Docs updates for HUB, YOLOv4, YOLOv7, NAS (#3174)
Co-authored-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
This commit is contained in:
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with YOLOv5 on AWS. Our comprehensive guide provides everything you need to know to run YOLOv5 on an Amazon Deep Learning instance.
|
||||
keywords: YOLOv5, AWS, Deep Learning, Instance, Guide, Quickstart
|
||||
---
|
||||
|
||||
# YOLOv5 🚀 on AWS Deep Learning Instance: A Comprehensive Guide
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get started with YOLOv5 in a Docker container. Learn to set up and run YOLOv5 models and explore other quickstart options. 🚀
|
||||
keywords: YOLOv5, Docker, tutorial, setup, training, testing, detection
|
||||
---
|
||||
|
||||
# Get Started with YOLOv5 🚀 in Docker
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Set up YOLOv5 on a Google Cloud Platform (GCP) Deep Learning VM. Train, test, detect, and export YOLOv5 models. Tutorial updated April 2023.
|
||||
keywords: YOLOv5, GCP, deep learning, tutorial, Google Cloud Platform, virtual machine, VM, setup, free credit, Colab Notebook, AWS, Docker
|
||||
---
|
||||
|
||||
# Run YOLOv5 🚀 on Google Cloud Platform (GCP) Deep Learning Virtual Machine (VM) ⭐
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
---
|
||||
comments: true
|
||||
description: Discover the YOLOv5 object detection model designed to deliver fast and accurate real-time results. Let's dive into this documentation to harness its full potential!
|
||||
description: Explore the extensive functionalities of the YOLOv5 object detection model, renowned for its speed and precision. Dive into our comprehensive guide for installation, architectural insights, use-cases, and more to unlock the full potential of YOLOv5 for your computer vision applications.
|
||||
keywords: ultralytics, yolov5, object detection, deep learning, pytorch, computer vision, tutorial, architecture, documentation, frameworks, real-time, model training, multicore, multithreading
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv5
|
||||
# Comprehensive Guide to Ultralytics YOLOv5
|
||||
|
||||
<div align="center">
|
||||
<p>
|
||||
@ -21,54 +22,48 @@ description: Discover the YOLOv5 object detection model designed to deliver fast
|
||||
<br>
|
||||
<br>
|
||||
|
||||
Welcome to the Ultralytics YOLOv5 🚀 Docs! YOLOv5, or You Only Look Once version 5, is an Ultralytics object detection model designed to deliver fast and accurate real-time results.
|
||||
Welcome to the Ultralytics' YOLOv5 🚀 Documentation! YOLOv5, the fifth iteration of the revolutionary "You Only Look Once" object detection model, is designed to deliver high-speed, high-accuracy results in real-time.
|
||||
<br><br>
|
||||
This powerful deep learning framework is built on the PyTorch platform and has gained immense popularity due to its ease of use, high performance, and versatility. In this documentation, we will guide you through the installation process, explain the model's architecture, showcase various use-cases, and provide detailed tutorials to help you harness the full potential of YOLOv5 for your computer vision projects. Let's dive in!
|
||||
Built on PyTorch, this powerful deep learning framework has garnered immense popularity for its versatility, ease of use, and high performance. Our documentation guides you through the installation process, explains the architectural nuances of the model, showcases various use-cases, and provides a series of detailed tutorials. These resources will help you harness the full potential of YOLOv5 for your computer vision projects. Let's get started!
|
||||
|
||||
</div>
|
||||
|
||||
## Tutorials
|
||||
|
||||
* [Train Custom Data](tutorials/train_custom_data.md) 🚀 RECOMMENDED
|
||||
* [Tips for Best Training Results](tutorials/tips_for_best_training_results.md) ☘️
|
||||
* [Multi-GPU Training](tutorials/multi_gpu_training.md)
|
||||
* [PyTorch Hub](tutorials/pytorch_hub_model_loading.md) 🌟 NEW
|
||||
* [TFLite, ONNX, CoreML, TensorRT Export](tutorials/model_export.md) 🚀
|
||||
* [NVIDIA Jetson platform Deployment](tutorials/running_on_jetson_nano.md) 🌟 NEW
|
||||
* [Test-Time Augmentation (TTA)](tutorials/test_time_augmentation.md)
|
||||
* [Model Ensembling](tutorials/model_ensembling.md)
|
||||
* [Model Pruning/Sparsity](tutorials/model_pruning_and_sparsity.md)
|
||||
* [Hyperparameter Evolution](tutorials/hyperparameter_evolution.md)
|
||||
* [Transfer Learning with Frozen Layers](tutorials/transfer_learning_with_frozen_layers.md)
|
||||
* [Architecture Summary](tutorials/architecture_description.md) 🌟 NEW
|
||||
* [Roboflow for Datasets, Labeling, and Active Learning](tutorials/roboflow_datasets_integration.md)
|
||||
* [ClearML Logging](tutorials/clearml_logging_integration.md) 🌟 NEW
|
||||
* [YOLOv5 with Neural Magic's Deepsparse](tutorials/neural_magic_pruning_quantization.md) 🌟 NEW
|
||||
* [Comet Logging](tutorials/comet_logging_integration.md) 🌟 NEW
|
||||
Here's a compilation of comprehensive tutorials that will guide you through different aspects of YOLOv5.
