using the `orient` argument. See pandas `.to_json()` [documentation](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_json.html) for details.
|
||||
|
||||
```python
|
||||
results = model(ims) # inference
|
||||
results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
|
||||
@ -253,7 +288,9 @@ results.pandas().xyxy[0].to_json(orient="records") # JSON img1 predictions
|
||||
</details>
|
||||
|
||||
## Custom Models
|
||||
|
||||
This example loads a custom 20-class [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml)-trained YOLOv5s model `'best.pt'` with PyTorch Hub.
|
||||
|
||||
```python
|
||||
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model
|
||||
model = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo
|
||||
@ -286,7 +323,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Use Roboflow to organize, label, prepare, version & host datasets for training YOLOv5 models. Upload via UI, API, or Python, making versions with custom preprocessing and offline augmentation. Export in YOLOv5 format and access custom training tutorials. Use active learning to improve model deployments.
|
||||
---
|
||||
|
||||
# Roboflow Datasets
|
||||
@ -8,19 +9,23 @@ You can now use Roboflow to organize, label, prepare, version, and host your dat
|
||||
UPDATED 30 September 2021.
|
||||
|
||||
## Upload
|
||||
|
||||
You can upload your data to Roboflow via [web UI](https://docs.roboflow.com/adding-data), [rest API](https://docs.roboflow.com/adding-data/upload-api), or [python](https://docs.roboflow.com/python).
|
||||
|
||||
## Labeling
|
||||
|
||||
After uploading data to Roboflow, you can label your data and review previous labels.
|
||||
|
||||
[](https://roboflow.com/annotate)
|
||||
|
||||
## Versioning
|
||||
|
||||
You can make versions of your dataset with different preprocessing and offline augmentation options. YOLOv5 does online augmentations natively, so be intentional when layering Roboflow's offline augs on top.
|
||||
|
||||

|
||||
|
||||
## Exporting Data
|
||||
|
||||
You can download your data in YOLOv5 format to quickly begin training.
|
||||
|
||||
```
|
||||
@ -31,11 +36,13 @@ dataset = project.version("YOUR VERSION").download("yolov5")
|
||||
```
|
||||
|
||||
## Custom Training
|
||||
|
||||
We have released a custom training tutorial demonstrating all of the above capabilities. You can access the code here:
|
||||
|
||||
[](https://colab.research.google.com/github/roboflow-ai/yolov5-custom-training-tutorial/blob/main/yolov5-custom-training.ipynb)
|
||||
|
||||
## Active Learning
|
||||
|
||||
The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.
|
||||
|
||||
<p align=""><a href="https://roboflow.com/?ref=ultralytics"><img width="1000" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/615627e5824c9c6195abfda9_computer-vision-cycle.png"/></a></p>
|
||||
<p align=""><a href="https://roboflow.com/?ref=ultralytics"><img width="1000" src="https://uploads-ssl.webflow.com/5f6bc60e665f54545a1e52a5/615627e5824c9c6195abfda9_computer-vision-cycle.png"/></a></p>
|
||||
@ -1,11 +1,12 @@
|
||||
---
|
||||
comments: true
|
||||
description: Deploy YOLOv5 on NVIDIA Jetson using TensorRT and DeepStream SDK for high performance inference. Step-by-step guide with code snippets.
|
||||
---
|
||||
|
||||
# Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
|
||||
|
||||
📚 This guide explains how to deploy a trained model into NVIDIA Jetson Platform and perform inference using TensorRT and DeepStream SDK. Here we use TensorRT to maximize the inference performance on the Jetson platform.
|
||||
UPDATED 18 November 2022.
|
||||
UPDATED 18 November 2022.
|
||||
|
||||
## Hardware Verification
|
||||
|
||||
@ -27,8 +28,7 @@ There are two major installation methods including,
|
||||
|
||||
You can find a very detailed installation guide from NVIDIA [official website](https://developer.nvidia.com/jetpack-sdk-461). You can also find guides corresponding to the above-mentioned [reComputer J1010](https://wiki.seeedstudio.com/reComputer_J1010_J101_Flash_Jetpack) and [reComputer J2021](https://wiki.seeedstudio.com/reComputer_J2021_J202_Flash_Jetpack).
