+
 -
-
- ![]() -
- ![]() -
- 
- ![]() -
- ![]() -
-  -
-
+
+ +
 diff --git a/docs/modes/predict.md b/docs/modes/predict.md
index ffc8722..f9dc793 100644
--- a/docs/modes/predict.md
+++ b/docs/modes/predict.md
@@ -1,63 +1,66 @@
-Inference or prediction of a task returns a list of `Results` objects. Alternatively, in the streaming mode, it returns
-a generator of `Results` objects which is memory efficient. Streaming mode can be enabled by passing `stream=True` in
-predictor's call method.
+YOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a
+memory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by
+passing `stream=True` in the predictor's call method.
!!! example "Predict"
- === "Return a List"
+ === "Return a list with `Stream=False`"
+ ```python
+ inputs = [img, img] # list of numpy arrays
+ results = model(inputs) # list of Results objects
+
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
- ```python
- inputs = [img, img] # list of np arrays
- results = model(inputs) # List of Results objects
-
- for result in results:
- boxes = result.boxes # Boxes object for bbox outputs
- masks = result.masks # Masks object for segmenation masks outputs
- probs = result.probs # Class probabilities for classification outputs
- ```
-
- === "Return a Generator"
+ === "Return a list with `Stream=True`"
+ ```python
+ inputs = [img, img] # list of numpy arrays
+ results = model(inputs, stream=True) # generator of Results objects
+
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
- ```python
- inputs = [img, img] # list of numpy arrays
- results = model(inputs, stream=True) # generator of Results objects
-
- for r in results:
- boxes = r.boxes # Boxes object for bbox outputs
- masks = r.masks # Masks object for segmenation masks outputs
- probs = r.probs # Class probabilities for classification outputs
- ```
+!!! tip "Tip"
+
+ Streaming mode with `stream=True` should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors.
## Sources
-YOLOv8 can run inference on a variety of sources. The table below lists the various sources that can be used as input
-for YOLOv8, along with the required format and notes. Sources include images, URLs, PIL images, OpenCV, numpy arrays,
-torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table also indicates whether each
-source can be used as a stream and the model argument required for that source.
+YOLOv8 can accept various input sources, as shown in the table below. This includes images, URLs, PIL images, OpenCV,
+numpy arrays, torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table indicates
+whether each source can be used in streaming mode with `stream=True` ✅ and an example argument for each source.
-| source | stream | model(arg) | type | notes |
-|------------|---------|--------------------------------------------|----------------|------------------|
-| image | | `'im.jpg'` | `str`, `Path` | |
-| URL | | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
-| screenshot | | `'screen'` | `str` | |
-| PIL | | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
-| OpenCV | | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
-| numpy | | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
-| torch | | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
-| CSV | | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
-| video | ✓ | `'vid.mp4'` | `str`, `Path` | |
-| directory | ✓ | `'path/'` | `str`, `Path` | |
-| glob | ✓ | `'path/*.jpg'` | `str` | Use `*` operator |
-| YouTube | ✓ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
-| stream | ✓ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
+| source | model(arg) | type | notes |
+|-------------|--------------------------------------------|----------------|------------------|
+| image | `'im.jpg'` | `str`, `Path` | |
+| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
+| screenshot | `'screen'` | `str` | |
+| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
+| OpenCV | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
+| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
+| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
+| CSV | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
+| video ✅ | `'vid.mp4'` | `str`, `Path` | |
+| directory ✅ | `'path/'` | `str`, `Path` | |
+| glob ✅ | `'path/*.jpg'` | `str` | Use `*` operator |
+| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
+| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
-## Image Formats
+## Image and Video Formats
-For images, YOLOv8 supports a variety of image formats defined
-in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
-following suffixes are valid for images:
+YOLOv8 supports various image and video formats, as specified
+in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the
+tables below for the valid suffixes and example predict commands.
+
+### Image Suffixes
| Image Suffixes | Example Predict Command | Reference |
|----------------|----------------------------------|-------------------------------------------------------------------------------|
@@ -72,11 +75,7 @@ following suffixes are valid for images:
| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
-## Video Formats
-
-For videos, YOLOv8 also supports a variety of video formats defined
-in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
-following suffixes are valid for videos:
+### Video Suffixes
| Video Suffixes | Example Predict Command | Reference |
|----------------|----------------------------------|----------------------------------------------------------------------------------|
@@ -95,68 +94,78 @@ following suffixes are valid for videos:
## Working with Results
-Results object consists of these component objects:
+The `Results` object contains the following components:
-- `Results.boxes`: `Boxes` object with properties and methods for manipulating bboxes
-- `Results.masks`: `Masks` object used to index masks or to get segment coordinates.
-- `Results.probs`: `torch.Tensor` containing the class probabilities/logits.
-- `Results.orig_img`: Original image loaded in memory.
-- `Results.path`: `Path` containing the path to input image
+- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes
+- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates
+- `Results.probs`: `torch.Tensor` containing class probabilities or logits
+- `Results.orig_img`: Original image loaded in memory
+- `Results.path`: `Path` containing the path to the input image
-Each result is composed of torch.Tensor by default, in which you can easily use following functionality:
+Each result is composed of a `torch.Tensor` by default, which allows for easy manipulation:
-```python
-results = results.cuda()
-results = results.cpu()
-results = results.to("cpu")
-results = results.numpy()
-```
+!!! example "Results"
+
+ ```python
+ results = results.cuda()
+ results = results.cpu()
+ results = results.to('cpu')
+ results = results.numpy()
+ ```
### Boxes
-`Boxes` object can be used index, manipulate and convert bboxes to different formats. The box format conversion
-operations are cached, which means they're only calculated once per object and those values are reused for future calls.
+`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion
+operations are cached, meaning they're only calculated once per object, and those values are reused for future calls.
-- Indexing a `Boxes` objects returns a `Boxes` object
+- Indexing a `Boxes` object returns a `Boxes` object:
-```python
-results = model(inputs)
-boxes = results[0].boxes
-box = boxes[0] # returns one box
-box.xyxy
-```
+!!! example "Boxes"
+
+ ```python
+ results = model(img)
+ boxes = results[0].boxes
+ box = boxes[0] # returns one box
+ box.xyxy
+ ```
- Properties and conversions
-```python
-boxes.xyxy # box with xyxy format, (N, 4)
-boxes.xywh # box with xywh format, (N, 4)
-boxes.xyxyn # box with xyxy format but normalized, (N, 4)
-boxes.xywhn # box with xywh format but normalized, (N, 4)
-boxes.conf # confidence score, (N, 1)
-boxes.cls # cls, (N, 1)
-boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .
-```
+!!! example "Boxes Properties"
+
+ ```python
+ boxes.xyxy # box with xyxy format, (N, 4)
+ boxes.xywh # box with xywh format, (N, 4)
+ boxes.xyxyn # box with xyxy format but normalized, (N, 4)
+ boxes.xywhn # box with xywh format but normalized, (N, 4)
+ boxes.conf # confidence score, (N, 1)
+ boxes.cls # cls, (N, 1)
+ boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes
+ ```
### Masks
`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
-```python
-results = model(inputs)
-masks = results[0].masks # Masks object
-masks.segments # bounding coordinates of masks, List[segment] * N
-masks.data # raw masks tensor, (N, H, W) or masks.masks
-```
+!!! example "Masks"
+
+ ```python
+ results = model(inputs)
+ masks = results[0].masks # Masks object
+ masks.segments # bounding coordinates of masks, List[segment] * N
+ masks.data # raw masks tensor, (N, H, W) or masks.masks
+ ```
### probs
`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.
-```python
-results = model(inputs)
-results[0].probs # cls prob, (num_class, )
-```
+!!! example "Probs"
+
+ ```python
+ results = model(inputs)
+ results[0].probs # cls prob, (num_class, )
+ ```
Class reference documentation for `Results` module and its components can be found [here](../reference/results.md)
@@ -165,16 +174,14 @@ Class reference documentation for `Results` module and its components can be fou
You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
masks, classification logits, etc.) found in the results object
-```python
-res = model(img)
-res_plotted = res[0].plot()
-cv2.imshow("result", res_plotted)
-```
+!!! example "Plotting"
-!!! example "`plot()` arguments"
+ ```python
+ res = model(img)
+ res_plotted = res[0].plot()
+ cv2.imshow("result", res_plotted)
+ ```
- `show_conf (bool)`: Show confidence
-
- `line_width (Float)`: The line width of boxes. Automatically scaled to img size if not provided
-
- `font_size (Float)`: The font size of . Automatically scaled to img size if not provided
+- `show_conf (bool)`: Show confidence
+- `line_width (Float)`: The line width of boxes. Automatically scaled to img size if not provided
+- `font_size (Float)`: The font size of . Automatically scaled to img size if not provided
diff --git a/docs/quickstart.md b/docs/quickstart.md
index 3eb4443..8725b77 100644
--- a/docs/quickstart.md
+++ b/docs/quickstart.md
@@ -4,70 +4,130 @@ Install YOLOv8 via the `ultralytics` pip package for the latest stable release o
the [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most
up-to-date version.
-!!! example "Pip install method (recommended)"
+!!! example "Install"
- ```bash
- pip install ultralytics
- ```
+ === "pip install (recommended)"
+ ```bash
+ pip install ultralytics
+ ```
-!!! example "Git clone method (for development)"
+ === "git clone (for development)"
+ ```bash
+ git clone https://github.com/ultralytics/ultralytics
+ cd ultralytics
+ pip install -e .
+ ```
+
+See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that `pip` automatically installs all required dependencies.
+
+!!! tip "Tip"
+
+ PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
+
+
+
diff --git a/docs/modes/predict.md b/docs/modes/predict.md
index ffc8722..f9dc793 100644
--- a/docs/modes/predict.md
+++ b/docs/modes/predict.md
@@ -1,63 +1,66 @@
-Inference or prediction of a task returns a list of `Results` objects. Alternatively, in the streaming mode, it returns
-a generator of `Results` objects which is memory efficient. Streaming mode can be enabled by passing `stream=True` in
-predictor's call method.
+YOLOv8 **predict mode** can generate predictions for various tasks, returning either a list of `Results` objects or a
+memory-efficient generator of `Results` objects when using the streaming mode. Enable streaming mode by
+passing `stream=True` in the predictor's call method.
!!! example "Predict"
- === "Return a List"
+ === "Return a list with `Stream=False`"
+ ```python
+ inputs = [img, img] # list of numpy arrays
+ results = model(inputs) # list of Results objects
+
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
- ```python
- inputs = [img, img] # list of np arrays
- results = model(inputs) # List of Results objects
-
- for result in results:
- boxes = result.boxes # Boxes object for bbox outputs
- masks = result.masks # Masks object for segmenation masks outputs
- probs = result.probs # Class probabilities for classification outputs
- ```
-
- === "Return a Generator"
+ === "Return a list with `Stream=True`"
+ ```python
+ inputs = [img, img] # list of numpy arrays
+ results = model(inputs, stream=True) # generator of Results objects
+
+ for result in results:
+ boxes = result.boxes # Boxes object for bbox outputs
+ masks = result.masks # Masks object for segmentation masks outputs
+ probs = result.probs # Class probabilities for classification outputs
+ ```
- ```python
- inputs = [img, img] # list of numpy arrays
- results = model(inputs, stream=True) # generator of Results objects
-
- for r in results:
- boxes = r.boxes # Boxes object for bbox outputs
- masks = r.masks # Masks object for segmenation masks outputs
- probs = r.probs # Class probabilities for classification outputs
- ```
+!!! tip "Tip"
+
+ Streaming mode with `stream=True` should be used for long videos or large predict sources, otherwise results will accumuate in memory and will eventually cause out-of-memory errors.
## Sources
-YOLOv8 can run inference on a variety of sources. The table below lists the various sources that can be used as input
-for YOLOv8, along with the required format and notes. Sources include images, URLs, PIL images, OpenCV, numpy arrays,
-torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table also indicates whether each
-source can be used as a stream and the model argument required for that source.
+YOLOv8 can accept various input sources, as shown in the table below. This includes images, URLs, PIL images, OpenCV,
+numpy arrays, torch tensors, CSV files, videos, directories, globs, YouTube videos, and streams. The table indicates
+whether each source can be used in streaming mode with `stream=True` ✅ and an example argument for each source.
-| source | stream | model(arg) | type | notes |
-|------------|---------|--------------------------------------------|----------------|------------------|
-| image | | `'im.jpg'` | `str`, `Path` | |
-| URL | | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
-| screenshot | | `'screen'` | `str` | |
-| PIL | | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
-| OpenCV | | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
-| numpy | | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
-| torch | | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
-| CSV | | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
-| video | ✓ | `'vid.mp4'` | `str`, `Path` | |
-| directory | ✓ | `'path/'` | `str`, `Path` | |
-| glob | ✓ | `'path/*.jpg'` | `str` | Use `*` operator |
-| YouTube | ✓ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
-| stream | ✓ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
+| source | model(arg) | type | notes |
+|-------------|--------------------------------------------|----------------|------------------|
+| image | `'im.jpg'` | `str`, `Path` | |
+| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | |
+| screenshot | `'screen'` | `str` | |
+| PIL | `Image.open('im.jpg')` | `PIL.Image` | HWC, RGB |
+| OpenCV | `cv2.imread('im.jpg')[:,:,::-1]` | `np.ndarray` | HWC, BGR to RGB |
+| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | HWC |
+| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | BCHW, RGB |
+| CSV | `'sources.csv'` | `str`, `Path` | RTSP, RTMP, HTTP |
+| video ✅ | `'vid.mp4'` | `str`, `Path` | |
+| directory ✅ | `'path/'` | `str`, `Path` | |
+| glob ✅ | `'path/*.jpg'` | `str` | Use `*` operator |
+| YouTube ✅ | `'https://youtu.be/Zgi9g1ksQHc'` | `str` | |
+| stream ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, HTTP |
-## Image Formats
+## Image and Video Formats
-For images, YOLOv8 supports a variety of image formats defined
-in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
-following suffixes are valid for images:
+YOLOv8 supports various image and video formats, as specified
+in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). See the
+tables below for the valid suffixes and example predict commands.