|
||||
|
||||
* [Train Custom Data](tutorials/train_custom_data.md) 🚀 RECOMMENDED: Learn how to train the YOLOv5 model on your custom dataset.
|
||||
* [Tips for Best Training Results](tutorials/tips_for_best_training_results.md) ☘️: Uncover practical tips to optimize your model training process.
|
||||
* [Multi-GPU Training](tutorials/multi_gpu_training.md): Understand how to leverage multiple GPUs to expedite your training.
|
||||
* [PyTorch Hub](tutorials/pytorch_hub_model_loading.md) 🌟 NEW: Learn to load pre-trained models via PyTorch Hub.
|
||||
* [TFLite, ONNX, CoreML, TensorRT Export](tutorials/model_export.md) 🚀: Understand how to export your model to different formats.
|
||||
* [NVIDIA Jetson platform Deployment](tutorials/running_on_jetson_nano.md) 🌟 NEW: Learn how to deploy your YOLOv5 model on NVIDIA Jetson platform.
|
||||
* [Test-Time Augmentation (TTA)](tutorials/test_time_augmentation.md): Explore how to use TTA to improve your model's prediction accuracy.
|
||||
* [Model Ensembling](tutorials/model_ensembling.md): Learn the strategy of combining multiple models for improved performance.
|
||||
* [Model Pruning/Sparsity](tutorials/model_pruning_and_sparsity.md): Understand pruning and sparsity concepts, and how to create a more efficient model.
|
||||
* [Hyperparameter Evolution](tutorials/hyperparameter_evolution.md): Discover the process of automated hyperparameter tuning for better model performance.
|
||||
* [Transfer Learning with Frozen Layers](tutorials/transfer_learning_with_frozen_layers.md): Learn how to implement transfer learning by freezing layers in YOLOv5.
|
||||
* [Architecture Summary](tutorials/architecture_description.md) 🌟 Delve into the structural details of the YOLOv5 model.
|
||||
* [Roboflow for Datasets](tutorials/roboflow_datasets_integration.md): Understand how to utilize Roboflow for dataset management, labeling, and active learning.
|
||||
* [ClearML Logging](tutorials/clearml_logging_integration.md) 🌟 Learn how to integrate ClearML for efficient logging during your model training.
|
||||
* [YOLOv5 with Neural Magic](tutorials/neural_magic_pruning_quantization.md) Discover how to use Neural Magic's Deepsparse to prune and quantize your YOLOv5 model.
|
||||
* [Comet Logging](tutorials/comet_logging_integration.md) 🌟 NEW: Explore how to utilize Comet for improved model training logging.
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies
|
||||
including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/)
|
||||
and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date, verified environments, with all dependencies (including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/), and [PyTorch](https://pytorch.org/)) pre-installed:
|
||||
|
||||
- **Notebooks** with free
|
||||
GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM.
|
||||
See [GCP Quickstart Guide](environments/google_cloud_quickstart_tutorial.md)
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](environments/google_cloud_quickstart_tutorial.md)
|
||||
- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](environments/aws_quickstart_tutorial.md)
|
||||
- **Docker Image**.
|
||||
See [Docker Quickstart Guide](environments/docker_image_quickstart_tutorial.md) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
- **Docker Image**. See [Docker Quickstart Guide](environments/docker_image_quickstart_tutorial.md) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
||||
|
||||
## Status
|
||||
|
||||
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
||||
|
||||
If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous
|
||||
Integration (CI) tests are currently passing. CI tests verify correct operation of
|
||||
YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py)
|
||||
and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24
|
||||
hours and on every commit.
|
||||
This badge signifies that all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify the correct operation of YOLOv5 [training](https://github.com/ultralytics/yolov5/blob/master/train.py), [validation](https://github.com/ultralytics/yolov5/blob/master/val.py), [inference](https://github.com/ultralytics/yolov5/blob/master/detect.py), [export](https://github.com/ultralytics/yolov5/blob/master/export.py) and [benchmarks](https://github.com/ultralytics/yolov5/blob/master/benchmarks.py) on macOS, Windows, and Ubuntu every 24 hours and with every new commit.
|
||||
|
||||
<br>
|
||||
<div align="center">
|
||||
@ -90,6 +85,6 @@ hours and on every commit.
|
||||
<a href="https://www.instagram.com/ultralytics/" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="" /></a>
|
||||
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%" alt="" />
|
||||
<a href="https://discord.gg/n6cFeSPZdD" style="text-decoration:none;">
|
||||
<a href="https://discord.gg/7aegy5d8" style="text-decoration:none;">
|
||||
<img src="https://github.com/ultralytics/assets/blob/main/social/logo-social-discord.png" width="3%" alt="" /></a>
|
||||
</div>
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to quickly start using YOLOv5 including installation, inference, and training on this Ultralytics Docs page.