|
||||
|
||||
|
||||
## Install Necessary Packages
|
||||
## Install Necessary Packages
|
||||
|
||||
- **Step 1.** Access the terminal of Jetson device, install pip and upgrade it
|
||||
|
||||
@ -89,7 +89,7 @@ Supported by JetPack 4.4 (L4T R32.4.3) / JetPack 4.4.1 (L4T R32.4.4) / JetPack 4
|
||||
|
||||
**PyTorch v1.12.0**
|
||||
|
||||
Supported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8
|
||||
Supported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8
|
||||
|
||||
**file_name:** torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
|
||||
**URL:** [https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl](https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl)
|
||||
@ -133,7 +133,7 @@ cd ~
|
||||
git clone https://github.com/marcoslucianops/DeepStream-Yolo
|
||||
```
|
||||
|
||||
- **Step 2.** Copy **gen_wts_yoloV5.py** from **DeepStream-Yolo/utils** into **yolov5** directory
|
||||
- **Step 2.** Copy **gen_wts_yoloV5.py** from **DeepStream-Yolo/utils** into **yolov5** directory
|
||||
|
||||
```sh
|
||||
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
|
||||
@ -222,7 +222,7 @@ The above result is running on **Jetson Xavier NX** with **FP32** and **YOLOv5s
|
||||
|
||||
## INT8 Calibration
|
||||
|
||||
If you want to use INT8 precision for inference, you need to follow the steps below
|
||||
If you want to use INT8 precision for inference, you need to follow the steps below
|
||||
|
||||
- **Step 1.** Install OpenCV
|
||||
|
||||
@ -254,7 +254,7 @@ for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
|
||||
done
|
||||
```
|
||||
|
||||
**Note:** NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
|
||||
**Note:** NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
|
||||
|
||||
- **Step 6.** Create the **calibration.txt** file with all selected images
|
||||
|
||||
@ -305,7 +305,7 @@ The above result is running on **Jetson Xavier NX** with **INT8** and **YOLOv5s
|
||||
|
||||
## Benchmark results
|
||||
|
||||
The following table summarizes how different models perform on **Jetson Xavier NX**.
|
||||
The following table summarizes how different models perform on **Jetson Xavier NX**.
|
||||
|
||||
| Model Name | Precision | Inference Size | Inference Time (ms) | FPS |
|
||||
|------------|-----------|----------------|---------------------|-----|
|
||||
@ -314,7 +314,6 @@ The following table summarizes how different models perform on **Jetson Xavier N
|
||||
| | INT8 | 640x640 | 16.66 | 60 |
|
||||
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
|
||||
|
||||
|
||||
### Additional
|
||||
|
||||
This tutorial is written by our friends at seeed @lakshanthad and Elaine
|
||||
This tutorial is written by our friends at seeed @lakshanthad and Elaine
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to use Test Time Augmentation (TTA) with YOLOv5 to improve mAP and Recall during testing and inference. Code examples included.
|
||||
---
|
||||
|
||||
# Test-Time Augmentation (TTA)
|
||||
@ -20,11 +21,13 @@ pip install -r requirements.txt # install
|
||||
## Test Normally
|
||||
|
||||
Before trying TTA we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
|
||||
|
||||
```bash
|
||||
python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```shell
|
||||
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||
@ -55,12 +58,15 @@ Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
|
||||
```
|
||||
|
||||
## Test with TTA
|
||||
|
||||
Append `--augment` to any existing `val.py` command to enable TTA, and increase the image size by about 30% for improved results. Note that inference with TTA enabled will typically take about 2-3X the time of normal inference as the images are being left-right flipped and processed at 3 different resolutions, with the outputs merged before NMS. Part of the speed decrease is simply due to larger image sizes (832 vs 640), while part is due to the actual TTA operations.
|
||||
|
||||
```bash
|
||||
python val.py --weights yolov5x.pt --data coco.yaml --img 832 --augment --half
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```shell
|
||||
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=832, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=True, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
|
||||
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||
@ -94,11 +100,13 @@ Evaluating pycocotools mAP... saving runs/val/exp2/yolov5x_predictions.json...
|
||||
## Inference with TTA
|
||||
|
||||
`detect.py` TTA inference operates identically to `val.py` TTA: simply append `--augment` to any existing `detect.py` command:
|
||||
|
||||
```bash
|
||||
python detect.py --weights yolov5s.pt --img 832 --source data/images --augment
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```bash
|
||||
detect: weights=['yolov5s.pt'], source=data/images, imgsz=832, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=True, update=False, project=runs/detect, name=exp, exist_ok=False, line_width=3, hide_labels=False, hide_conf=False, half=False
|
||||
YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
|
||||
@ -116,10 +124,10 @@ Done. (0.156s)
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26833433/124491703-dbb6b200-ddb3-11eb-8b57-ed0d58d0d8b4.jpg" width="500">
|
||||
|
||||
|
||||
### PyTorch Hub TTA
|
||||
|
||||
TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
@ -136,11 +144,10 @@ results = model(img, augment=True) # <--- TTA inference
|
||||
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
|
||||
```
|
||||
|
||||
### Customize
|
||||
### Customize
|
||||
|
||||
You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).