+
+### Image Suffixes
| Image Suffixes | Example Predict Command | Reference |
|----------------|----------------------------------|-------------------------------------------------------------------------------|
@@ -72,11 +75,7 @@ following suffixes are valid for images:
| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) |
| .pfm | `yolo predict source=image.pfm` | [Portable FloatMap](https://en.wikipedia.org/wiki/Netpbm#File_formats) |
-## Video Formats
-
-For videos, YOLOv8 also supports a variety of video formats defined
-in [yolo/data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/data/utils.py). The
-following suffixes are valid for videos:
+### Video Suffixes
| Video Suffixes | Example Predict Command | Reference |
|----------------|----------------------------------|----------------------------------------------------------------------------------|
@@ -95,68 +94,78 @@ following suffixes are valid for videos:
## Working with Results
-Results object consists of these component objects:
+The `Results` object contains the following components:
-- `Results.boxes`: `Boxes` object with properties and methods for manipulating bboxes
-- `Results.masks`: `Masks` object used to index masks or to get segment coordinates.
-- `Results.probs`: `torch.Tensor` containing the class probabilities/logits.
-- `Results.orig_img`: Original image loaded in memory.
-- `Results.path`: `Path` containing the path to input image
+- `Results.boxes`: `Boxes` object with properties and methods for manipulating bounding boxes
+- `Results.masks`: `Masks` object for indexing masks or getting segment coordinates
+- `Results.probs`: `torch.Tensor` containing class probabilities or logits
+- `Results.orig_img`: Original image loaded in memory
+- `Results.path`: `Path` containing the path to the input image
-Each result is composed of torch.Tensor by default, in which you can easily use following functionality:
+Each result is composed of a `torch.Tensor` by default, which allows for easy manipulation:
-```python
-results = results.cuda()
-results = results.cpu()
-results = results.to("cpu")
-results = results.numpy()
-```
+!!! example "Results"
+
+ ```python
+ results = results.cuda()
+ results = results.cpu()
+ results = results.to('cpu')
+ results = results.numpy()
+ ```
### Boxes
-`Boxes` object can be used index, manipulate and convert bboxes to different formats. The box format conversion
-operations are cached, which means they're only calculated once per object and those values are reused for future calls.
+`Boxes` object can be used to index, manipulate, and convert bounding boxes to different formats. Box format conversion
+operations are cached, meaning they're only calculated once per object, and those values are reused for future calls.
-- Indexing a `Boxes` objects returns a `Boxes` object
+- Indexing a `Boxes` object returns a `Boxes` object:
-```python
-results = model(inputs)
-boxes = results[0].boxes
-box = boxes[0] # returns one box
-box.xyxy
-```
+!!! example "Boxes"
+
+ ```python
+ results = model(img)
+ boxes = results[0].boxes
+ box = boxes[0] # returns one box
+ box.xyxy
+ ```
- Properties and conversions
-```python
-boxes.xyxy # box with xyxy format, (N, 4)
-boxes.xywh # box with xywh format, (N, 4)
-boxes.xyxyn # box with xyxy format but normalized, (N, 4)
-boxes.xywhn # box with xywh format but normalized, (N, 4)
-boxes.conf # confidence score, (N, 1)
-boxes.cls # cls, (N, 1)
-boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes .
-```
+!!! example "Boxes Properties"
+
+ ```python
+ boxes.xyxy # box with xyxy format, (N, 4)
+ boxes.xywh # box with xywh format, (N, 4)
+ boxes.xyxyn # box with xyxy format but normalized, (N, 4)
+ boxes.xywhn # box with xywh format but normalized, (N, 4)
+ boxes.conf # confidence score, (N, 1)
+ boxes.cls # cls, (N, 1)
+ boxes.data # raw bboxes tensor, (N, 6) or boxes.boxes
+ ```
### Masks
`Masks` object can be used index, manipulate and convert masks to segments. The segment conversion operation is cached.
-```python
-results = model(inputs)
-masks = results[0].masks # Masks object
-masks.segments # bounding coordinates of masks, List[segment] * N
-masks.data # raw masks tensor, (N, H, W) or masks.masks
-```
+!!! example "Masks"
+
+ ```python
+ results = model(inputs)
+ masks = results[0].masks # Masks object
+ masks.segments # bounding coordinates of masks, List[segment] * N
+ masks.data # raw masks tensor, (N, H, W) or masks.masks
+ ```
### probs
`probs` attribute of `Results` class is a `Tensor` containing class probabilities of a classification operation.
-```python
-results = model(inputs)
-results[0].probs # cls prob, (num_class, )
-```
+!!! example "Probs"
+
+ ```python
+ results = model(inputs)
+ results[0].probs # cls prob, (num_class, )
+ ```
Class reference documentation for `Results` module and its components can be found [here](../reference/results.md)
@@ -165,16 +174,14 @@ Class reference documentation for `Results` module and its components can be fou
You can use `plot()` function of `Result` object to plot results on in image object. It plots all components(boxes,
masks, classification logits, etc.) found in the results object
-```python
-res = model(img)
-res_plotted = res[0].plot()
-cv2.imshow("result", res_plotted)
-```
+!!! example "Plotting"
-!!! example "`plot()` arguments"
+ ```python
+ res = model(img)
+ res_plotted = res[0].plot()
+ cv2.imshow("result", res_plotted)
+ ```
- `show_conf (bool)`: Show confidence
-
- `line_width (Float)`: The line width of boxes. Automatically scaled to img size if not provided
-
- `font_size (Float)`: The font size of . Automatically scaled to img size if not provided
+- `show_conf (bool)`: Show confidence
+- `line_width (Float)`: The line width of boxes. Automatically scaled to img size if not provided
+- `font_size (Float)`: The font size of . Automatically scaled to img size if not provided
diff --git a/docs/quickstart.md b/docs/quickstart.md
index 3eb4443..8725b77 100644
--- a/docs/quickstart.md
+++ b/docs/quickstart.md
@@ -4,70 +4,130 @@ Install YOLOv8 via the `ultralytics` pip package for the latest stable release o
the [https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics) repository for the most
up-to-date version.
-!!! example "Pip install method (recommended)"
+!!! example "Install"
- ```bash
- pip install ultralytics
- ```
+ === "pip install (recommended)"
+ ```bash
+ pip install ultralytics
+ ```
-!!! example "Git clone method (for development)"
+ === "git clone (for development)"
+ ```bash
+ git clone https://github.com/ultralytics/ultralytics
+ cd ultralytics
+ pip install -e .
+ ```
+
+See the `ultralytics` [requirements.txt](https://github.com/ultralytics/ultralytics/blob/main/requirements.txt) file for a list of dependencies. Note that `pip` automatically installs all required dependencies.
+
+!!! tip "Tip"
+
+ PyTorch requirements vary by operating system and CUDA requirements, so it's recommended to install PyTorch first following instructions at [https://pytorch.org/get-started/locally](https://pytorch.org/get-started/locally).
+
+
+  +
- ```bash
- git clone https://github.com/ultralytics/ultralytics
- cd ultralytics
- pip install -e '.[dev]'
- ```
- See contributing section to know more about contributing to the project
## Use with CLI
-The YOLO command line interface (CLI) lets you simply train, validate or infer models on various tasks and versions.
-CLI requires no customization or code. You can simply run all tasks from the terminal with the `yolo` command.
+The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
+CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
+
!!! example
=== "Syntax"
+
+ Ultralytics `yolo` commands use the following syntax:
```bash
- yolo task=detect mode=train model=yolov8n.yaml args...
- classify predict yolov8n-cls.yaml args...
- segment val yolov8n-seg.yaml args...
- export yolov8n.pt format=onnx args...
+ yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of [detect, segment, classify]
+ MODE (required) is one of [train, val, predict, export, track]
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ ```
+ See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`
+
+ === "Train"
+
+ Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ ```bash
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
```
- === "Example training"
+ === "Predict"
+
+ Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
- yolo detect train model=yolov8n.pt data=coco128.yaml device=0
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
```
- === "Example Multi-GPU training"
+
+ === "Val"
+
+ Val a pretrained detection model at batch-size 1 and image size 640:
```bash
- yolo detect train model=yolov8n.pt data=coco128.yaml device=\'0,1,2,3\'
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
```
+ === "Export"
+
+ Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ ```bash
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+ ```
+
+ === "Special"
+
+ Run special commands to see version, view settings, run checks and more:
+ ```bash
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
+ ```
+
+
+!!! warning "Warning"
+
+ Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.
+
+ - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
+ - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
+ - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
+
[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
## Use with Python
-Python usage allows users to easily use YOLOv8 inside their Python projects. It provides functions for loading and
-running the model, as well as for processing the model's output. The interface is designed to be easy to use, so that
-users can quickly implement object detection in their projects.
+YOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
-Overall, the Python interface is a useful tool for anyone looking to incorporate object detection, segmentation or
-classification into their Python projects using YOLOv8.
+For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.
!!! example
```python
from ultralytics import YOLO
-
- # Load a model
- model = YOLO('yolov8n.yaml') # build a new model from scratch
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
- # Use the model
- results = model.train(data='coco128.yaml', epochs=3) # train the model
- results = model.val() # evaluate model performance on the validation set
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
- success = model.export(format='onnx') # export the model to ONNX format
+ # Create a new YOLO model from scratch
+ model = YOLO('yolov8n.yaml')
+
+ # Load a pretrained YOLO model (recommended for training)
+ model = YOLO('yolov8n.pt')
+
+ # Train the model using the 'coco128.yaml' dataset for 3 epochs
+ results = model.train(data='coco128.yaml', epochs=3)
+
+ # Evaluate the model's performance on the validation set
+ results = model.val()
+
+ # Perform object detection on an image using the model
+ results = model('https://ultralytics.com/images/bus.jpg')
+
+ # Export the model to ONNX format
+ success = model.export(format='onnx')
```
[Python Guide](usage/python.md){.md-button .md-button--primary}
diff --git a/docs/stylesheets/style.css b/docs/stylesheets/style.css
index 4bed4e1..85f766c 100644
--- a/docs/stylesheets/style.css
+++ b/docs/stylesheets/style.css
@@ -1,14 +1,33 @@
+/* Table format like GitHub ----------------------------------------------------------------------------------------- */
th, td {
- border: 0.5px solid var(--md-typeset-table-color);
- border-spacing: 0px;
- border-bottom: none;
- border-left: none;
- border-top: none;
+ border: 1px solid var(--md-typeset-table-color);
+ border-spacing: 0;
+ border-bottom: none;
+ border-left: none;
+ border-top: none;
}
+
.md-typeset__table {
- min-width: 100%;
- line-height: 1;
+ line-height: 1;
}
-.md-typeset table:not([class]) {
- display: table;
+
+.md-typeset__table table:not([class]) {
+ font-size: .74rem;
+ border-right: none;
}
+
+.md-typeset__table table:not([class]) td,
+.md-typeset__table table:not([class]) th {
+ padding: 9px;
+}
+
+/* light mode alternating table bg colors */
+.md-typeset__table tr:nth-child(2n) {
+ background-color: #f8f8f8;
+}
+
+/* dark mode alternating table bg colors */
+[data-md-color-scheme="slate"] .md-typeset__table tr:nth-child(2n) {
+ background-color: hsla(var(--md-hue),25%,25%,1)
+}
+/* Table format like GitHub ----------------------------------------------------------------------------------------- */
diff --git a/docs/usage/cli.md b/docs/usage/cli.md
index 20ada7c..11b8a37 100644
--- a/docs/usage/cli.md
+++ b/docs/usage/cli.md
@@ -1,14 +1,60 @@
-The YOLO Command Line Interface (CLI) is the easiest way to get started training, validating, predicting and exporting
-YOLOv8 models.
+# Command Line Interface Usage
-The `yolo` command is used for all actions:
+The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
+CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command.
-!!! example ""
+!!! example
- === "CLI"
-
+ === "Syntax"
+
+ Ultralytics `yolo` commands use the following syntax:
```bash
yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of [detect, segment, classify]
+ MODE (required) is one of [train, val, predict, export, track]
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ ```
+ See all ARGS in the full [Configuration Guide](./cfg.md) or with `yolo cfg`
+
+ === "Train"
+
+ Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ ```bash
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
+ ```
+
+ === "Predict"
+
+ Predict a YouTube video using a pretrained segmentation model at image size 320:
+ ```bash
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
+ ```
+
+ === "Val"
+
+ Val a pretrained detection model at batch-size 1 and image size 640:
+ ```bash
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
+ ```
+
+ === "Export"
+
+ Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ ```bash
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+ ```
+
+ === "Special"
+
+ Run special commands to see version, view settings, run checks and more:
+ ```bash
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
```
Where:
@@ -20,9 +66,9 @@ Where:
For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`
GitHub [source](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml).
-!!! note ""
+!!! warning "Warning"
- Note: Arguments MUST be passed as `arg=val` with an equals sign and a space between `arg=val` pairs
+ Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
@@ -33,63 +79,100 @@ Where:
Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. For a full list of available arguments see
the [Configuration](cfg.md) page.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
- yolo detect train resume model=last.pt # resume training
- ```
+ === "Train"
+
+ Start training YOLOv8n on COCO128 for 100 epochs at image-size 640.
+ ```bash
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+ === "Resume"
+
+ Resume an interrupted training.
+ ```bash
+ yolo detect train resume model=last.pt
+ ```
## Val
Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
training `data` and arguments as model attributes.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo detect val model=yolov8n.pt # val official model
- yolo detect val model=path/to/best.pt # val custom model
- ```
+ === "Official"
+
+ Validate an official YOLOv8n model.
+ ```bash
+ yolo detect val model=yolov8n.pt
+ ```
+
+ === "Custom"
+
+ Validate a custom-trained model.
+ ```bash
+ yolo detect val model=path/to/best.pt
+ ```
## Predict
Use a trained YOLOv8n model to run predictions on images.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
- yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
- ```
+ === "Official"
+
+ Predict with an official YOLOv8n model.
+ ```bash
+ yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+ === "Custom"
+
+ Predict with a custom model.
+ ```bash
+ yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'
+ ```
## Export
Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo export model=yolov8n.pt format=onnx # export official model
- yolo export model=path/to/best.pt format=onnx # export custom trained model
- ```
+ === "Official"
- Available YOLOv8 export formats include:
-
- | Format | `format=` | Model |
- |----------------------------------------------------------------------------|--------------------|---------------------------|
- | [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` |
- | [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` |
- | [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` |
- | [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` |
- | [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` |
- | [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` |
- | [TensorFlow SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` |
- | [TensorFlow GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` |
- | [TensorFlow Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` |
- | [TensorFlow Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` |
- | [TensorFlow.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` |
- | [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` |
+ Export an official YOLOv8n model to ONNX format.