|
||||
keywords: YOLOv5, object detection, PyTorch, quickstart, detect.py, training, Ultralytics Docs
|
||||
---
|
||||
|
||||
# YOLOv5 Quickstart
|
||||
|
||||
@ -1,27 +1,34 @@
|
||||
---
|
||||
comments: true
|
||||
description: 'Ultralytics YOLOv5 Docs: Learn model structure, data augmentation & training strategies. Build targets and the losses of object detection.'
|
||||
description: Explore the details of Ultralytics YOLOv5 architecture, a comprehensive guide to its model structure, data augmentation techniques, training strategies, and various features. Understand the intricacies of object detection algorithms and improve your skills in the machine learning field.
|
||||
keywords: yolov5 architecture, data augmentation, training strategies, object detection, yolo docs, ultralytics
|
||||
---
|
||||
|
||||
# Ultralytics YOLOv5 Architecture
|
||||
|
||||
YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, data augmentation strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and image recognition.
|
||||
|
||||
## 1. Model Structure
|
||||
|
||||
YOLOv5 (v6.0/6.1) consists of:
|
||||
YOLOv5's architecture consists of three main parts:
|
||||
|
||||
- **Backbone**: `New CSP-Darknet53`
|
||||
- **Neck**: `SPPF`, `New CSP-PAN`
|
||||
- **Head**: `YOLOv3 Head`
|
||||
- **Backbone**: This is the main body of the network. For YOLOv5, the backbone is designed using the `New CSP-Darknet53` structure, a modification of the Darknet architecture used in previous versions.
|
||||
- **Neck**: This part connects the backbone and the head. In YOLOv5, `SPPF` and `New CSP-PAN` structures are utilized.
|
||||
- **Head**: This part is responsible for generating the final output. YOLOv5 uses the `YOLOv3 Head` for this purpose.
|
||||
|
||||
Model structure (`yolov5l.yaml`):
|
||||
The structure of the model is depicted in the image below. The model structure details can be found in `yolov5l.yaml`.
|
||||
|
||||
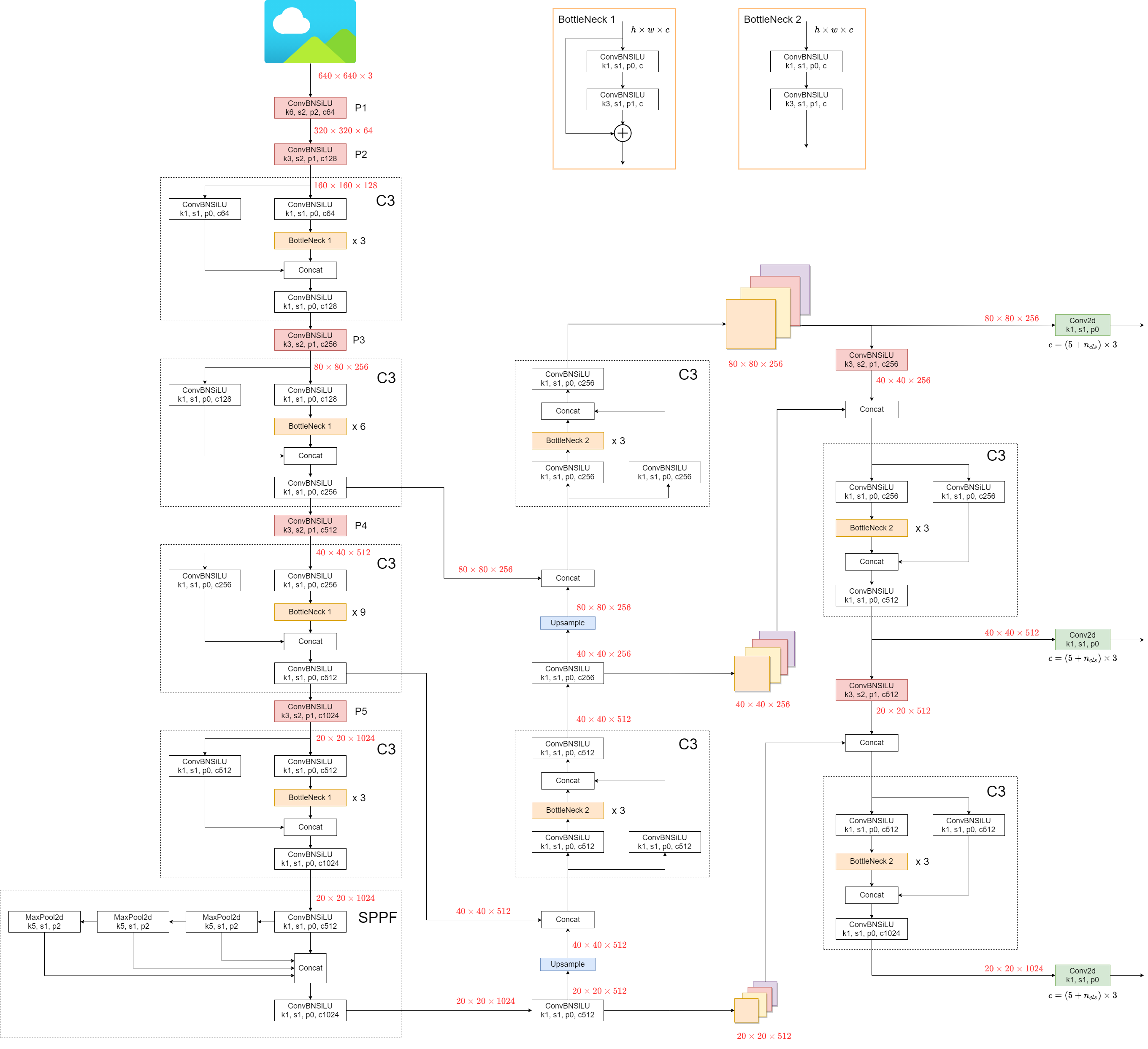
|
||||
|
||||
Some minor changes compared to previous versions:
|
||||
YOLOv5 introduces some minor changes compared to its predecessors:
|
||||
|
||||
1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)
|
||||
2. Replace the `SPP` structure with `SPPF`(more than double the speed)
|
||||
1. The `Focus` structure, found in earlier versions, is replaced with a `6x6 Conv2d` structure. This change boosts efficiency [#4825](https://github.com/ultralytics/yolov5/issues/4825).
