8.6 KiB
1. Model Structure
YOLOv5 (v6.0/6.1) consists of:
- Backbone:
New CSP-Darknet53 - Neck:
SPPF,New CSP-PAN - Head:
YOLOv3 Head
Model structure (yolov5l.yaml):
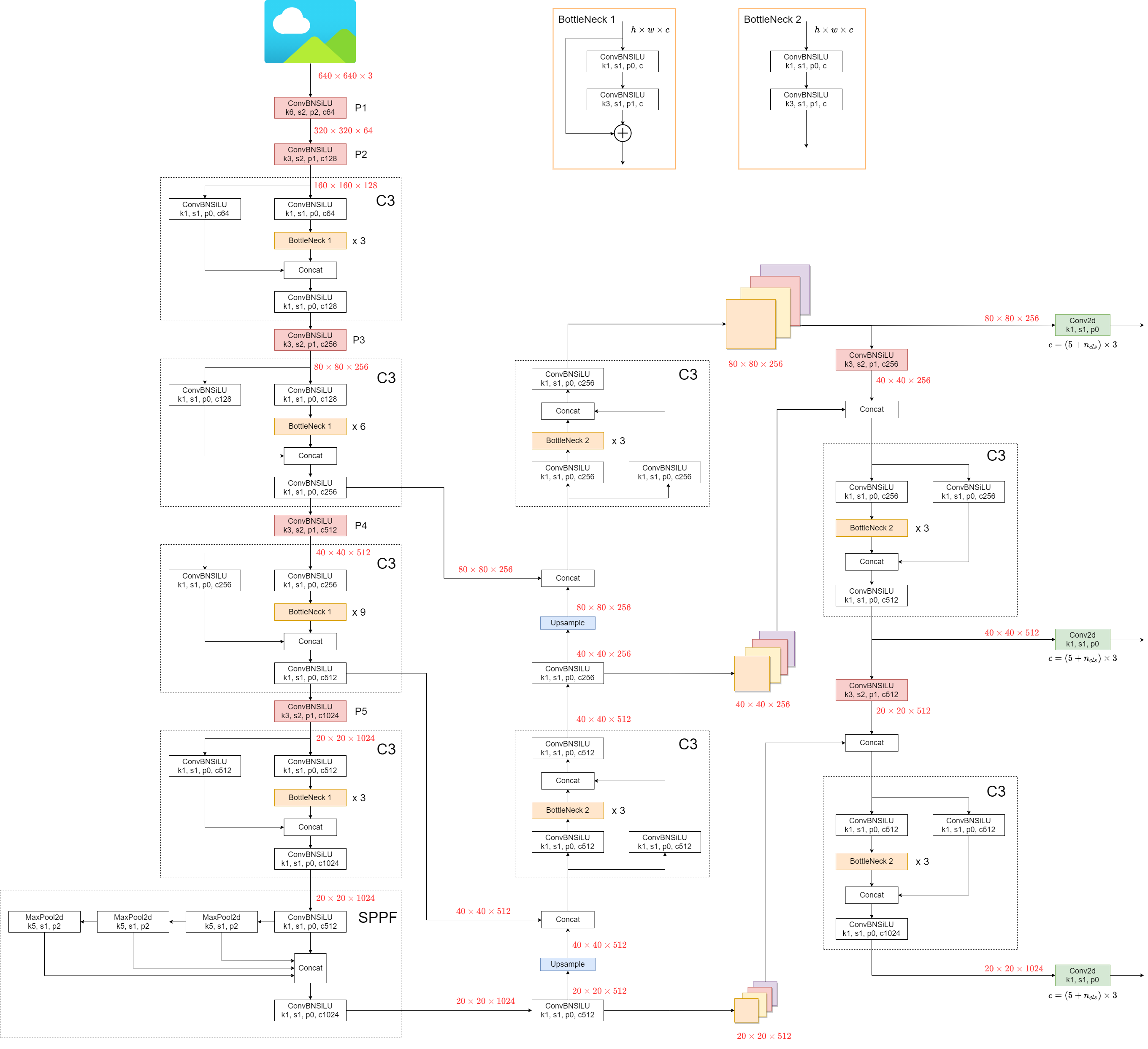
Some minor changes compared to previous versions:
- Replace the
Focusstructure with6x6 Conv2d(more efficient, refer #4825) - Replace the
SPPstructure withSPPF(more than double the speed)
test code
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
result:
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648
2. Data Augmentation
-
Mosaic

-
Copy paste

-
Random affine(Rotation, Scale, Translation and Shear)

-
MixUp

-
Albumentations
-
Augment HSV(Hue, Saturation, Value)

-
Random horizontal flip

3. Training Strategies
- Multi-scale training(0.5~1.5x)
- AutoAnchor(For training custom data)
- Warmup and Cosine LR scheduler
- EMA(Exponential Moving Average)
- Mixed precision
- Evolve hyper-parameters
4. Others
4.1 Compute Losses
The YOLOv5 loss consists of three parts:
- Classes loss(BCE loss)
- Objectness loss(BCE loss)
- Location loss(CIoU loss)
4.2 Balance Losses
The objectness losses of the three prediction layers(P3, P4, P5) are weighted differently. The balance weights are [4.0, 1.0, 0.4] respectively.
4.3 Eliminate Grid Sensitivity
In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:

In YOLOv5, the formula is:
Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5). Therefore, offset can easily get 0 or 1.

Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. refer this issue

4.4 Build Targets
Match positive samples:
- Calculate the aspect ratio of GT and Anchor Templates

- Assign the successfully matched Anchor Templates to the corresponding cells

- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.

Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:



- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide

Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on macOS, Windows, and Ubuntu every 24 hours and on every commit.