+ ```bash
+ yolo export model=yolov8n.pt format=onnx
+ ```
+
+ === "Custom"
+
+ Export a custom-trained model to ONNX format.
+ ```bash
+ yolo export model=path/to/best.pt format=onnx
+ ```
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
---
@@ -99,19 +182,19 @@ Default arguments can be overridden by simply passing them as arguments in the C
!!! tip ""
- === "Example 1"
+ === "Train"
Train a detection model for `10 epochs` with `learning_rate` of `0.01`
```bash
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
```
- === "Example 2"
+ === "Predict"
Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
yolo segment predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
```
- === "Example 3"
+ === "Val"
Validate a pretrained detection model at batch-size 1 and image size 640:
```bash
yolo detect val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
diff --git a/docs/usage/python.md b/docs/usage/python.md
index 60ef051..6bfc773 100644
--- a/docs/usage/python.md
+++ b/docs/usage/python.md
@@ -1,4 +1,43 @@
-The simplest way of simply using YOLOv8 directly in a Python environment.
+# Python Usage
+
+Welcome to the YOLOv8 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLOv8 into
+your Python projects for object detection, segmentation, and classification. Here, you'll learn how to load and use
+pretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable
+resource for anyone looking to incorporate YOLOv8 into their Python projects, allowing you to quickly implement advanced
+object detection capabilities. Let's get started!
+
+For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX
+format with just a few lines of code.
+
+!!! example "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLO model from scratch
+ model = YOLO('yolov8n.yaml')
+
+ # Load a pretrained YOLO model (recommended for training)
+ model = YOLO('yolov8n.pt')
+
+ # Train the model using the 'coco128.yaml' dataset for 3 epochs
+ results = model.train(data='coco128.yaml', epochs=3)
+
+ # Evaluate the model's performance on the validation set
+ results = model.val()
+
+ # Perform object detection on an image using the model
+ results = model('https://ultralytics.com/images/bus.jpg')
+
+ # Export the model to ONNX format
+ success = model.export(format='onnx')
+ ```
+
+## [Train](../modes/train.md)
+
+Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
!!! example "Train"
@@ -25,6 +64,14 @@ The simplest way of simply using YOLOv8 directly in a Python environment.
model.train(resume=True)
```
+[Train Examples](../modes/train.md){ .md-button .md-button--primary}
+
+## [Val](../modes/val.md)
+
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
!!! example "Val"
=== "Val after training"
@@ -47,6 +94,14 @@ The simplest way of simply using YOLOv8 directly in a Python environment.
model.val(data='coco128.yaml')
```
+[Val Examples](../modes/val.md){ .md-button .md-button--primary}
+
+## [Predict](../modes/predict.md)
+
+Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
+model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
+predicts the classes and locations of objects in the input images or videos.
+
!!! example "Predict"
=== "From source"
@@ -108,30 +163,86 @@ The simplest way of simply using YOLOv8 directly in a Python environment.
result = result.numpy()
```
-!!! note "Export and Deployment"
+[Predict Examples](../modes/predict.md){ .md-button .md-button--primary}
- === "Export, Fuse & info"
+## [Export](../modes/export.md)
+
+Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
+converted to a format that can be used by other software applications or hardware devices. This mode is useful when
+deploying the model to production environments.
+
+!!! example "Export"
+
+ === "Export to ONNX"
+
+ Export an official YOLOv8n model to ONNX with dynamic batch-size and image-size.
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ model.export(format='onnx', dynamic=True)
+ ```
+
+ === "Export to TensorRT"
+
+ Export an official YOLOv8n model to TensorRT on `device=0` for acceleration on CUDA devices.
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ model.export(format='onnx', device=0)
+ ```
+
+[Export Examples](../modes/export.md){ .md-button .md-button--primary}
+
+## [Track](../modes/track.md)
+
+Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
+checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
+for applications such as surveillance systems or self-driving cars.
+
+!!! example "Track"
+
+ === "Python"
+
```python
from ultralytics import YOLO
-
- model = YOLO("model.pt")
- model.fuse()
- model.info(verbose=True) # Print model information
- model.export(format=) # TODO:
-
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official detection model
+ model = YOLO('yolov8n-seg.pt') # load an official segmentation model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Track with the model
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
```
- === "Deployment"
+[Track Examples](../modes/track.md){ .md-button .md-button--primary}
- More functionality coming soon
+## [Benchmark](../modes/benchmark.md)
-To know more about using `YOLO` models, refer Model class Reference
+Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
+information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
-[Model reference](../reference/model.md){ .md-button .md-button--primary}
+!!! example "Benchmark"
----
+ === "Python"
+
+ Benchmark an official YOLOv8n model across all export formats.
+ ```python
+ from ultralytics.yolo.utils.benchmarks import benchmark
+
+ # Benchmark
+ benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
+ ```
-### Using Trainers
+[Benchmark Examples](../modes/benchmark.md){ .md-button .md-button--primary}
+
+## Using Trainers
`YOLO` model class is a high-level wrapper on the Trainer classes. Each YOLO task has its own trainer that inherits
from `BaseTrainer`.
diff --git a/docs/yolov5/architecture.md b/docs/yolov5/architecture.md
new file mode 100644
index 0000000..d8a05fb
--- /dev/null
+++ b/docs/yolov5/architecture.md
@@ -0,0 +1,209 @@
+## 1. Model Structure
+
+YOLOv5 (v6.0/6.1) consists of:
+- **Backbone**: `New CSP-Darknet53`
+- **Neck**: `SPPF`, `New CSP-PAN`
+- **Head**: `YOLOv3 Head`
+
+Model structure (`yolov5l.yaml`):
+
+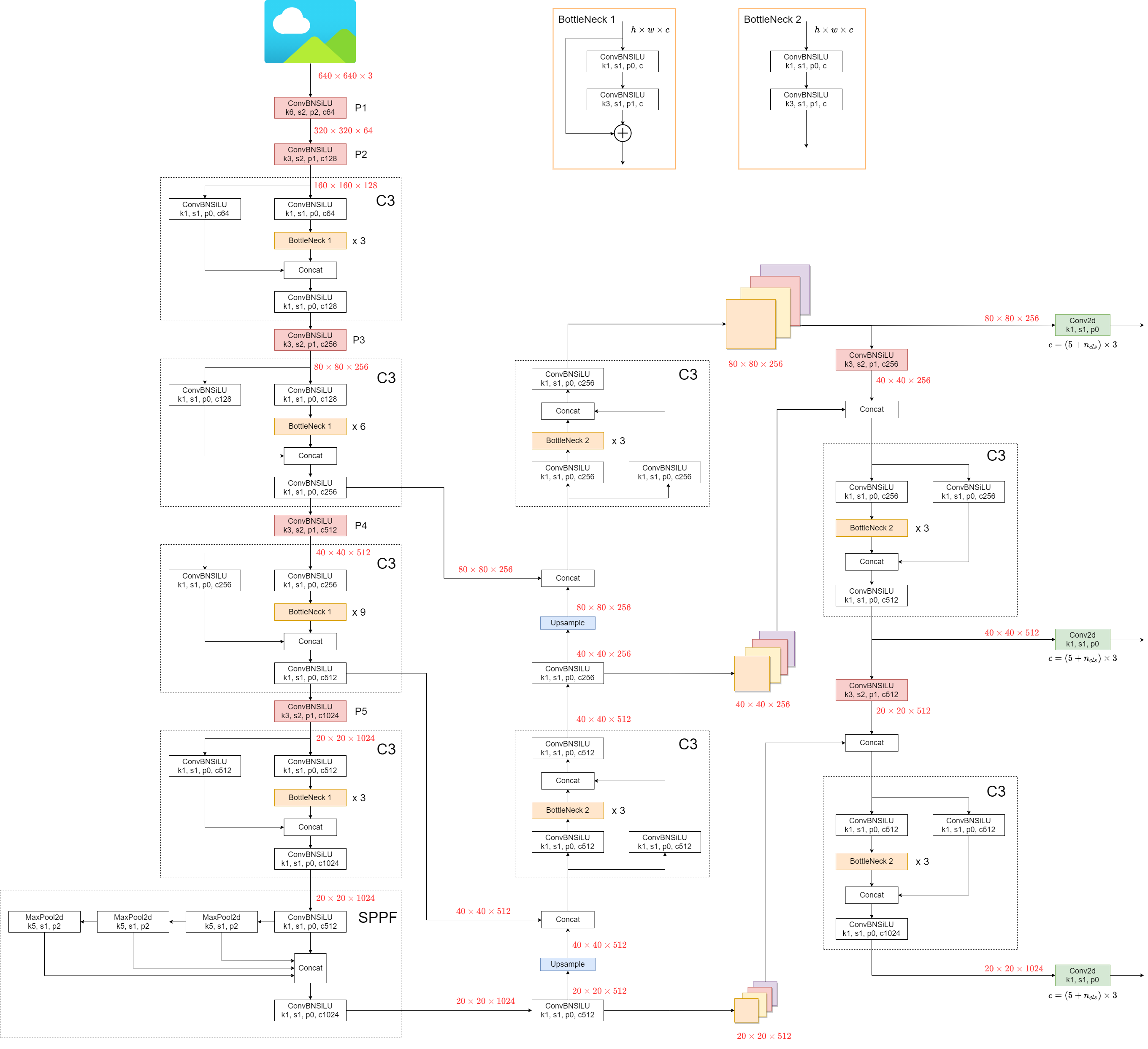
+
+
+Some minor changes compared to previous versions:
+
+1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)
+2. Replace the `SPP` structure with `SPPF`(more than double the speed)
+
+
+
- ```bash
- git clone https://github.com/ultralytics/ultralytics
- cd ultralytics
- pip install -e '.[dev]'
- ```
- See contributing section to know more about contributing to the project
## Use with CLI
-The YOLO command line interface (CLI) lets you simply train, validate or infer models on various tasks and versions.
-CLI requires no customization or code. You can simply run all tasks from the terminal with the `yolo` command.
+The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
+CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command. Check out the [CLI Guide](usage/cli.md) to learn more about using YOLOv8 from the command line.
+
!!! example
=== "Syntax"
+
+ Ultralytics `yolo` commands use the following syntax:
```bash
- yolo task=detect mode=train model=yolov8n.yaml args...
- classify predict yolov8n-cls.yaml args...
- segment val yolov8n-seg.yaml args...
- export yolov8n.pt format=onnx args...
+ yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of [detect, segment, classify]
+ MODE (required) is one of [train, val, predict, export, track]
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ ```
+ See all ARGS in the full [Configuration Guide](usage/cfg.md) or with `yolo cfg`
+
+ === "Train"
+
+ Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ ```bash
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
```
- === "Example training"
+ === "Predict"
+
+ Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
- yolo detect train model=yolov8n.pt data=coco128.yaml device=0
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
```
- === "Example Multi-GPU training"
+
+ === "Val"
+
+ Val a pretrained detection model at batch-size 1 and image size 640:
```bash
- yolo detect train model=yolov8n.pt data=coco128.yaml device=\'0,1,2,3\'
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
```
+ === "Export"
+
+ Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ ```bash
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+ ```
+
+ === "Special"
+
+ Run special commands to see version, view settings, run checks and more:
+ ```bash
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
+ ```
+
+
+!!! warning "Warning"
+
+ Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.
+
+ - `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
+ - `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
+ - `yolo predict --model yolov8n.pt --imgsz 640 --conf 0.25` ❌
+
[CLI Guide](usage/cli.md){ .md-button .md-button--primary}
## Use with Python
-Python usage allows users to easily use YOLOv8 inside their Python projects. It provides functions for loading and
-running the model, as well as for processing the model's output. The interface is designed to be easy to use, so that
-users can quickly implement object detection in their projects.
+YOLOv8's Python interface allows for seamless integration into your Python projects, making it easy to load, run, and process the model's output. Designed with simplicity and ease of use in mind, the Python interface enables users to quickly implement object detection, segmentation, and classification in their projects. This makes YOLOv8's Python interface an invaluable tool for anyone looking to incorporate these functionalities into their Python projects.
-Overall, the Python interface is a useful tool for anyone looking to incorporate object detection, segmentation or
-classification into their Python projects using YOLOv8.
+For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX format with just a few lines of code. Check out the [Python Guide](usage/python.md) to learn more about using YOLOv8 within your Python projects.
!!! example
```python
from ultralytics import YOLO
-
- # Load a model
- model = YOLO('yolov8n.yaml') # build a new model from scratch
- model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
- # Use the model
- results = model.train(data='coco128.yaml', epochs=3) # train the model
- results = model.val() # evaluate model performance on the validation set
- results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
- success = model.export(format='onnx') # export the model to ONNX format
+ # Create a new YOLO model from scratch
+ model = YOLO('yolov8n.yaml')
+
+ # Load a pretrained YOLO model (recommended for training)
+ model = YOLO('yolov8n.pt')
+
+ # Train the model using the 'coco128.yaml' dataset for 3 epochs
+ results = model.train(data='coco128.yaml', epochs=3)
+
+ # Evaluate the model's performance on the validation set
+ results = model.val()
+
+ # Perform object detection on an image using the model
+ results = model('https://ultralytics.com/images/bus.jpg')
+
+ # Export the model to ONNX format
+ success = model.export(format='onnx')
```
[Python Guide](usage/python.md){.md-button .md-button--primary}
diff --git a/docs/stylesheets/style.css b/docs/stylesheets/style.css
index 4bed4e1..85f766c 100644
--- a/docs/stylesheets/style.css
+++ b/docs/stylesheets/style.css
@@ -1,14 +1,33 @@
+/* Table format like GitHub ----------------------------------------------------------------------------------------- */
th, td {
- border: 0.5px solid var(--md-typeset-table-color);
- border-spacing: 0px;
- border-bottom: none;
- border-left: none;
- border-top: none;
+ border: 1px solid var(--md-typeset-table-color);
+ border-spacing: 0;
+ border-bottom: none;
+ border-left: none;
+ border-top: none;
}
+
.md-typeset__table {
- min-width: 100%;
- line-height: 1;
+ line-height: 1;
}
-.md-typeset table:not([class]) {
- display: table;
+
+.md-typeset__table table:not([class]) {
+ font-size: .74rem;
+ border-right: none;
}
+
+.md-typeset__table table:not([class]) td,
+.md-typeset__table table:not([class]) th {
+ padding: 9px;
+}
+
+/* light mode alternating table bg colors */
+.md-typeset__table tr:nth-child(2n) {
+ background-color: #f8f8f8;
+}
+
+/* dark mode alternating table bg colors */
+[data-md-color-scheme="slate"] .md-typeset__table tr:nth-child(2n) {
+ background-color: hsla(var(--md-hue),25%,25%,1)
+}
+/* Table format like GitHub ----------------------------------------------------------------------------------------- */
diff --git a/docs/usage/cli.md b/docs/usage/cli.md
index 20ada7c..11b8a37 100644
--- a/docs/usage/cli.md
+++ b/docs/usage/cli.md
@@ -1,14 +1,60 @@
-The YOLO Command Line Interface (CLI) is the easiest way to get started training, validating, predicting and exporting
-YOLOv8 models.