|
||||
2. The `SPP` structure is replaced with `SPPF`. This alteration more than doubles the speed of processing.
|
||||
|
||||
To test the speed of `SPP` and `SPPF`, the following code can be used:
|
||||
|
||||
<details markdown>
|
||||
<summary>test code</summary>
|
||||
<summary>SPP vs SPPF speed profiling example (click to open)</summary>
|
||||
|
||||
```python
|
||||
import time
|
||||
@ -67,12 +74,12 @@ def main():
|
||||
t_start = time.time()
|
||||
for _ in range(100):
|
||||
spp(input_tensor)
|
||||
print(f"spp time: {time.time() - t_start}")
|
||||
print(f"SPP time: {time.time() - t_start}")
|
||||
|
||||
t_start = time.time()
|
||||
for _ in range(100):
|
||||
sppf(input_tensor)
|
||||
print(f"sppf time: {time.time() - t_start}")
|
||||
print(f"SPPF time: {time.time() - t_start}")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
@ -83,63 +90,75 @@ result:
|
||||
|
||||
```
|
||||
True
|
||||
spp time: 0.5373051166534424
|
||||
sppf time: 0.20780706405639648
|
||||
SPP time: 0.5373051166534424
|
||||
SPPF time: 0.20780706405639648
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## 2. Data Augmentation
|
||||
## 2. Data Augmentation Techniques
|
||||