|
||||
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
@ -150,7 +157,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get the most out of YOLOv5 with this guide; producing best results, checking dataset, hypertuning & more. Updated May 2022.
|
||||
---
|
||||
|
||||
📚 This guide explains how to produce the best mAP and training results with YOLOv5 🚀.
|
||||
@ -23,14 +24,14 @@ We've put together a full guide for users looking to get the best results on the
|
||||
|
||||
<a href="https://arxiv.org/abs/1405.0312"><img width="800" src="https://user-images.githubusercontent.com/26833433/109398377-82b0ac00-78f1-11eb-9c76-cc7820669d0d.png" alt="COCO Analysis"></a>
|
||||
|
||||
|
||||
## Model Selection
|
||||
|
||||
Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
|
||||
Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
|
||||
|
||||
<p align="center"><img width="700" alt="YOLOv5 Models" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/model_comparison.png"></p>
|
||||
|
||||
- **Start from Pretrained weights.** Recommended for small to medium-sized datasets (i.e. [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml)). Pass the name of the model to the `--weights` argument. Models download automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases).
|
||||
|
||||
```shell
|
||||
python train.py --data custom.yaml --weights yolov5s.pt
|
||||
yolov5m.pt
|
||||
@ -38,7 +39,9 @@ python train.py --data custom.yaml --weights yolov5s.pt
|
||||
yolov5x.pt
|
||||
custom_pretrained.pt
|
||||
```
|
||||
|
||||
- **Start from Scratch.** Recommended for large datasets (i.e. [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [OIv6](https://storage.googleapis.com/openimages/web/index.html)). Pass the model architecture yaml you are interested in, along with an empty `--weights ''` argument:
|
||||
|
||||
```bash
|
||||
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
|
||||
yolov5m.yaml
|
||||
@ -46,7 +49,6 @@ python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
|
||||
yolov5x.yaml
|
||||
```
|
||||
|
||||
|
||||
## Training Settings
|
||||
|
||||
Before modifying anything, **first train with default settings to establish a performance baseline**. A full list of train.py settings can be found in the [train.py](https://github.com/ultralytics/yolov5/blob/master/train.py) argparser.
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
---
|
||||
comments: true
|
||||
description: Train your custom dataset with YOLOv5. Learn to collect, label and annotate images, and train and deploy models. Get started now.
|
||||
---
|
||||
|
||||
📚 This guide explains how to train your own **custom dataset** with [YOLOv5](https://github.com/ultralytics/yolov5) 🚀.
|
||||
@ -84,6 +85,7 @@ Now continue with `2. Select a Model`.
|
||||
### 1.1 Create dataset.yaml
|
||||
|
||||
[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](http://cocodataset.org/#home) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or *.txt files with image paths) and 2) a class `names` dictionary:
|
||||
|
||||
```yaml
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
||||
path: ../datasets/coco128 # dataset root dir
|
||||
@ -102,7 +104,6 @@ names:
|
||||
79: toothbrush
|
||||
```
|
||||
|
||||
|
||||
### 1.2 Create Labels
|
||||
|
||||
After using an annotation tool to label your images, export your labels to **YOLO format**, with one `*.txt` file per image (if no objects in image, no `*.txt` file is required). The `*.txt` file specifications are:
|
||||
@ -118,10 +119,10 @@ The label file corresponding to the above image contains 2 persons (class `0`) a
|
||||
|
||||
<p align="center"><img width="428" src="https://user-images.githubusercontent.com/26833433/112467037-d2568c00-8d66-11eb-8796-55402ac0d62f.png"></p>
|
||||
|
||||
|
||||
### 1.3 Organize Directories
|
||||
|
||||
Organize your train and val images and labels according to the example below. YOLOv5 assumes `/coco128` is inside a `/datasets` directory **next to** the `/yolov5` directory. **YOLOv5 locates labels automatically for each image** by replacing the last instance of `/images/` in each image path with `/labels/`. For example:
|
||||
|
||||
```bash
|
||||
../datasets/coco128/images/im0.jpg # image
|
||||
../datasets/coco128/labels/im0.txt # label
|
||||
@ -130,7 +131,6 @@ Organize your train and val images and labels according to the example below. YO
|
||||
<p align="center"><img width="700" src="https://user-images.githubusercontent.com/26833433/134436012-65111ad1-9541-4853-81a6-f19a3468b75f.png"></p>
|
||||
</details>
|
||||
|
||||
|
||||
### 2. Select a Model
|
||||
|
||||
Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the second-smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
|
||||
@ -144,6 +144,7 @@ Train a YOLOv5s model on COCO128 by specifying dataset, batch-size, image size a
|
||||
```bash
|
||||
python train.py --img 640 --epochs 3 --data coco128.yaml --weights yolov5s.pt
|
||||
```
|
||||
|
||||
!!! tip "Tip"
|
||||
|
||||
💡 Add `--cache ram` or `--cache disk` to speed up training (requires significant RAM/disk resources).