+# Command Line Interface Usage
-The `yolo` command is used for all actions:
+The YOLO command line interface (CLI) allows for simple single-line commands without the need for a Python environment.
+CLI requires no customization or Python code. You can simply run all tasks from the terminal with the `yolo` command.
-!!! example ""
+!!! example
- === "CLI"
-
+ === "Syntax"
+
+ Ultralytics `yolo` commands use the following syntax:
```bash
yolo TASK MODE ARGS
+
+ Where TASK (optional) is one of [detect, segment, classify]
+ MODE (required) is one of [train, val, predict, export, track]
+ ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
+ ```
+ See all ARGS in the full [Configuration Guide](./cfg.md) or with `yolo cfg`
+
+ === "Train"
+
+ Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ ```bash
+ yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
+ ```
+
+ === "Predict"
+
+ Predict a YouTube video using a pretrained segmentation model at image size 320:
+ ```bash
+ yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
+ ```
+
+ === "Val"
+
+ Val a pretrained detection model at batch-size 1 and image size 640:
+ ```bash
+ yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
+ ```
+
+ === "Export"
+
+ Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
+ ```bash
+ yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
+ ```
+
+ === "Special"
+
+ Run special commands to see version, view settings, run checks and more:
+ ```bash
+ yolo help
+ yolo checks
+ yolo version
+ yolo settings
+ yolo copy-cfg
+ yolo cfg
```
Where:
@@ -20,9 +66,9 @@ Where:
For a full list of available `ARGS` see the [Configuration](cfg.md) page and `defaults.yaml`
GitHub [source](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/yolo/cfg/default.yaml).
-!!! note ""
+!!! warning "Warning"
- Note: Arguments MUST be passed as `arg=val` with an equals sign and a space between `arg=val` pairs
+ Arguments must be passed as `arg=val` pairs, split by an equals `=` sign and delimited by spaces ` ` between pairs. Do not use `--` argument prefixes or commas `,` beteen arguments.
- `yolo predict model=yolov8n.pt imgsz=640 conf=0.25` ✅
- `yolo predict model yolov8n.pt imgsz 640 conf 0.25` ❌
@@ -33,63 +79,100 @@ Where:
Train YOLOv8n on the COCO128 dataset for 100 epochs at image size 640. For a full list of available arguments see
the [Configuration](cfg.md) page.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
- yolo detect train resume model=last.pt # resume training
- ```
+ === "Train"
+
+ Start training YOLOv8n on COCO128 for 100 epochs at image-size 640.
+ ```bash
+ yolo detect train data=coco128.yaml model=yolov8n.pt epochs=100 imgsz=640
+ ```
+
+ === "Resume"
+
+ Resume an interrupted training.
+ ```bash
+ yolo detect train resume model=last.pt
+ ```
## Val
Validate trained YOLOv8n model accuracy on the COCO128 dataset. No argument need to passed as the `model` retains it's
training `data` and arguments as model attributes.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo detect val model=yolov8n.pt # val official model
- yolo detect val model=path/to/best.pt # val custom model
- ```
+ === "Official"
+
+ Validate an official YOLOv8n model.
+ ```bash
+ yolo detect val model=yolov8n.pt
+ ```
+
+ === "Custom"
+
+ Validate a custom-trained model.
+ ```bash
+ yolo detect val model=path/to/best.pt
+ ```
## Predict
Use a trained YOLOv8n model to run predictions on images.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' # predict with official model
- yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg' # predict with custom model
- ```
+ === "Official"
+
+ Predict with an official YOLOv8n model.
+ ```bash
+ yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
+ ```
+
+ === "Custom"
+
+ Predict with a custom model.
+ ```bash
+ yolo detect predict model=path/to/best.pt source='https://ultralytics.com/images/bus.jpg'
+ ```
## Export
Export a YOLOv8n model to a different format like ONNX, CoreML, etc.
-!!! example ""
+!!! example "Example"
- ```bash
- yolo export model=yolov8n.pt format=onnx # export official model
- yolo export model=path/to/best.pt format=onnx # export custom trained model
- ```
+ === "Official"
- Available YOLOv8 export formats include:
-
- | Format | `format=` | Model |
- |----------------------------------------------------------------------------|--------------------|---------------------------|
- | [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` |
- | [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` |
- | [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` |
- | [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` |
- | [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` |
- | [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` |
- | [TensorFlow SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` |
- | [TensorFlow GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` |
- | [TensorFlow Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` |
- | [TensorFlow Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` |
- | [TensorFlow.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` |
- | [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` |
+ Export an official YOLOv8n model to ONNX format.
+ ```bash
+ yolo export model=yolov8n.pt format=onnx
+ ```
+
+ === "Custom"
+
+ Export a custom-trained model to ONNX format.
+ ```bash
+ yolo export model=path/to/best.pt format=onnx
+ ```
+
+Available YOLOv8 export formats are in the table below. You can export to any format using the `format` argument,
+i.e. `format='onnx'` or `format='engine'`.
+
+| Format | `format` Argument | Model | Metadata |
+|--------------------------------------------------------------------|-------------------|---------------------------|----------|
+| [PyTorch](https://pytorch.org/) | - | `yolov8n.pt` | ✅ |
+| [TorchScript](https://pytorch.org/docs/stable/jit.html) | `torchscript` | `yolov8n.torchscript` | ✅ |
+| [ONNX](https://onnx.ai/) | `onnx` | `yolov8n.onnx` | ✅ |
+| [OpenVINO](https://docs.openvino.ai/latest/index.html) | `openvino` | `yolov8n_openvino_model/` | ✅ |
+| [TensorRT](https://developer.nvidia.com/tensorrt) | `engine` | `yolov8n.engine` | ✅ |
+| [CoreML](https://github.com/apple/coremltools) | `coreml` | `yolov8n.mlmodel` | ✅ |
+| [TF SavedModel](https://www.tensorflow.org/guide/saved_model) | `saved_model` | `yolov8n_saved_model/` | ✅ |
+| [TF GraphDef](https://www.tensorflow.org/api_docs/python/tf/Graph) | `pb` | `yolov8n.pb` | ❌ |
+| [TF Lite](https://www.tensorflow.org/lite) | `tflite` | `yolov8n.tflite` | ✅ |
+| [TF Edge TPU](https://coral.ai/docs/edgetpu/models-intro/) | `edgetpu` | `yolov8n_edgetpu.tflite` | ✅ |
+| [TF.js](https://www.tensorflow.org/js) | `tfjs` | `yolov8n_web_model/` | ✅ |
+| [PaddlePaddle](https://github.com/PaddlePaddle) | `paddle` | `yolov8n_paddle_model/` | ✅ |
---
@@ -99,19 +182,19 @@ Default arguments can be overridden by simply passing them as arguments in the C
!!! tip ""
- === "Example 1"
+ === "Train"
Train a detection model for `10 epochs` with `learning_rate` of `0.01`
```bash
yolo detect train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01
```
- === "Example 2"
+ === "Predict"
Predict a YouTube video using a pretrained segmentation model at image size 320:
```bash
yolo segment predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
```
- === "Example 3"
+ === "Val"
Validate a pretrained detection model at batch-size 1 and image size 640:
```bash
yolo detect val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=640
diff --git a/docs/usage/python.md b/docs/usage/python.md
index 60ef051..6bfc773 100644
--- a/docs/usage/python.md
+++ b/docs/usage/python.md
@@ -1,4 +1,43 @@
-The simplest way of simply using YOLOv8 directly in a Python environment.
+# Python Usage
+
+Welcome to the YOLOv8 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLOv8 into
+your Python projects for object detection, segmentation, and classification. Here, you'll learn how to load and use
+pretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable
+resource for anyone looking to incorporate YOLOv8 into their Python projects, allowing you to quickly implement advanced
+object detection capabilities. Let's get started!
+
+For example, users can load a model, train it, evaluate its performance on a validation set, and even export it to ONNX
+format with just a few lines of code.
+
+!!! example "Python"
+
+ ```python
+ from ultralytics import YOLO
+
+ # Create a new YOLO model from scratch
+ model = YOLO('yolov8n.yaml')
+
+ # Load a pretrained YOLO model (recommended for training)
+ model = YOLO('yolov8n.pt')
+
+ # Train the model using the 'coco128.yaml' dataset for 3 epochs
+ results = model.train(data='coco128.yaml', epochs=3)
+
+ # Evaluate the model's performance on the validation set
+ results = model.val()
+
+ # Perform object detection on an image using the model
+ results = model('https://ultralytics.com/images/bus.jpg')
+
+ # Export the model to ONNX format
+ success = model.export(format='onnx')
+ ```
+
+## [Train](../modes/train.md)
+
+Train mode is used for training a YOLOv8 model on a custom dataset. In this mode, the model is trained using the
+specified dataset and hyperparameters. The training process involves optimizing the model's parameters so that it can
+accurately predict the classes and locations of objects in an image.
!!! example "Train"
@@ -25,6 +64,14 @@ The simplest way of simply using YOLOv8 directly in a Python environment.
model.train(resume=True)
```
+[Train Examples](../modes/train.md){ .md-button .md-button--primary}
+
+## [Val](../modes/val.md)
+
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a
+validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters
+of the model to improve its performance.
+
!!! example "Val"
=== "Val after training"
@@ -47,6 +94,14 @@ The simplest way of simply using YOLOv8 directly in a Python environment.
model.val(data='coco128.yaml')
```
+[Val Examples](../modes/val.md){ .md-button .md-button--primary}
+
+## [Predict](../modes/predict.md)
+
+Predict mode is used for making predictions using a trained YOLOv8 model on new images or videos. In this mode, the
+model is loaded from a checkpoint file, and the user can provide images or videos to perform inference. The model
+predicts the classes and locations of objects in the input images or videos.
+
!!! example "Predict"
=== "From source"
@@ -108,30 +163,86 @@ The simplest way of simply using YOLOv8 directly in a Python environment.
result = result.numpy()
```
-!!! note "Export and Deployment"
+[Predict Examples](../modes/predict.md){ .md-button .md-button--primary}
- === "Export, Fuse & info"
+## [Export](../modes/export.md)
+
+Export mode is used for exporting a YOLOv8 model to a format that can be used for deployment. In this mode, the model is
+converted to a format that can be used by other software applications or hardware devices. This mode is useful when
+deploying the model to production environments.
+
+!!! example "Export"
+
+ === "Export to ONNX"
+
+ Export an official YOLOv8n model to ONNX with dynamic batch-size and image-size.
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ model.export(format='onnx', dynamic=True)
+ ```
+
+ === "Export to TensorRT"
+
+ Export an official YOLOv8n model to TensorRT on `device=0` for acceleration on CUDA devices.
+ ```python
+ from ultralytics import YOLO
+
+ model = YOLO('yolov8n.pt')
+ model.export(format='onnx', device=0)
+ ```
+
+[Export Examples](../modes/export.md){ .md-button .md-button--primary}
+
+## [Track](../modes/track.md)
+
+Track mode is used for tracking objects in real-time using a YOLOv8 model. In this mode, the model is loaded from a
+checkpoint file, and the user can provide a live video stream to perform real-time object tracking. This mode is useful
+for applications such as surveillance systems or self-driving cars.
+
+!!! example "Track"
+
+ === "Python"
+
```python
from ultralytics import YOLO
-
- model = YOLO("model.pt")
- model.fuse()
- model.info(verbose=True) # Print model information
- model.export(format=) # TODO:
-
+
+ # Load a model
+ model = YOLO('yolov8n.pt') # load an official detection model
+ model = YOLO('yolov8n-seg.pt') # load an official segmentation model
+ model = YOLO('path/to/best.pt') # load a custom model
+
+ # Track with the model
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True)
+ results = model.track(source="https://youtu.be/Zgi9g1ksQHc", show=True, tracker="bytetrack.yaml")
```
- === "Deployment"
+[Track Examples](../modes/track.md){ .md-button .md-button--primary}
- More functionality coming soon
+## [Benchmark](../modes/benchmark.md)
-To know more about using `YOLO` models, refer Model class Reference
+Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide
+information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
+or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export
+formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for
+their specific use case based on their requirements for speed and accuracy.
-[Model reference](../reference/model.md){ .md-button .md-button--primary}
+!!! example "Benchmark"
----
+ === "Python"
+
+ Benchmark an official YOLOv8n model across all export formats.
+ ```python
+ from ultralytics.yolo.utils.benchmarks import benchmark
+
+ # Benchmark
+ benchmark(model='yolov8n.pt', imgsz=640, half=False, device=0)
+ ```
-### Using Trainers
+[Benchmark Examples](../modes/benchmark.md){ .md-button .md-button--primary}
+
+## Using Trainers
`YOLO` model class is a high-level wrapper on the Trainer classes. Each YOLO task has its own trainer that inherits
from `BaseTrainer`.
diff --git a/docs/yolov5/architecture.md b/docs/yolov5/architecture.md
new file mode 100644
index 0000000..d8a05fb
--- /dev/null
+++ b/docs/yolov5/architecture.md
@@ -0,0 +1,209 @@
+## 1. Model Structure
+
+YOLOv5 (v6.0/6.1) consists of:
+- **Backbone**: `New CSP-Darknet53`
+- **Neck**: `SPPF`, `New CSP-PAN`
+- **Head**: `YOLOv3 Head`
+
+Model structure (`yolov5l.yaml`):
+
+
+
+
+Some minor changes compared to previous versions:
+
+1. Replace the `Focus` structure with `6x6 Conv2d`(more efficient, refer #4825)
+2. Replace the `SPP` structure with `SPPF`(more than double the speed)
+
+ +
+- Copy paste
+
+
+- Copy paste
+ +
+- Random affine(Rotation, Scale, Translation and Shear)
+
+
+- Random affine(Rotation, Scale, Translation and Shear)
+ +
+- MixUp
+
+
+- MixUp
+ +
+- Albumentations
+- Augment HSV(Hue, Saturation, Value)
+
+
+- Albumentations
+- Augment HSV(Hue, Saturation, Value)
+ +
+- Random horizontal flip
+
+
+- Random horizontal flip
+ +
+
+
+## 3. Training Strategies
+
+- Multi-scale training(0.5~1.5x)
+- AutoAnchor(For training custom data)
+- Warmup and Cosine LR scheduler
+- EMA(Exponential Moving Average)
+- Mixed precision
+- Evolve hyper-parameters
+
+
+
+## 4. Others
+
+### 4.1 Compute Losses
+
+The YOLOv5 loss consists of three parts:
+
+- Classes loss(BCE loss)
+- Objectness loss(BCE loss)
+- Location loss(CIoU loss)
+
+
+
+### 4.2 Balance Losses
+The objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.