|
||||
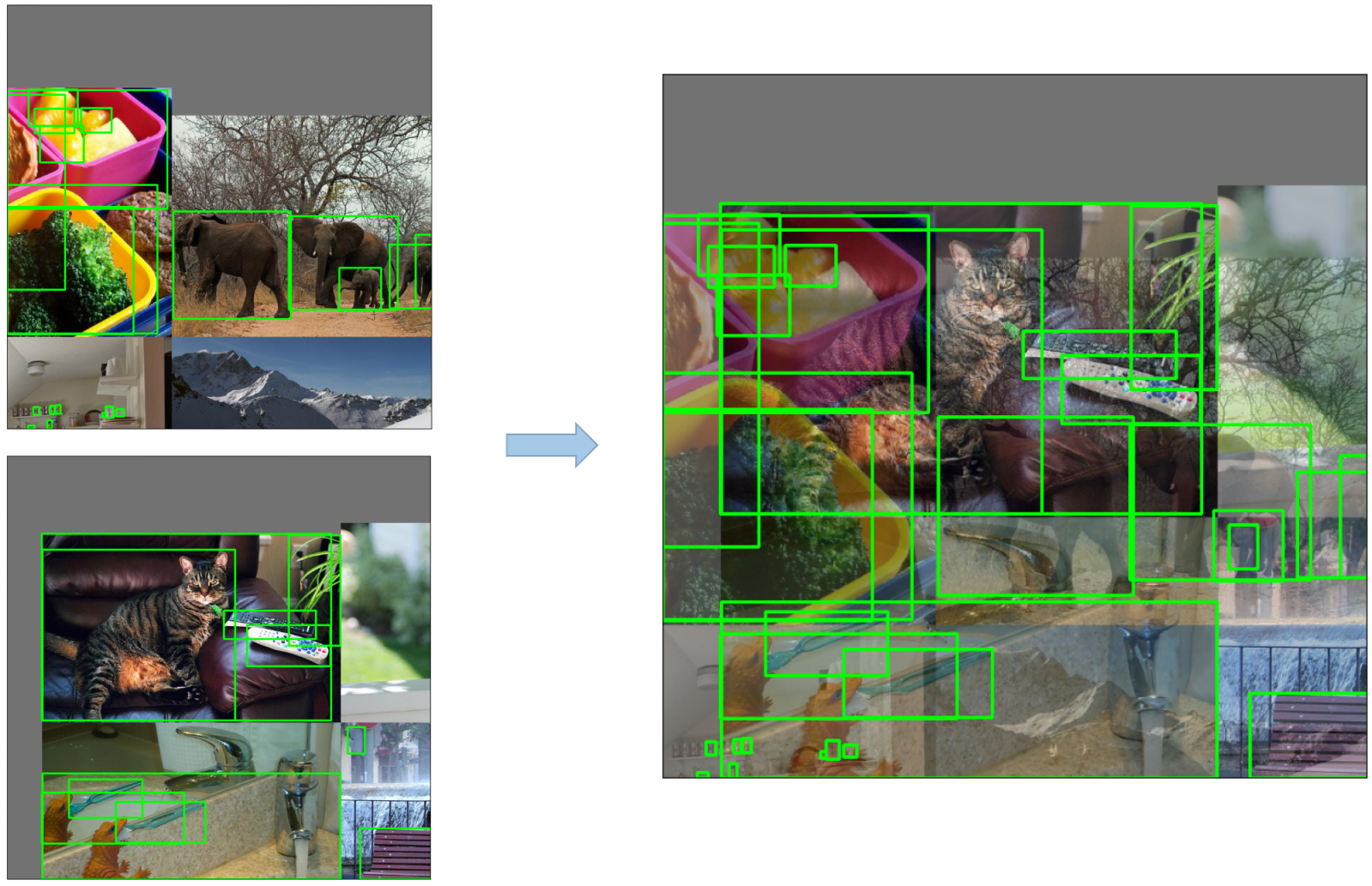
- Mosaic
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109235-c7aad8f2-1d4f-41f9-8d5f-b2fde6f2885e.png#pic_center" width=80%>
|
||||
YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce overfitting. These techniques include:
|
||||
|
||||
- Copy paste
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159116277-91b45033-6bec-4f82-afc4-41138866628e.png#pic_center" width=80%>
|
||||
- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage object detection models to better handle various object scales and translations.
|
||||
|
||||
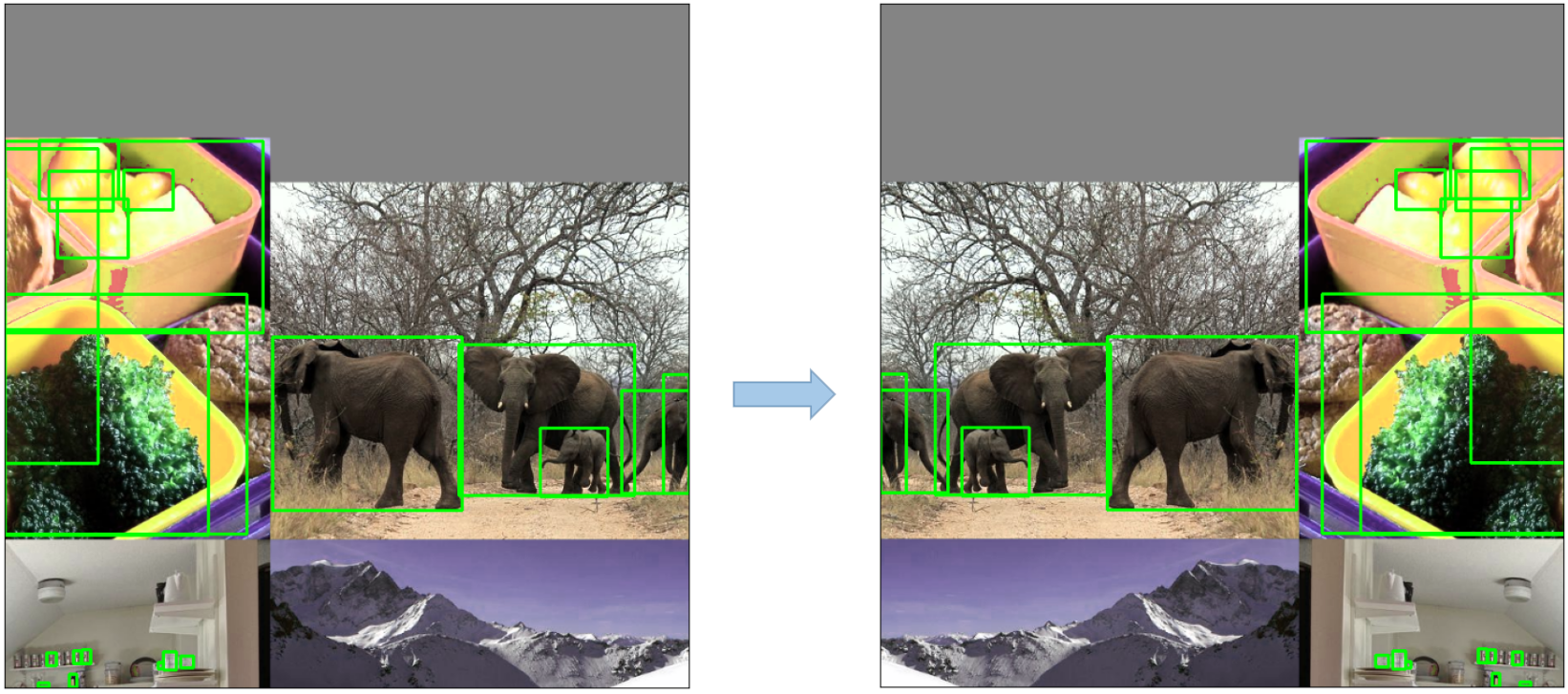
- Random affine(Rotation, Scale, Translation and Shear)
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109326-45cd5acb-14fa-43e7-9235-0f21b0021c7d.png#pic_center" width=80%>
|
||||

|
||||
|
||||
- MixUp
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109361-3b24333b-f481-478b-ae00-df7838f0b5cd.png#pic_center" width=80%>
|
||||
- **Copy-Paste Augmentation**: An innovative data augmentation method that copies random patches from an image and pastes them onto another randomly chosen image, effectively generating a new training sample.