|
||||
@ -158,9 +159,10 @@ All training results are saved to `runs/train/` with incrementing run directorie
|
||||
|
||||
#### Comet Logging and Visualization 🌟 NEW
|
||||
|
||||
[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
|
||||
[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
|
||||
|
||||
Getting started is easy:
|
||||
|
||||
```shell
|
||||
pip install comet_ml # 1. install
|
||||
export COMET_API_KEY=<Your API Key> # 2. paste API key
|
||||
@ -186,12 +188,11 @@ You can use ClearML Data to version your dataset and then pass it to YOLOv5 simp
|
||||
<a href="https://cutt.ly/yolov5-notebook-clearml">
|
||||
<img alt="ClearML Experiment Management UI" src="https://github.com/thepycoder/clearml_screenshots/raw/main/scalars.jpg" width="1280"/></a>
|
||||
|
||||
|
||||
#### Local Logging
|
||||
|
||||
Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
|
||||
|
||||
This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
|
||||
This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
|
||||
|
||||
<img alt="Local logging results" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/image-local_logging.jpg" width="1280"/>
|
||||
|
||||
@ -204,18 +205,16 @@ plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
|
||||
|
||||
<p align="center"><img width="800" alt="results.png" src="https://github.com/ultralytics/yolov5/releases/download/v1.0/results.png"></p>
|
||||
|
||||
|
||||
|
||||
## Next Steps
|
||||
|
||||
Once your model is trained you can use your best checkpoint `best.pt` to:
|
||||
|
||||
* Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference on new images and videos
|
||||
* [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
|
||||
* [Export](https://docs.ultralytics.com/yolov5/tutorials/model_export) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
|
||||
* [Evolve](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution) hyperparameters to improve performance
|
||||
* [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
|
||||
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
@ -225,9 +224,8 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
|
||||
@ -1,11 +1,11 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to freeze YOLOv5 when transfer learning. Retrain a pre-trained model on new data faster and with fewer resources.
|
||||
---
|
||||
|
||||
📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
|
||||
UPDATED 25 September 2022.
|
||||
|
||||
|
||||
## Before You Start
|
||||
|
||||
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
||||
@ -19,6 +19,7 @@ pip install -r requirements.txt # install
|
||||
## Freeze Backbone
|
||||
|
||||
All layers that match the train.py `freeze` list in train.py will be frozen by setting their gradients to zero before training starts.
|
||||
|
||||
```python
|
||||
# Freeze
|
||||
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
|
||||
@ -30,6 +31,7 @@ All layers that match the train.py `freeze` list in train.py will be frozen by s
|
||||
```
|
||||
|
||||
To see a list of module names:
|
||||
|
||||
```python
|
||||
for k, v in model.named_parameters():
|
||||
print(k)
|
||||
@ -55,6 +57,7 @@ model.24.m.2.bias
|
||||
```
|
||||
|
||||
Looking at the model architecture we can see that the model backbone is layers 0-9:
|
||||
|
||||
```yaml
|
||||
# YOLOv5 backbone
|
||||
backbone:
|
||||
@ -96,6 +99,7 @@ Looking at the model architecture we can see that the model backbone is layers 0
|
||||
```
|
||||
|
||||
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
|
||||
|
||||
```bash
|
||||
python train.py --freeze 10
|
||||
```
|
||||
@ -103,6 +107,7 @@ python train.py --freeze 10
|
||||
## Freeze All Layers
|
||||
|
||||
To freeze the full model except for the final output convolution layers in Detect(), we set freeze list to contain all modules with 'model.0.' - 'model.23.' in their names:
|
||||
|
||||
```bash
|
||||
python train.py --freeze 24
|
||||
```
|
||||
@ -110,6 +115,7 @@ python train.py --freeze 24
|
||||
## Results
|
||||
|
||||
We train YOLOv5m on VOC on both of the above scenarios, along with a default model (no freezing), starting from the official COCO pretrained `--weights yolov5m.pt`:
|
||||
|
||||
```python
|
||||
train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yaml
|
||||
```
|
||||
@ -132,7 +138,6 @@ Interestingly, the more modules are frozen the less GPU memory is required to tr
|
||||
|
||||
|
||||
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
@ -142,7 +147,6 @@ YOLOv5 may be run in any of the following up-to-date verified environments (with
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
|
||||
- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
Reference in New Issue
Block a user