+
+
+
+### 4.3 Eliminate Grid Sensitivity
+In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:
+
++c_x)
++c_y)
+
+
+
+
+
+
+
+## 3. Training Strategies
+
+- Multi-scale training(0.5~1.5x)
+- AutoAnchor(For training custom data)
+- Warmup and Cosine LR scheduler
+- EMA(Exponential Moving Average)
+- Mixed precision
+- Evolve hyper-parameters
+
+
+
+## 4. Others
+
+### 4.1 Compute Losses
+
+The YOLOv5 loss consists of three parts:
+
+- Classes loss(BCE loss)
+- Objectness loss(BCE loss)
+- Location loss(CIoU loss)
+
+
+
+### 4.2 Balance Losses
+The objectness losses of the three prediction layers(`P3`, `P4`, `P5`) are weighted differently. The balance weights are `[4.0, 1.0, 0.4]` respectively.
+
+
+
+### 4.3 Eliminate Grid Sensitivity
+In YOLOv2 and YOLOv3, the formula for calculating the predicted target information is:
+
++c_x)
++c_y)
+
+
+
+ +
+
+
+In YOLOv5, the formula is:
+
+-0.5)+c_x)
+-0.5)+c_y)
+)^2)
+)^2)
+
+Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).
+Therefore, offset can easily get 0 or 1.
+
+
+
+
+
+In YOLOv5, the formula is:
+
+-0.5)+c_x)
+-0.5)+c_y)
+)^2)
+)^2)
+
+Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5).
+Therefore, offset can easily get 0 or 1.
+
+ +
+Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)
+
+
+
+Compare the height and width scaling ratio(relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training. [refer this issue](https://github.com/ultralytics/yolov5/issues/471#issuecomment-662009779)
+
+ +
+
+### 4.4 Build Targets
+Match positive samples:
+
+- Calculate the aspect ratio of GT and Anchor Templates
+
+
+
+
+
+)
+
+)
+
+)
+
+
+
+
+
+
+### 4.4 Build Targets
+Match positive samples:
+
+- Calculate the aspect ratio of GT and Anchor Templates
+
+
+
+
+
+)
+
+)
+
+)
+
+
+
+ +
+- Assign the successfully matched Anchor Templates to the corresponding cells
+
+
+
+- Assign the successfully matched Anchor Templates to the corresponding cells
+
+ +
+- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
+
+
+
+- Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.
+
+ +
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  +
+
+## Status
+
+
+
+
+## Status
+
+
 +
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+ +
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME=
+
+# Try out an Example!
+
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME= +
+You can preview the data directly in the Comet UI.
+
+
+You can preview the data directly in the Comet UI.
+ +
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+
+
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+ +
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet://
+
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet:// +
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://
+
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet:// diff --git a/docs/yolov5/ensemble.md b/docs/yolov5/ensemble.md
new file mode 100644
index 0000000..7303a0b
--- /dev/null
+++ b/docs/yolov5/ensemble.md
@@ -0,0 +1,137 @@
+📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
+UPDATED 25 September 2022.
+
+From [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):
+> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
+
+
+## Before You Start
+
+Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+## Test Normally
+
+Before ensembling we want to establish the baseline performance of a single model. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
+```bash
+python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
+```
+
+Output:
+```shell
+val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
+YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
+
+Fusing layers...
+Model Summary: 476 layers, 87730285 parameters, 0 gradients
+
+val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]
+val: New cache created: ../datasets/coco/val2017.cache
+ Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]
+ all 5000 36335 0.746 0.626 0.68 0.49
+Speed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed
+
+Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
+...
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826
+```
+
+## Ensemble Test
+
+Multiple pretrained models may be ensembled together at test and inference time by simply appending extra models to the `--weights` argument in any existing val.py or detect.py command. This example tests an ensemble of 2 models together:
+- YOLOv5x
+- YOLOv5l6
+
+```bash
+python val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half
+```
+
+Output:
+```shell
+val: data=./data/coco.yaml, weights=['yolov5x.pt', 'yolov5l6.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
+YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
+
+Fusing layers...
+Model Summary: 476 layers, 87730285 parameters, 0 gradients # Model 1
+Fusing layers...
+Model Summary: 501 layers, 77218620 parameters, 0 gradients # Model 2
+Ensemble created with ['yolov5x.pt', 'yolov5l6.pt'] # Ensemble notice
+
+val: Scanning '../datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:00<00:00, 49695545.02it/s]
+ Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [03:58<00:00, 1.52s/it]
+ all 5000 36335 0.747 0.637 0.692 0.502
+Speed: 0.1ms pre-process, 39.5ms inference, 2.0ms NMS per image at shape (32, 3, 640, 640) # <--- ensemble speed
+
+Evaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...
+...
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.515 # <--- ensemble mAP
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.699
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.557
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.356
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.563
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.668
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.387
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.638
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.689 # <--- ensemble mAR
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.743
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.844
+```
+
+## Ensemble Inference
+
+Append extra models to the `--weights` argument to run ensemble inference:
+```bash
+python detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images
+```
+
+Output:
+```bash
+detect: weights=['yolov5x.pt', 'yolov5l6.pt'], source=data/images, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
+YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
+
+Fusing layers...
+Model Summary: 476 layers, 87730285 parameters, 0 gradients
+Fusing layers...
+Model Summary: 501 layers, 77218620 parameters, 0 gradients
+Ensemble created with ['yolov5x.pt', 'yolov5l6.pt']
+
+image 1/2 /content/yolov5/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 tie, Done. (0.063s)
+image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.056s)
+Results saved to runs/detect/exp2
+Done. (0.223s)
+```
+
diff --git a/docs/yolov5/ensemble.md b/docs/yolov5/ensemble.md
new file mode 100644
index 0000000..7303a0b
--- /dev/null
+++ b/docs/yolov5/ensemble.md
@@ -0,0 +1,137 @@
+📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
+UPDATED 25 September 2022.
+
+From [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):
+> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
+
+
+## Before You Start
+
+Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.7.0**](https://www.python.org/) environment, including [**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
+
+```bash
+git clone https://github.com/ultralytics/yolov5 # clone
+cd yolov5
+pip install -r requirements.txt # install
+```
+
+## Test Normally
+
+Before ensembling we want to establish the baseline performance of a single model. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. `yolov5x.pt` is the largest and most accurate model available. Other options are `yolov5s.pt`, `yolov5m.pt` and `yolov5l.pt`, or you own checkpoint from training a custom dataset `./weights/best.pt`. For details on all available models please see our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints).
+```bash
+python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
+```
+
+Output:
+```shell
+val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
+YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
+
+Fusing layers...
+Model Summary: 476 layers, 87730285 parameters, 0 gradients
+
+val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]
+val: New cache created: ../datasets/coco/val2017.cache
+ Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [02:30<00:00, 1.05it/s]
+ all 5000 36335 0.746 0.626 0.68 0.49
+Speed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed
+
+Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
+...
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826
+```
+
+## Ensemble Test
+
+Multiple pretrained models may be ensembled together at test and inference time by simply appending extra models to the `--weights` argument in any existing val.py or detect.py command. This example tests an ensemble of 2 models together:
+- YOLOv5x
+- YOLOv5l6
+
+```bash
+python val.py --weights yolov5x.pt yolov5l6.pt --data coco.yaml --img 640 --half
+```
+
+Output:
+```shell
+val: data=./data/coco.yaml, weights=['yolov5x.pt', 'yolov5l6.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
+YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
+
+Fusing layers...
+Model Summary: 476 layers, 87730285 parameters, 0 gradients # Model 1
+Fusing layers...
+Model Summary: 501 layers, 77218620 parameters, 0 gradients # Model 2
+Ensemble created with ['yolov5x.pt', 'yolov5l6.pt'] # Ensemble notice
+
+val: Scanning '../datasets/coco/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:00<00:00, 49695545.02it/s]
+ Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 157/157 [03:58<00:00, 1.52s/it]
+ all 5000 36335 0.747 0.637 0.692 0.502
+Speed: 0.1ms pre-process, 39.5ms inference, 2.0ms NMS per image at shape (32, 3, 640, 640) # <--- ensemble speed
+
+Evaluating pycocotools mAP... saving runs/val/exp3/yolov5x_predictions.json...
+...
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.515 # <--- ensemble mAP
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.699
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.557
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.356
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.563
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.668
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.387
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.638
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.689 # <--- ensemble mAR
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.526
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.743
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.844
+```
+
+## Ensemble Inference
+
+Append extra models to the `--weights` argument to run ensemble inference:
+```bash
+python detect.py --weights yolov5x.pt yolov5l6.pt --img 640 --source data/images
+```
+
+Output:
+```bash
+detect: weights=['yolov5x.pt', 'yolov5l6.pt'], source=data/images, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
+YOLOv5 🚀 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
+
+Fusing layers...
+Model Summary: 476 layers, 87730285 parameters, 0 gradients
+Fusing layers...
+Model Summary: 501 layers, 77218620 parameters, 0 gradients
+Ensemble created with ['yolov5x.pt', 'yolov5l6.pt']
+
+image 1/2 /content/yolov5/data/images/bus.jpg: 640x512 4 persons, 1 bus, 1 tie, Done. (0.063s)
+image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 3 persons, 2 ties, Done. (0.056s)
+Results saved to runs/detect/exp2
+Done. (0.223s)
+```
+ +
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
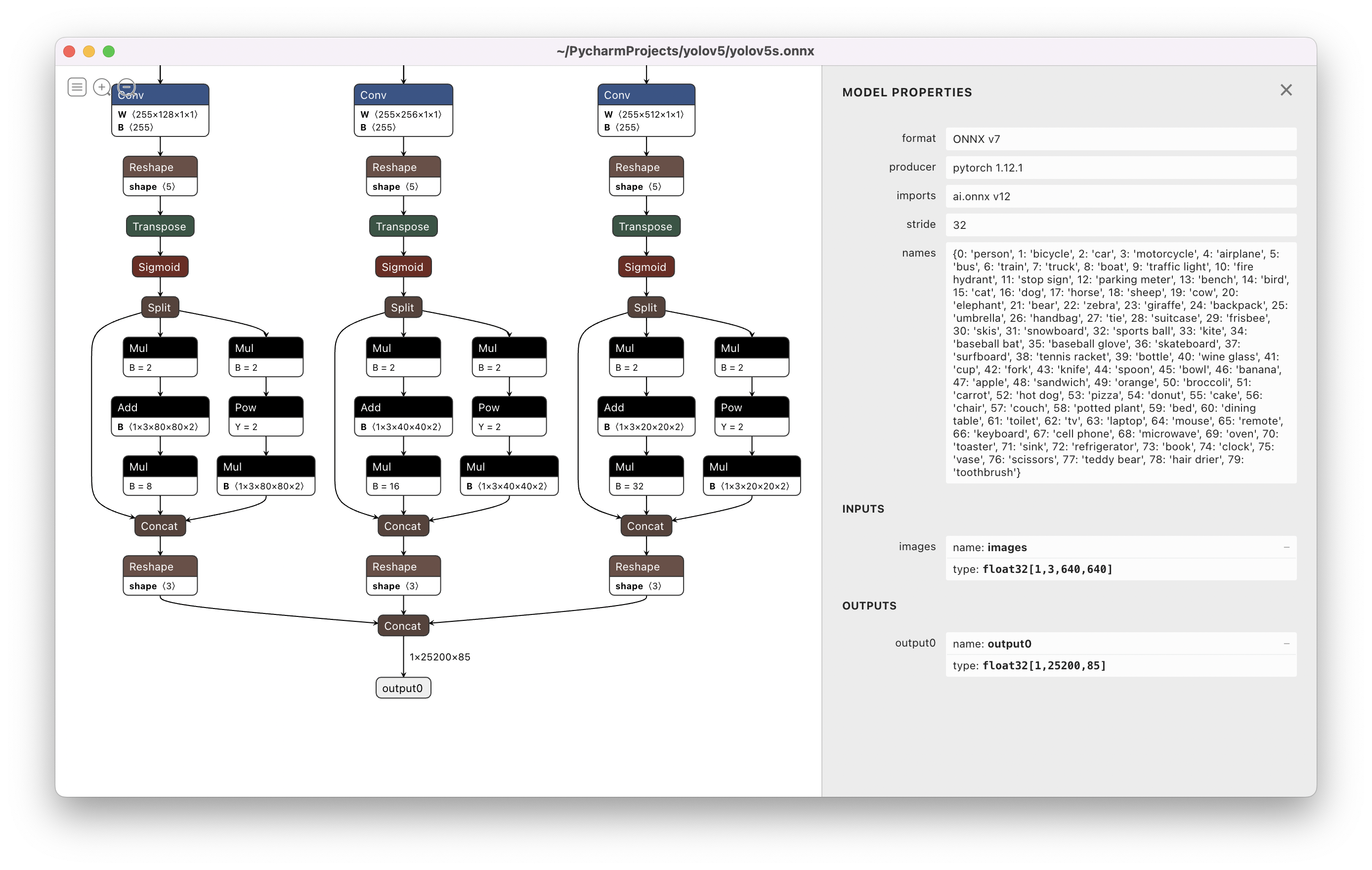
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+  +
+
+
+
+- **Google Cloud** Deep Learning VM.
+ See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**.