|
||||
|
||||
- Albumentations
|
||||
- Augment HSV(Hue, Saturation, Value)
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109407-83d100ba-1aba-4f4b-aa03-4f048f815981.png#pic_center" width=80%>
|
||||

|
||||
|
||||
- Random horizontal flip
|
||||
<img src="https://user-images.githubusercontent.com/31005897/159109429-0d44619a-a76a-49eb-bfc0-6709860c043e.png#pic_center" width=80%>
|
||||
- **Random Affine Transformations**: This includes random rotation, scaling, translation, and shearing of the images.
|
||||
|
||||

|
||||
|
||||
- **MixUp Augmentation**: A method that creates composite images by taking a linear combination of two images and their associated labels.
|
||||
|
||||
|
||||
|
||||
- **Albumentations**: A powerful library for image augmenting that supports a wide variety of augmentation techniques.
|
||||
- **HSV Augmentation**: Random changes to the Hue, Saturation, and Value of the images.
|
||||
|
||||

|
||||
|
||||
- **Random Horizontal Flip**: An augmentation method that randomly flips images horizontally.
|
||||
|
||||
|
||||
|
||||
## 3. Training Strategies
|
||||
|
||||
- Multi-scale training(0.5~1.5x)
|
||||
- AutoAnchor(For training custom data)
|
||||
- Warmup and Cosine LR scheduler
|
||||
- EMA(Exponential Moving Average)
|
||||
- Mixed precision
|
||||
- Evolve hyper-parameters
|
||||
YOLOv5 applies several sophisticated training strategies to enhance the model's performance. They include:
|
||||
|
||||
## 4. Others
|
||||
- **Multiscale Training**: The input images are randomly rescaled within a range of 0.5 to 1.5 times their original size during the training process.
|
||||
- **AutoAnchor**: This strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes in your custom data.
|
||||
- **Warmup and Cosine LR Scheduler**: A method to adjust the learning rate to enhance model performance.
|
||||
- **Exponential Moving Average (EMA)**: A strategy that uses the average of parameters over past steps to stabilize the training process and reduce generalization error.
|
||||
- **Mixed Precision Training**: A method to perform operations in half-precision format, reducing memory usage and enhancing computational speed.
|
||||
- **Hyperparameter Evolution**: A strategy to automatically tune hyperparameters to achieve optimal performance.
|
||||
|
||||
## 4. Additional Features
|
||||
|
||||
### 4.1 Compute Losses
|
||||
|
||||
The YOLOv5 loss consists of three parts:
|
||||
The loss in YOLOv5 is computed as a combination of three individual loss components:
|
||||
|
||||
- Classes loss(BCE loss)
|
||||
- Objectness loss(BCE loss)
|
||||
- Location loss(CIoU loss)
|
||||
- **Classes Loss (BCE Loss)**: Binary Cross-Entropy loss, measures the error for the classification task.
|
||||
- **Objectness Loss (BCE Loss)**: Another Binary Cross-Entropy loss, calculates the error in detecting whether an object is present in a particular grid cell or not.
|
||||
- **Location Loss (CIoU Loss)**: Complete IoU loss, measures the error in localizing the object within the grid cell.
|
||||
|
||||
The overall loss function is depicted by:
|
||||
|
||||

|
||||
|
||||
### 4.2 Balance Losses
|
||||
|
||||
The objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.
|
||||
The objectness losses of the three prediction layers (`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively. This approach ensures that the predictions at different scales contribute appropriately to the total loss.
|
||||
|
||||

|
||||
|
||||
### 4.3 Eliminate Grid Sensitivity
|
||||
|
||||
In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:
|
||||
The YOLOv5 architecture makes some important changes to the box prediction strategy compared to earlier versions of YOLO. In YOLOv2 and YOLOv3, the box coordinates were directly predicted using the activation of the last layer.
|
||||
|
||||
+c_x)
|
||||
+c_y)
|
||||
@ -148,9 +167,9 @@ In YOLOv2 and YOLOv3, the formula for calculating the predicted target informati
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508027-8bf63c28-8290-467b-8a3e-4ad09235001a.png#pic_center" width=40%>
|
||||
|
||||
However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
|
||||
|
||||
|
||||
In YOLOv5, the formula is:
|
||||
The revised formulas for calculating the predicted bounding box are as follows:
|
||||
|
||||
-0.5)+c_x)
|
||||
-0.5)+c_y)
|
||||
@ -168,9 +187,11 @@ Compare the height and width scaling ratio(relative to anchor) before and after
|
||||
|
||||
### 4.4 Build Targets
|
||||
|
||||
Match positive samples:
|
||||
The build target process in YOLOv5 is critical for training efficiency and model accuracy. It involves assigning ground truth boxes to the appropriate grid cells in the output map and matching them with the appropriate anchor boxes.
|
||||
|
||||
- Calculate the aspect ratio of GT and Anchor Templates
|
||||
This process follows these steps:
|
||||
|
||||
- Calculate the ratio of the ground truth box dimensions and the dimensions of each anchor template.
|
||||
|
||||

|
||||
|
||||
@ -186,10 +207,18 @@ Match positive samples:
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508119-fbb2e483-7b8c-4975-8e1f-f510d367f8ff.png#pic_center" width=70%>
|
||||
|
||||
- Assign the successfully matched Anchor Templates to the corresponding cells
|
||||
- If the calculated ratio is within the threshold, match the ground truth box with the corresponding anchor.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508771-b6e7cab4-8de6-47f9-9abf-cdf14c275dfe.png#pic_center" width=70%>
|
||||
|
||||
- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
|
||||
- Assign the matched anchor to the appropriate cells, keeping in mind that due to the revised center point offset, a ground truth box can be assigned to more than one anchor. Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70%>
|
||||
<img src="https://user-images.githubusercontent.com/31005897/158508139-9db4e8c2-cf96-47e0-bc80-35d11512f296.png#pic_center" width=70%>
|
||||
|
||||
This way, the build targets process ensures that each ground truth object is properly assigned and matched during the training process, allowing YOLOv5 to learn the task of object detection more effectively.
|
||||
|
||||
## Conclusion
|
||||
|
||||
In conclusion, YOLOv5 represents a significant step forward in the development of real-time object detection models. By incorporating various new features, enhancements, and training strategies, it surpasses previous versions of the YOLO family in performance and efficiency.
|
||||
|
||||
The primary enhancements in YOLOv5 include the use of a dynamic architecture, an extensive range of data augmentation techniques, innovative training strategies, as well as important adjustments in computing losses and the process of building targets. All these innovations significantly improve the accuracy and efficiency of object detection while retaining a high degree of speed, which is the trademark of YOLO models.
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Integrate ClearML with YOLOv5 to track experiments and manage data versions. Optimize hyperparameters and remotely monitor your runs.
|
||||
keywords: YOLOv5, ClearML, experiment manager, remotely train, monitor, hyperparameter optimization, data versioning tool, HPO, data version management, optimization locally, agent, training progress, custom YOLOv5, AI development, model building
|
||||
---
|
||||
|
||||
# ClearML Integration
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to use YOLOv5 with Comet, a tool for logging and visualizing machine learning model metrics in real-time. Install, log and analyze seamlessly.
|
||||
keywords: object detection, YOLOv5, Comet, model metrics, deep learning, image classification, Colab notebook, machine learning, datasets, hyperparameters tracking, training script, checkpoint
|
||||
---
|
||||
|
||||
<img src="https://cdn.comet.ml/img/notebook_logo.png">
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn to find optimum YOLOv5 hyperparameters via **evolution**. A guide to learn hyperparameter tuning with Genetic Algorithms.
|
||||
keywords: YOLOv5, Hyperparameter Evolution, Genetic Algorithm, Hyperparameter Optimization, Fitness, Evolve, Visualize
|
||||
---
|
||||
|
||||
📚 This guide explains **hyperparameter evolution** for YOLOv5 🚀. Hyperparameter evolution is a method of [Hyperparameter Optimization](https://en.wikipedia.org/wiki/Hyperparameter_optimization) using a [Genetic Algorithm](https://en.wikipedia.org/wiki/Genetic_algorithm) (GA) for optimization. UPDATED 25 September 2022.
|
||||
@ -151,7 +152,7 @@ We recommend a minimum of 300 generations of evolution for best results. Note th
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to ensemble YOLOv5 models for improved mAP and Recall! Clone the repo, install requirements, and start testing and inference.
|
||||
keywords: YOLOv5, object detection, ensemble learning, mAP, Recall
|
||||
---
|
||||
|
||||
📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
|
||||
@ -132,7 +133,7 @@ Done. (0.223s)
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Export YOLOv5 models to TFLite, ONNX, CoreML, and TensorRT formats. Achieve up to 5x GPU speedup using TensorRT. Benchmarks included.