+ See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+## Status
+
+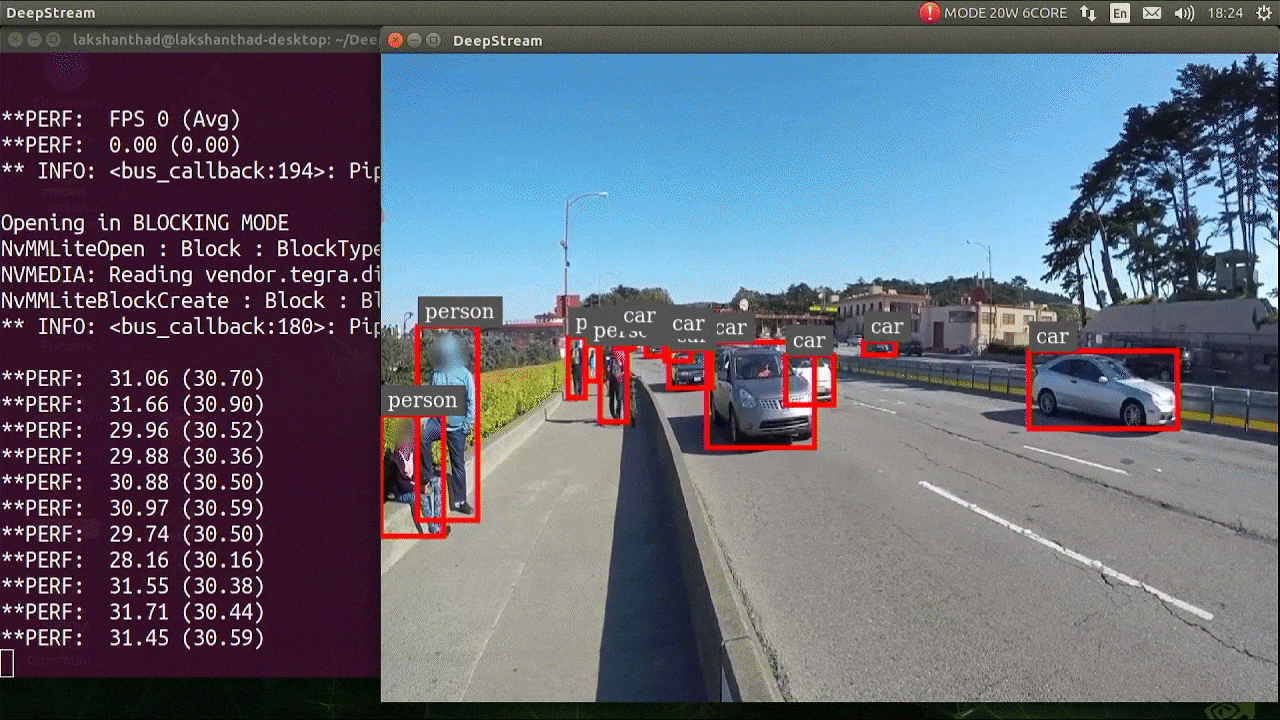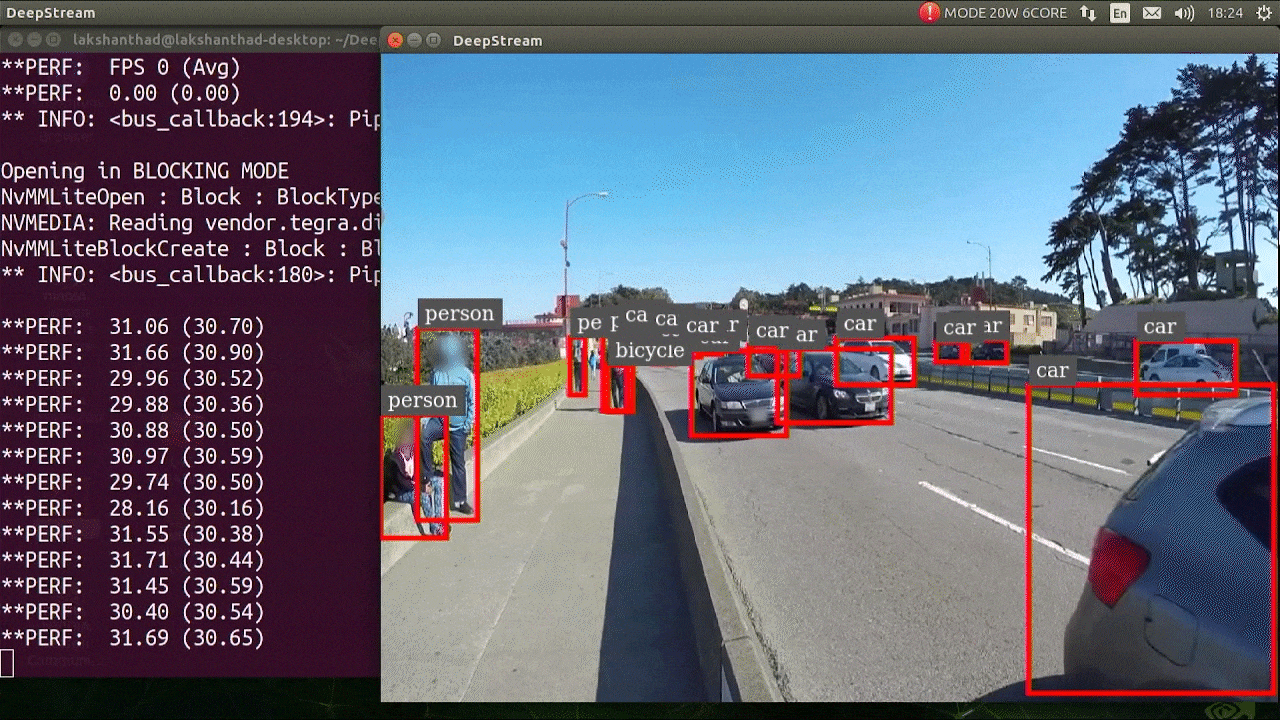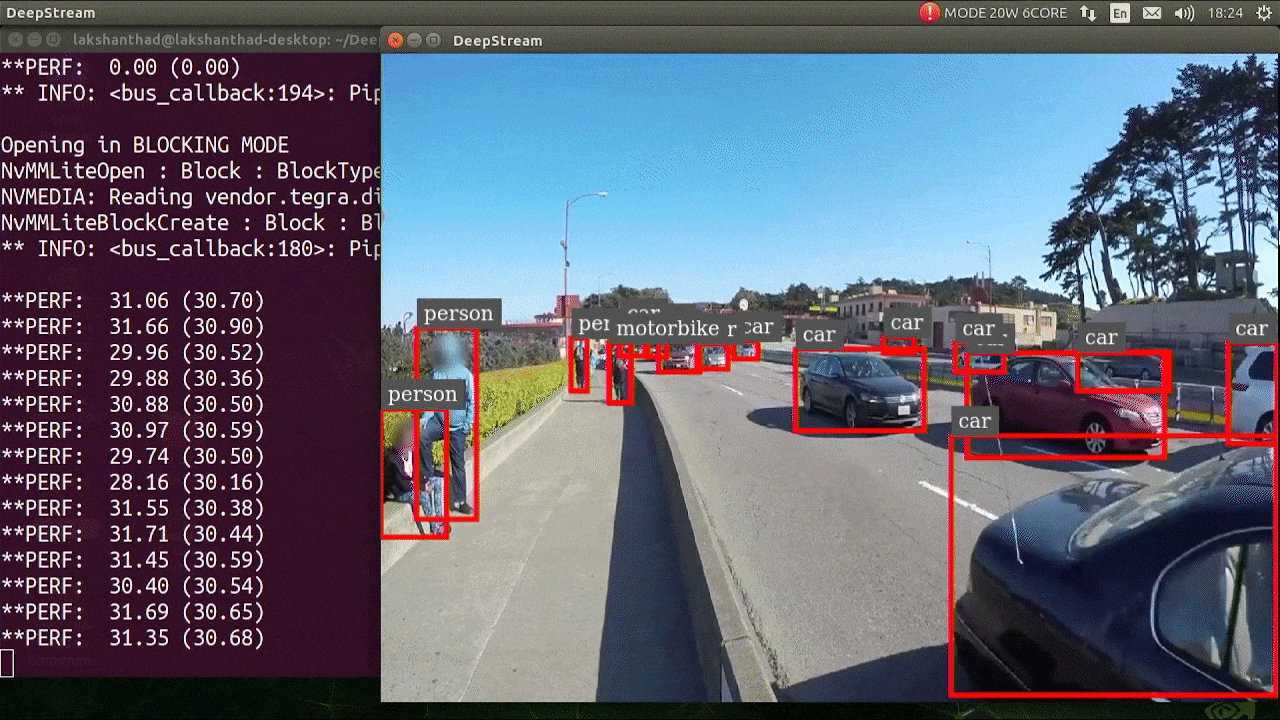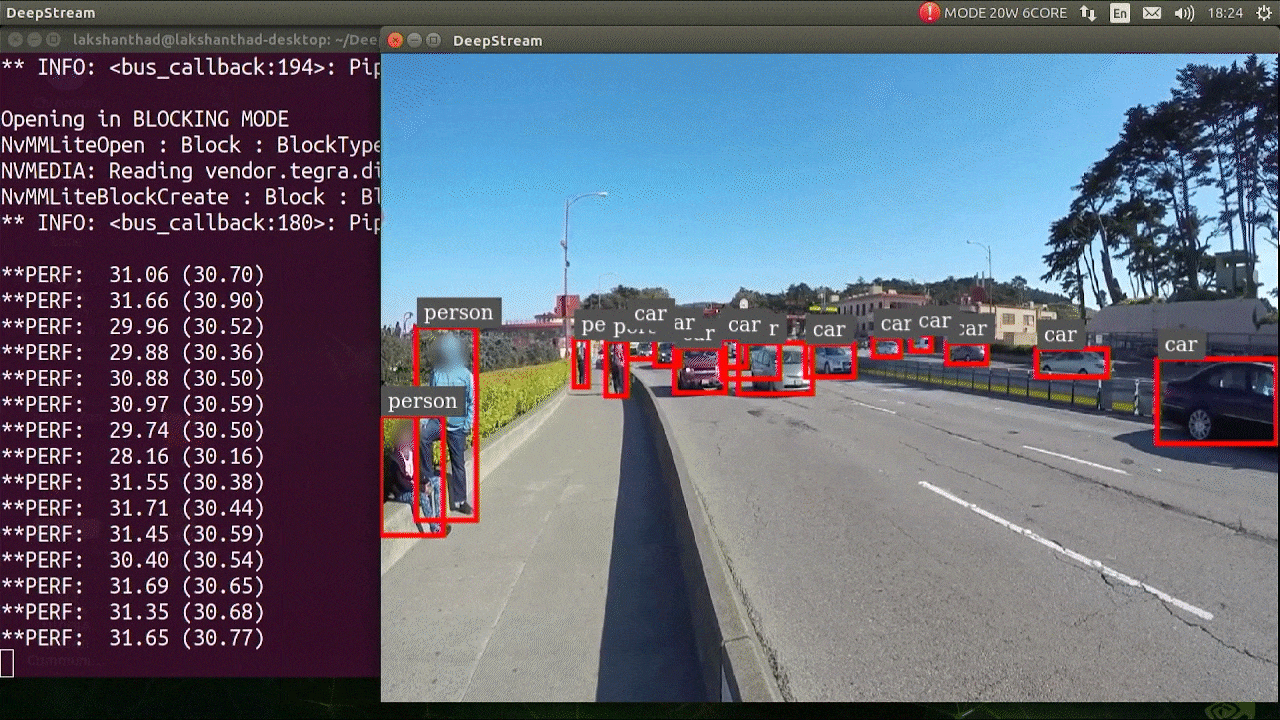
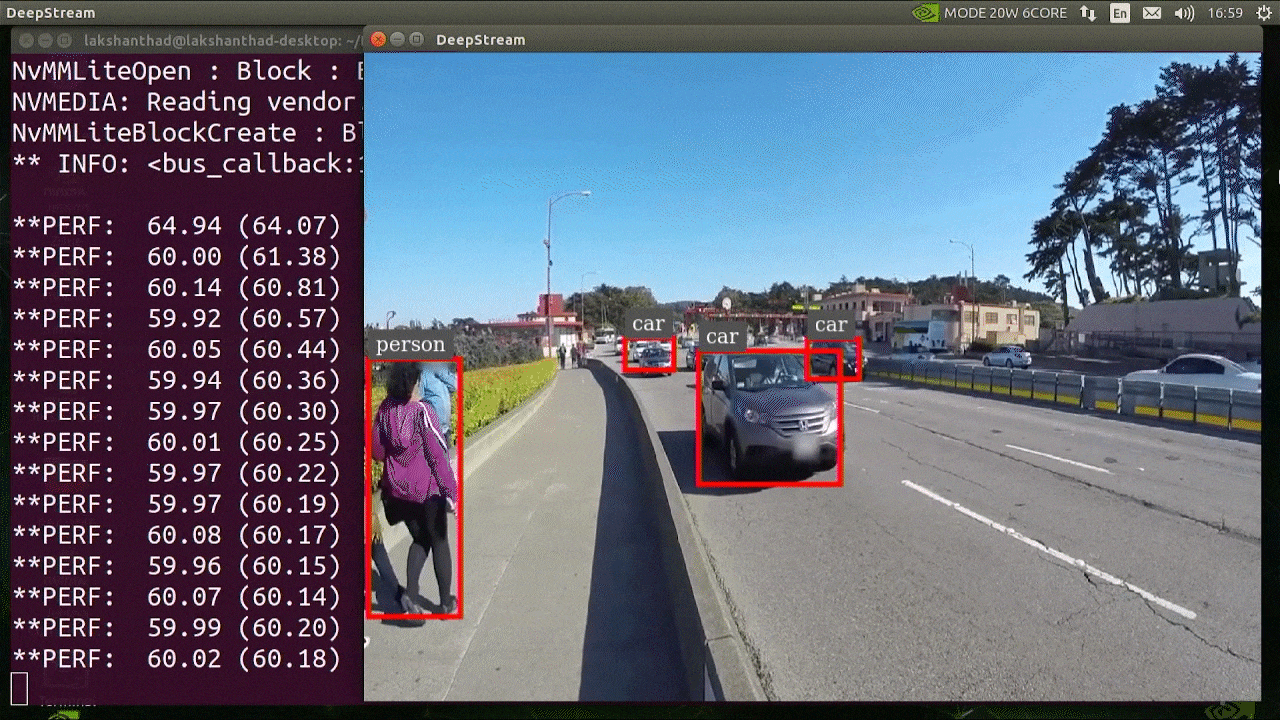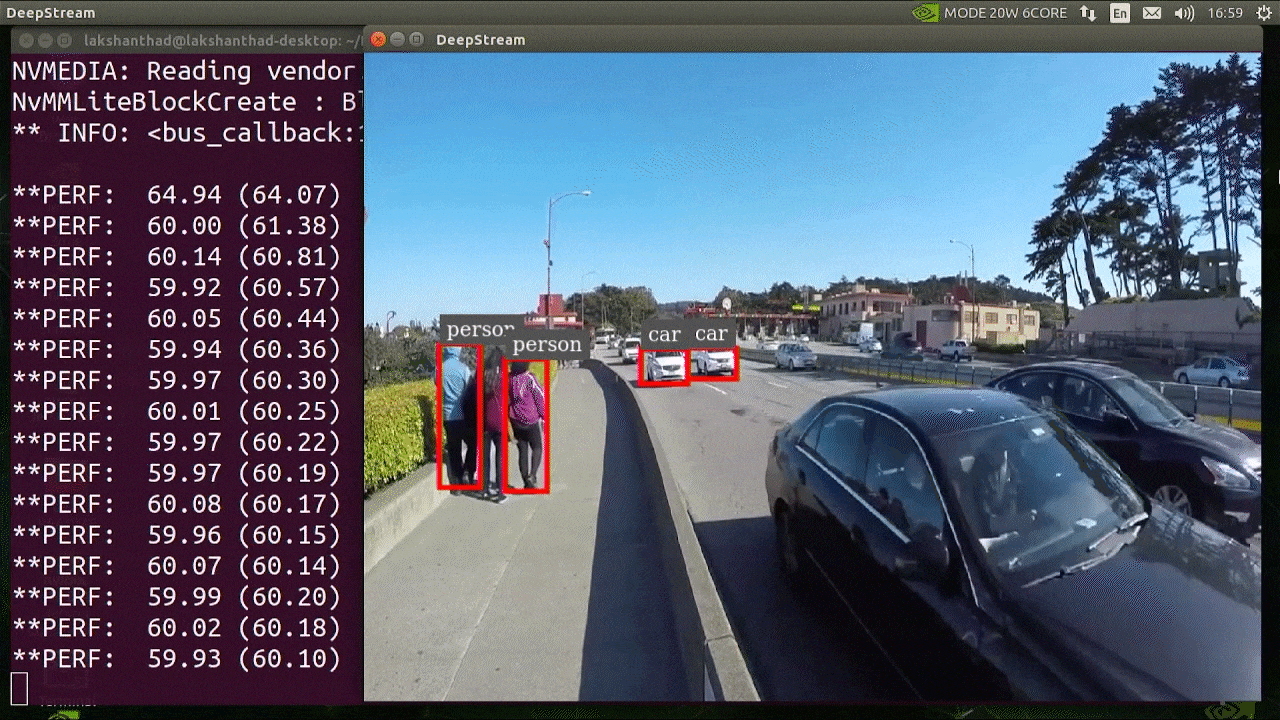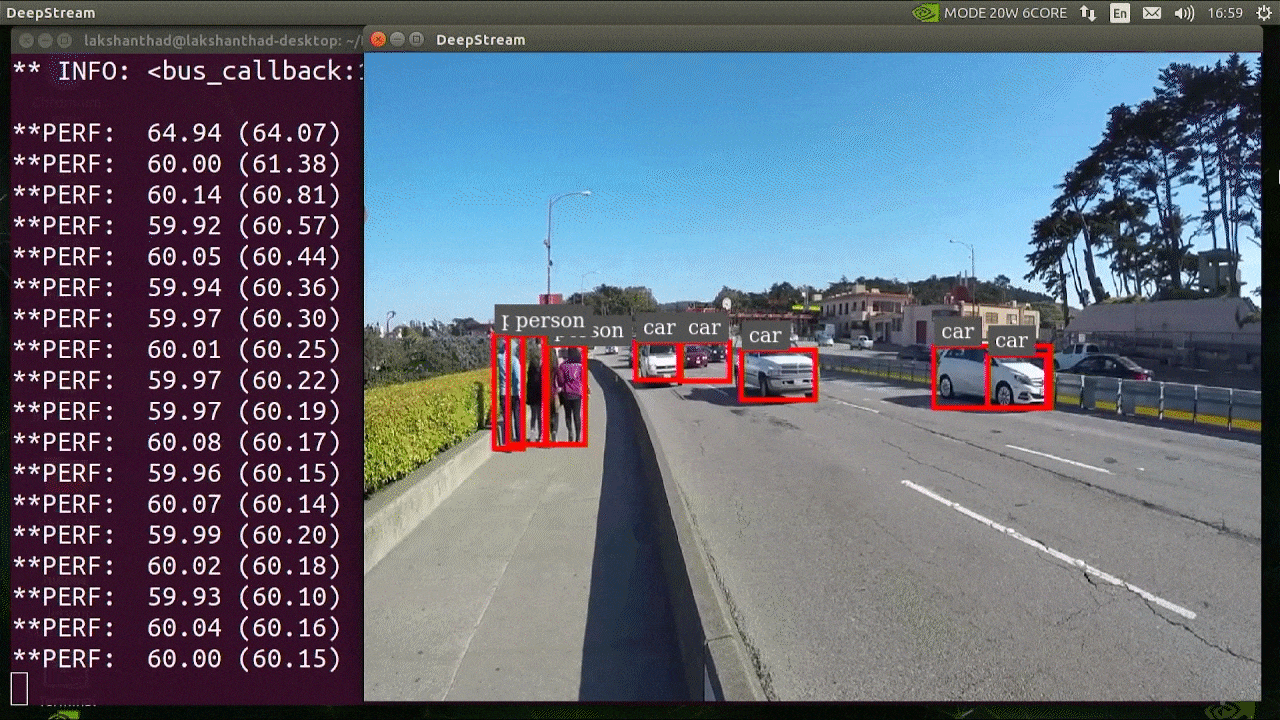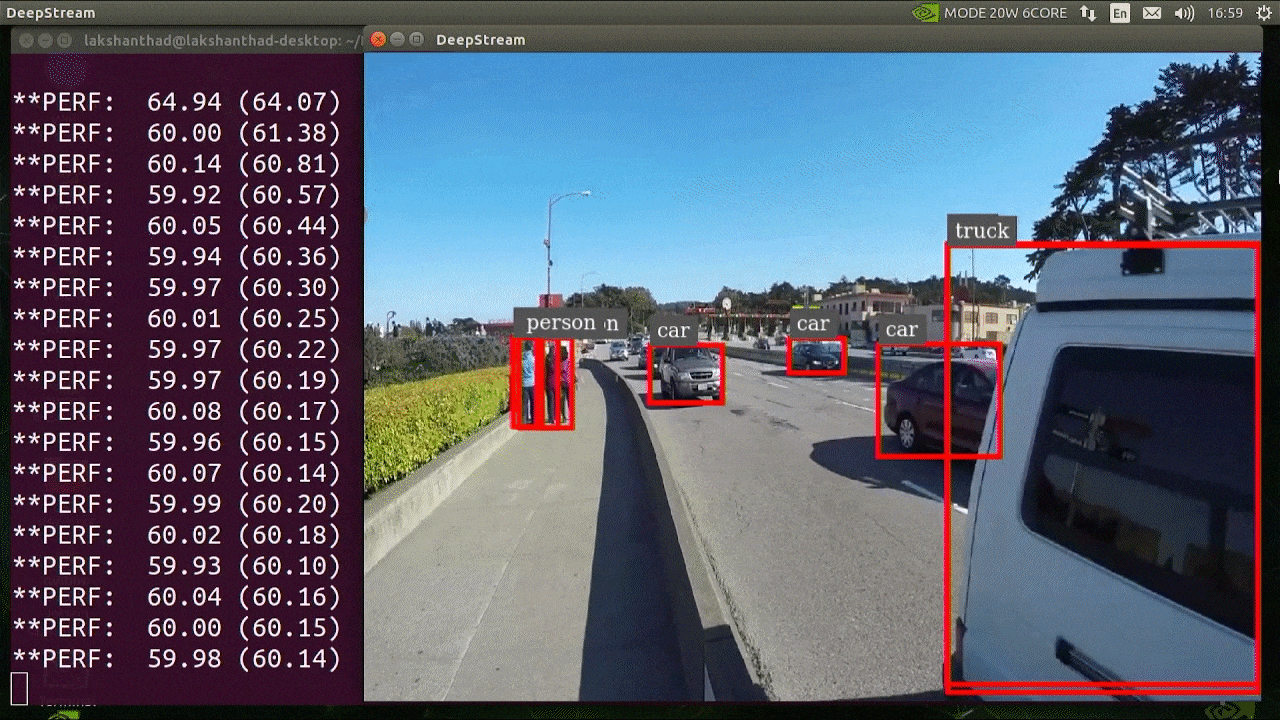 +
+💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **PyTorch>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.
+
+## Training
+
+Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.
+
+
+
+💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **PyTorch>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.
+
+## Training
+
+Select a pretrained model to start training from. Here we select [YOLOv5s](https://github.com/ultralytics/yolov5/blob/master/models/yolov5s.yaml), the smallest and fastest model available. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models. We will train this model with Multi-GPU on the [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset.
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+  +
+
+  +
+
+ +
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
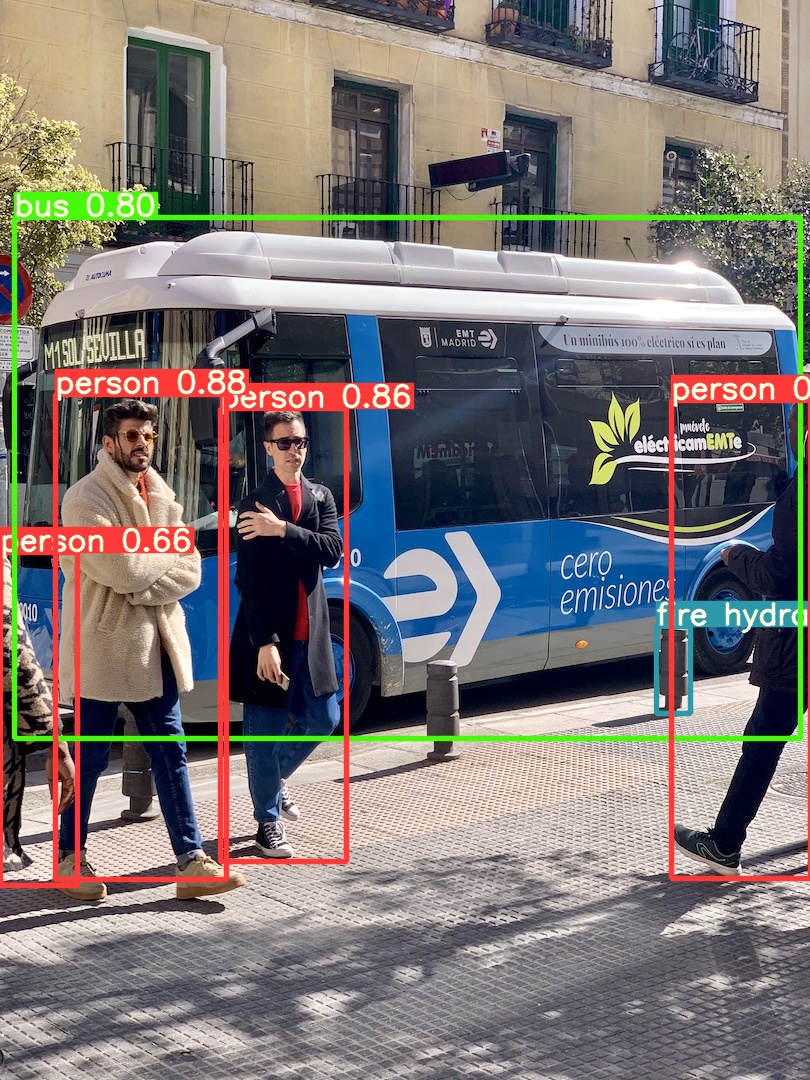 +
+For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
+
+### Inference Settings
+YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
+```python
+model.conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+results = model(im, size=320) # custom inference size
+```
+
+
+### Device
+Models can be transferred to any device after creation:
+```python
+model.cpu() # CPU
+model.cuda() # GPU
+model.to(device) # i.e. device=torch.device(0)
+```
+
+Models can also be created directly on any `device`:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
+```
+
+💡 ProTip: Input images are automatically transferred to the correct model device before inference.
+
+### Silence Outputs
+Models can be loaded silently with `_verbose=False`:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
+```
+
+### Input Channels
+To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
+```
+In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