|
||||
keywords: YOLOv5, object detection, export, ONNX, CoreML, TensorFlow, TensorRT, OpenVINO
|
||||
---
|
||||
|
||||
# TFLite, ONNX, CoreML, TensorRT Export
|
||||
@ -231,7 +232,7 @@ YOLOv5 OpenVINO C++ inference examples:
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to apply pruning to your YOLOv5 models. See the before and after performance with an explanation of sparsity and more.
|
||||
keywords: YOLOv5, ultralytics, pruning, deep learning, computer vision, object detection, AI, tutorial
|
||||
---
|
||||
|
||||
📚 This guide explains how to apply **pruning** to YOLOv5 🚀 models.
|
||||
@ -95,7 +96,7 @@ In the results we can observe that we have achieved a **sparsity of 30%** in our
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to train your dataset on single or multiple machines using YOLOv5 on multiple GPUs. Use simple commands with DDP mode for faster performance.
|
||||
keywords: ultralytics, yolo, yolov5, multi-gpu, training, dataset, dataloader, data parallel, distributed data parallel, docker, pytorch
|
||||
---
|
||||
|
||||
📚 This guide explains how to properly use **multiple** GPUs to train a dataset with YOLOv5 🚀 on single or multiple machine(s).
|
||||
@ -172,7 +173,7 @@ If you went through all the above, feel free to raise an Issue by giving as much
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to deploy YOLOv5 with DeepSparse to achieve exceptional CPU performance close to GPUs, using pruning, and quantization.<br>
|
||||
keywords: YOLOv5, DeepSparse, Neural Magic, CPU, Production, Performance, Deployments, APIs, SparseZoo, Ultralytics, Model Sparsity, Inference, Open-source, ONNX, Server
|
||||
---
|
||||
|
||||
<!--
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to load YOLOv5🚀 from PyTorch Hub at https://pytorch.org/hub/ultralytics_yolov5 and perform image inference. UPDATED 26 March 2023.
|
||||
keywords: YOLOv5, PyTorch Hub, object detection, computer vision, machine learning, artificial intelligence
|
||||
---
|
||||
|
||||
📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5).
|
||||
@ -316,7 +317,7 @@ model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5s.pt') # PyT
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Use Roboflow to organize, label, prepare, version & host datasets for training YOLOv5 models. Upload via UI, API, or Python, making versions with custom preprocessing and offline augmentation. Export in YOLOv5 format and access custom training tutorials. Use active learning to improve model deployments.
|
||||
keywords: YOLOv5, Roboflow, Dataset, Labeling, Versioning, Darknet, Export, Python, Upload, Active Learning, Preprocessing
|
||||
---
|
||||
|
||||
# Roboflow Datasets
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Deploy YOLOv5 on NVIDIA Jetson using TensorRT and DeepStream SDK for high performance inference. Step-by-step guide with code snippets.
|
||||
keywords: YOLOv5, NVIDIA Jetson, TensorRT, DeepStream SDK, deployment, AI at edge, PyTorch, computer vision, object detection, CUDA
|
||||
---
|
||||
|
||||
# Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to use Test Time Augmentation (TTA) with YOLOv5 to improve mAP and Recall during testing and inference. Code examples included.
|
||||
keywords: YOLOv5, test time augmentation, TTA, mAP, recall, object detection, deep learning, computer vision, PyTorch
|
||||
---
|
||||
|
||||
# Test-Time Augmentation (TTA)
|
||||
@ -150,7 +151,7 @@ You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Get the most out of YOLOv5 with this guide; producing best results, checking dataset, hypertuning & more. Updated May 2022.
|
||||
keywords: YOLOv5 training guide, mAP, best results, dataset, model selection, training settings, hyperparameters, Ultralytics Docs
|
||||
---
|
||||
|
||||
📚 This guide explains how to produce the best mAP and training results with YOLOv5 🚀.
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Train your custom dataset with YOLOv5. Learn to collect, label and annotate images, and train and deploy models. Get started now.
|
||||
keywords: YOLOv5, train custom dataset, object detection, artificial intelligence, deep learning, computer vision
|
||||
---
|
||||
|
||||
📚 This guide explains how to train your own **custom dataset** with [YOLOv5](https://github.com/ultralytics/yolov5) 🚀.
|
||||
@ -222,7 +223,7 @@ Once your model is trained you can use your best checkpoint `best.pt` to:
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
comments: true
|
||||
description: Learn how to freeze YOLOv5 when transfer learning. Retrain a pre-trained model on new data faster and with fewer resources.
|
||||
keywords: Freeze YOLOv5, Transfer Learning YOLOv5, Freeze Layers, Reduce Resources, Speed up Training, Increase Accuracy
|
||||
---
|
||||
|
||||
📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
|
||||
@ -140,7 +141,7 @@ Interestingly, the more modules are frozen the less GPU memory is required to tr
|
||||
|
||||
## Environments
|
||||
|
||||
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
YOLOv5 is designed to be run in the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
|
||||
|
||||
- **Notebooks** with free GPU: <a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a> <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
||||
- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
|
||||
|
||||
Reference in New Issue
Block a user