+
+### Number of Classes
+To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
+```
+In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
+
+### Force Reload
+If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
+```
+
+### Screenshot Inference
+To run inference on your desktop screen:
+```python
+import torch
+from PIL import ImageGrab
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+
+# Image
+im = ImageGrab.grab() # take a screenshot
+
+# Inference
+results = model(im)
+```
+
+### Multi-GPU Inference
+
+YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
+
+```python
+import torch
+import threading
+
+def run(model, im):
+ results = model(im)
+ results.save()
+
+# Models
+model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
+model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
+
+# Inference
+threading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()
+threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()
+```
+
+### Training
+To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) for model training.
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
+```
+
+### Base64 Results
+For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
+```python
+results = model(im) # inference
+
+results.ims # array of original images (as np array) passed to model for inference
+results.render() # updates results.ims with boxes and labels
+for im in results.ims:
+ buffered = BytesIO()
+ im_base64 = Image.fromarray(im)
+ im_base64.save(buffered, format="JPEG")
+ print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
+```
+
+### Cropped Results
+Results can be returned and saved as detection crops:
+```python
+results = model(im) # inference
+crops = results.crop(save=True) # cropped detections dictionary
+```
+
+### Pandas Results
+Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
+```python
+results = model(im) # inference
+results.pandas().xyxy[0] # Pandas DataFrame
+```
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+For all inference options see YOLOv5 `AutoShape()` forward [method](https://github.com/ultralytics/yolov5/blob/30e4c4f09297b67afedf8b2bcd851833ddc9dead/models/common.py#L243-L252).
+
+### Inference Settings
+YOLOv5 models contain various inference attributes such as **confidence threshold**, **IoU threshold**, etc. which can be set by:
+```python
+model.conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ agnostic = False # NMS class-agnostic
+ multi_label = False # NMS multiple labels per box
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ max_det = 1000 # maximum number of detections per image
+ amp = False # Automatic Mixed Precision (AMP) inference
+
+results = model(im, size=320) # custom inference size
+```
+
+
+### Device
+Models can be transferred to any device after creation:
+```python
+model.cpu() # CPU
+model.cuda() # GPU
+model.to(device) # i.e. device=torch.device(0)
+```
+
+Models can also be created directly on any `device`:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', device='cpu') # load on CPU
+```
+
+💡 ProTip: Input images are automatically transferred to the correct model device before inference.
+
+### Silence Outputs
+Models can be loaded silently with `_verbose=False`:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', _verbose=False) # load silently
+```
+
+### Input Channels
+To load a pretrained YOLOv5s model with 4 input channels rather than the default 3:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
+```
+In this case the model will be composed of pretrained weights **except for** the very first input layer, which is no longer the same shape as the pretrained input layer. The input layer will remain initialized by random weights.
+
+### Number of Classes
+To load a pretrained YOLOv5s model with 10 output classes rather than the default 80:
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
+```
+In this case the model will be composed of pretrained weights **except for** the output layers, which are no longer the same shape as the pretrained output layers. The output layers will remain initialized by random weights.
+
+### Force Reload
+If you run into problems with the above steps, setting `force_reload=True` may help by discarding the existing cache and force a fresh download of the latest YOLOv5 version from PyTorch Hub.
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reload
+```
+
+### Screenshot Inference
+To run inference on your desktop screen:
+```python
+import torch
+from PIL import ImageGrab
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+
+# Image
+im = ImageGrab.grab() # take a screenshot
+
+# Inference
+results = model(im)
+```
+
+### Multi-GPU Inference
+
+YOLOv5 models can be loaded to multiple GPUs in parallel with threaded inference:
+
+```python
+import torch
+import threading
+
+def run(model, im):
+ results = model(im)
+ results.save()
+
+# Models
+model0 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=0)
+model1 = torch.hub.load('ultralytics/yolov5', 'yolov5s', device=1)
+
+# Inference
+threading.Thread(target=run, args=[model0, 'https://ultralytics.com/images/zidane.jpg'], daemon=True).start()
+threading.Thread(target=run, args=[model1, 'https://ultralytics.com/images/bus.jpg'], daemon=True).start()
+```
+
+### Training
+To load a YOLOv5 model for training rather than inference, set `autoshape=False`. To load a model with randomly initialized weights (to train from scratch) use `pretrained=False`. You must provide your own training script in this case. Alternatively see our YOLOv5 [Train Custom Data Tutorial](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) for model training.
+```python
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False) # load pretrained
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False) # load scratch
+```
+
+### Base64 Results
+For use with API services. See https://github.com/ultralytics/yolov5/pull/2291 and [Flask REST API](https://github.com/ultralytics/yolov5/tree/master/utils/flask_rest_api) example for details.
+```python
+results = model(im) # inference
+
+results.ims # array of original images (as np array) passed to model for inference
+results.render() # updates results.ims with boxes and labels
+for im in results.ims:
+ buffered = BytesIO()
+ im_base64 = Image.fromarray(im)
+ im_base64.save(buffered, format="JPEG")
+ print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
+```
+
+### Cropped Results
+Results can be returned and saved as detection crops:
+```python
+results = model(im) # inference
+crops = results.crop(save=True) # cropped detections dictionary
+```
+
+### Pandas Results
+Results can be returned as [Pandas DataFrames](https://pandas.pydata.org/):
+```python
+results = model(im) # inference
+results.pandas().xyxy[0] # Pandas DataFrame
+```
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
 +
+
+## Model Selection
+
+Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
+
+
+
+
+## Model Selection
+
+Larger models like YOLOv5x and [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/tag/v5.0) will produce better results in nearly all cases, but have more parameters, require more CUDA memory to train, and are slower to run. For **mobile** deployments we recommend YOLOv5s/m, for **cloud** deployments we recommend YOLOv5l/x. See our README [table](https://github.com/ultralytics/yolov5#pretrained-checkpoints) for a full comparison of all models.
+
+
 +
+






+
+### 4. Visualize
+
+#### Comet Logging and Visualization 🌟 NEW
+
+[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
+
+Getting started is easy:
+```shell
+pip install comet_ml # 1. install
+export COMET_API_KEY=
+
+#### ClearML Logging and Automation 🌟 NEW
+
+[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:
+
+- `pip install clearml`
+- run `clearml-init` to connect to a ClearML server (**deploy your own open-source server [here](https://github.com/allegroai/clearml-server)**, or use our free hosted server [here](https://cutt.ly/yolov5-notebook-clearml))
+
+You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).
+
+You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml) for details!
+
+
+ +
+
+#### Local Logging
+
+Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
+
+This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
+
+
+
+
+#### Local Logging
+
+Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
+
+This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
+
+ +
+Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+
+```python
+from utils.plots import plot_results
+plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
+```
+
+
+
+Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+
+```python
+from utils.plots import plot_results
+plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
+```
+
+
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+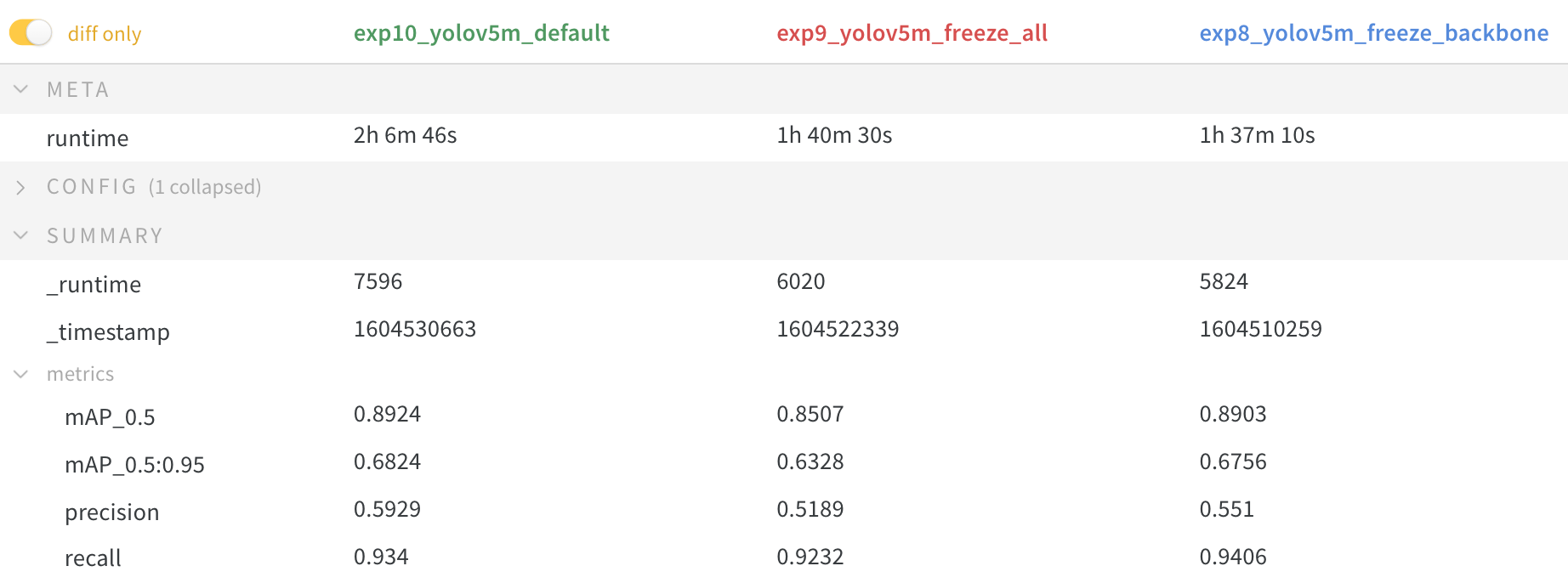 +
+### GPU Utilization Comparison
+
+Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
+
+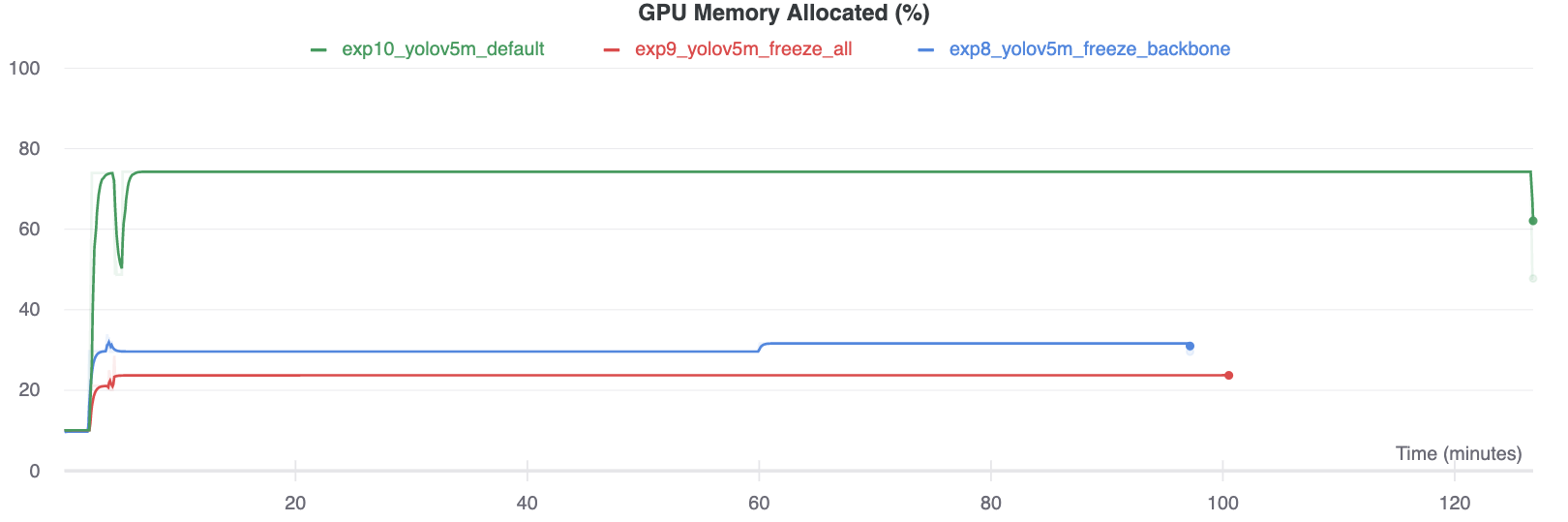
+
+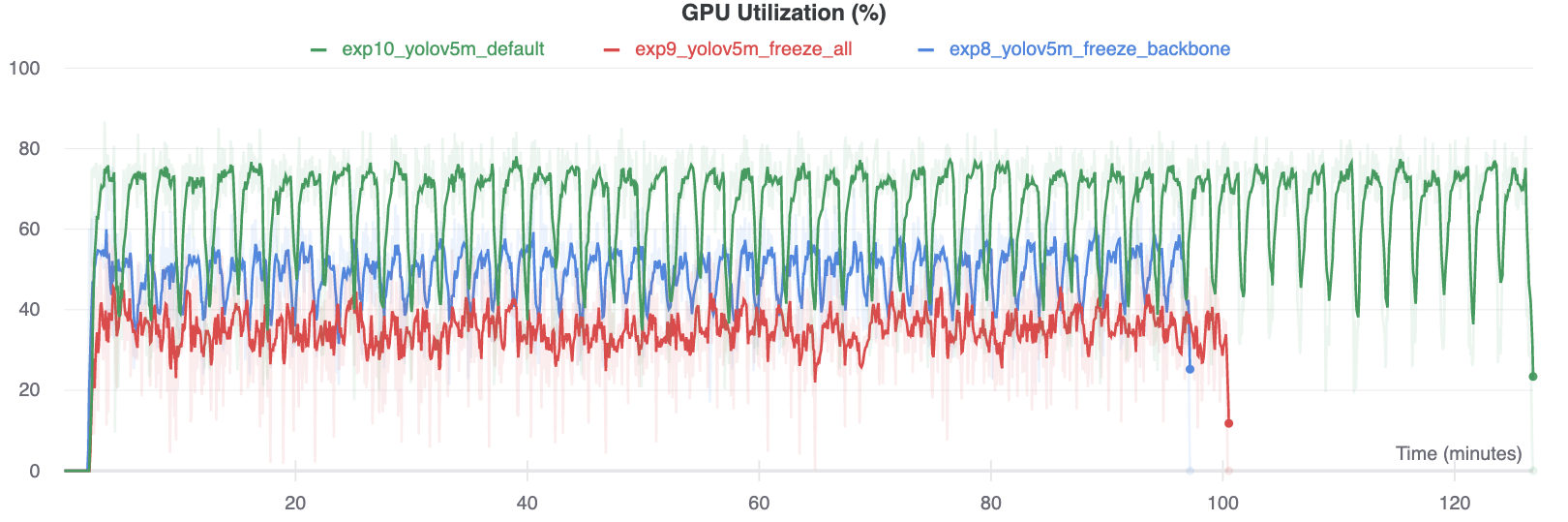
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+### GPU Utilization Comparison
+
+Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
+
+
+
+
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+ +
+
+### PyTorch Hub TTA
+
+TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.
+```python
+import torch
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
+
+# Images
+img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
+
+# Inference
+results = model(img, augment=True) # <--- TTA inference
+
+# Results
+results.print() # or .show(), .save(), .crop(), .pandas(), etc.
+```
+
+### Customize
+
+You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+
+### PyTorch Hub TTA
+
+TTA is automatically integrated into all [YOLOv5 PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5) models, and can be accessed by passing `augment=True` at inference time.
+```python
+import torch
+
+# Model
+model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
+
+# Images
+img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
+
+# Inference
+results = model(img, augment=True) # <--- TTA inference
+
+# Results
+results.print() # or .show(), .save(), .crop(), .pandas(), etc.
+```
+
+### Customize
+
+You can customize the TTA ops applied in the YOLOv5 `forward_augment()` method [here](https://github.com/ultralytics/yolov5/blob/8c6f9e15bfc0000d18b976a95b9d7c17d407ec91/models/yolo.py#L125-L137).
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Notebooks** with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+